浏览器缓存机制是由http协议定义的,浏览器是客户端用户接受并浏览服务端信息的窗口。客户端是否缓存服务端的资源,由服务端进行控制,服务端对客户端传递信息的载体便是响应头了。关于http是如果实现浏览器缓存的,我整理了一下我的思路:

图中圆圈1和2分别表示允许浏览器缓存前后的请求以及响应。
1.客户端第一次向服务端发送请求
客户端请求页面,缓存中并没有该服务器缓存的数据,因此客户端向服务端发送request报文。

服务端成功接受处理请求报文之后,获得服务端缓存的允许之后,返回200的成功状态码,并且在响应头上附上对当前资源以及缓存的一些信息:
Expires:在缓存器中的缓存的过期时间
Last-Modified: 资源最后修改的时间
Etag:指示资源状态唯一标识
客户端接收并保存信息,将文件缓存带cache目录下。
2.客户端第二次请求
客户端会首先在浏览器的缓存目录中查找是否存在相应的缓存文件:
如果找到相应的缓存文件,检查文件的expires,如果文件未过期,则直接从缓存中提取文件使用。
如果文件过期,则向服务器发送请求,并附带上以下信息:
If-Modified-Since 最近一次修改的时间
If-None-Match 上一次请求返回的Etag
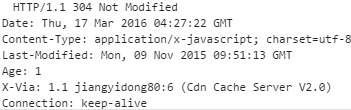
服务器接收到信息之后进行处理,如果服务器中的修改时间与最近一次修改的时间一致并且etag值不变,即缓存内容未被修改,返回304状态,通知客户端从缓存中提取文件。否则重新发送更改之后的资源。
综上,通过缓存机制将资源缓存在本地,极大程度的减少了网络带宽,压缩了网页的加载时间,加速浏览,提升了用户体验。
*文章如有疏漏不足之处,欢迎指正学习。