-------------------------------------------
--------------爬虫的思路-------------------
-------------------------------------------
先判断网页是否允许爬虫
(1)get_html()获取源码
1、不允许就加上headers头部信息,模拟用户访问
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36'}
2、请求进入网页
request = urllib2.Rwquest(url,headers = headers)
3、打开网页
response = urllib2.urlopen(request)
4、获取源码
text = response.read()
(2)get_Url()获取标题或者内容
1、进入网页寻找网页中我们寻找的内容部分
2、找到标题或者内容那一部分,通过正则表达式匹配该部分
pattern = re.compile('<a href="/story/(.*?)"',re.S)# re.S匹配换行符
3、在整个网页中匹配这个内容
items = re.findall(pattern,html)
4、打印出来
urls = []#多个页面,把每个页面的编码放到list中
for item in items:
urls.append('http://daily.zhihu.com/story/'+item)
#print urls[-1] #切片
return urls
5、调用显示
(3)多页的显示
1、看每页的网址的区别,一般是在后面加上+str(page)
2、然后分别调用每页的内容
(4)把获取的内容写到文件中保存
items = pattern.compile(patten,html)
with open('test.txt','w') as test:
for item in items:
test.write(item)#往文件中写内容
test.write("
")#换行
我们如果想爬取一个网页,那么就需要打开网页获取网页的源码,一般使用谷歌和火狐稍微好点,现在教你们怎样获取网页源码:
1、打开网页,在网页空白处右击选择查看网页源代码;
2、进入源代码查找你需要用到的信息,复制下来,然后用正则匹配下来,我们有个懒惰匹配(.*?)就是代表你要获取的内容,不需要可以用.*?代替,很长的数字可以用d+代替等等,具体的正则表达式看我之前的帖子http://www.cnblogs.com/zhangjiansheng/p/6853729.html,里面有详细描述。
比如下面这个例子:
<tr><td>1</td><td>989584027708</td><td>(香港地区)National_Bank_Abu_Dhabi</td><td>00852-341343660</td><td>18/F_Nine_Queens_Road_Central</td></tr>
<tr><td>d+</td><td>d+</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td></tr>

以上只是爬取没有反爬机制的网页。
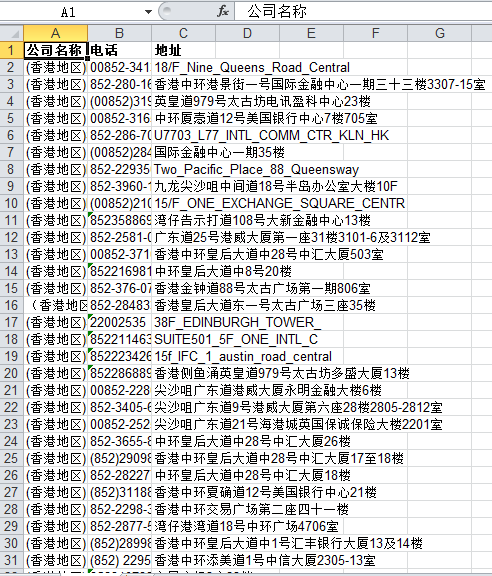
下面是用正则与urllib编写的一个爬虫,用来爬取http://furhr.com/,把所有的银行名称,联系电话,银行地址爬取下来,并把爬取到的内容放到Excel表格内,具体程序如下所示:
# -*- coding:utf-8 -*- __author__ = 'Demon' import xlwt#excel表格函数 import urllib,re def getdata(): url_list = [] for i in range(1,100): url = 'http://furhr.com/?page={}'.format(i)#多页调用 #print url try:#错误处理 html = urllib.urlopen(url).read()#打开网页获取源码 #print html except Exception as e: print e continue #正则表达式 获取想要获取的内容 page_list = re.findall(r"<tr><td>d+</td><td>d+</td><td>(.*?)</td><td>(.*?)</td><td>(.*?)</td></tr>",html) #print page_list url_list.append(page_list)#把匹配到的内容放到list里面 return url_list def excel_write(): newTable = 'test.xls'#新建一个excel表格并命名 wb = xlwt.Workbook(encoding='utf-8')#申明表格编码格式 ws = wb.add_sheet('test1')#增加表格单元 headData = ['公司名称','电话','地址']#写表头 for colnum in range(0,3): ws.write(0,colnum,headData[colnum],xlwt.easyxf('font: bold on')) #把表头写在第0行,0,1,2这三列,并把字体设置为加粗 index = 1 for item in items:#把数据写到表格里面 for j in range(0,len(item)): for i in range(0,3): # print item[j] print item[j][i] ws.write(index,i,item[j][i]) index +=1 wb.save(newTable) if __name__ == "__main__":#判断函数入口 items = getdata()#调用网页源码获取函数 excel_write()#调取Excel函数,把数据放在Excel中
爬取的结果如下图所示: