1.集群安装es
ES内部索引原理:
1.1 环境
域名 ip master 192.168.0.120 slave1 192.168.0.121 slave2 192.168.0.122
1.2 三台机器都安装jdk最新版本
[root@master ~]$ java -version java version "1.8.0_171" Java(TM) SE Runtime Environment (build 1.8.0_171-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode) [root@slave1 ~]$ java -version java version "1.8.0_171" Java(TM) SE Runtime Environment (build 1.8.0_171-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode) [root@slave2 ~]$ java -version java version "1.8.0_171" Java(TM) SE Runtime Environment (build 1.8.0_171-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
1.3 三台机器都统一用户为spark
[root@master ~]# useradd spark You have new mail in /var/spool/mail/root [root@master ~]# passwd spark # 密码为 spark Changing password for user spark. New password: BAD PASSWORD: it is based on a dictionary word BAD PASSWORD: is too simple Retype new password: passwd: all authentication tokens updated succsparksfully. [root@master ~]# mkdir /home/spark mkdir: cannot create directory `/home/spark': File exists [root@master ~]# ll /home/ # 注意是不是spark用户和用户组 total 0 drwxrwxr-x 2 spark spark 4096 Feb 25 03:59 spark [root@master ~]# [root@slave1 ~]# useradd spark [root@slave1 ~]# passwd spark # 密码为 spark [root@slave1 ~]# mkdir /home/spark [root@slave1 ~]# ll /home/ # 注意是不是spark用户和用户组 [root@slave2 ~]# useradd spark [root@slave2 ~]# passwd spark # 密码为 spark [root@slave2 ~]# mkdir /home/spark [root@slave2 ~]# ll /home/ # 注意是不是spark用户和用户组
1.4 使用spark用户,在三台机器都建立/opt/elasticsearch-6.2.2目录,用来存放es软件包和数据存储
[root@master ~]# su spark [spark@master root]# cd /opt/ [spark@master ~]$ sudo mkdir elasticsearch-6.2.2 [spark@master ~]$ ll drwxrwxr-x 2 root root 4096 Feb 25 03:59 elasticsearch-6.2.2 [spark@master ~]$
其余两台此处省略
1.5 三台机器都解压安装包到/opt/elasticsearch-6.2.2
下载:https://www.elastic.co/cn/downloads/elasticsearch
包:elasticsearch-6.2.2.zip
下载地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.2.zip
[spark@master opt]$ sudo unzip elasticsearch-6.2.2.zip Archive: elasticsearch-6.2.2.zip creating: elasticsearch-6.2.2/lib/ 。。。 inflating: elasticsearch-6.2.2/modules/lang-expression/lang-expression-6.2.2.jar creating: elasticsearch-6.2.2/plugins/ creating: elasticsearch-6.2.2/logs/ [spark@master opt]$
1.6 三台机器都修改es软件包的权限为spark用户
因为我是root解压的
master(192.168.0.120)
[spark@master opt]$ ll total 839080 drwxr-xr-x. 8 root root 143 Jul 18 04:22 elasticsearch-6.2.2
slave1(192.168.0.121)
[spark@slave1 opt]$ ll total 276116 drwxr-xr-x. 2 root root 6 Jul 18 04:25 elasticsearch-6.2.2
slave2(192.168.0.122)
[spark@slave2 opt]$ ll total 211824 drwxr-xr-x. 2 root root 6 Jul 18 04:25 elasticsearch-6.2.2
使用root用户修改权限
[spark@master opt]$ su root Password: [root@master opt]# chown -R spark:spark /opt/elasticsearch-6.2.2 [root@master opt]# ll total 839080 drwxr-xr-x. 8 spark spark 143 Jul 18 04:22 elasticsearch-6.2.2
其余两台此处省略
1.7 三台机器都创建data数据目录和日志目录,使用spark用户
[root@master opt]$ su spark [spark@master opt]$ mkdir -p /opt/elasticsearch-6.2.2/data/ [spark@master opt]$ [spark@master opt]$ mkdir -p /opt/elasticsearch-6.2.2/logs/ [spark@master opt]$ [spark@master opt]$ cd elasticsearch-6.2.2 [spark@master elasticsearch-6.2.2]$ ls bin config data lib LICENSE.txt logs modules NOTICE.txt plugins README.textile
到这里,如果你其他服务器还下载解压es,可以使用scp拷贝到其他服务器上:
[spark@master opt]$ scp -r /opt/elasticsearch-6.2.2 spark@slave1:/opt/ [spark@master opt]$ scp -r /opt/elasticsearch-6.2.2 spark@slave2:/opt/
其余两台此处省略
1.8 三台机器都修改配置
191.168.0.120机器配置
vim /opt/elasticsearch-6.2.2/config/elasticsearch.yml cluster.name: es-application node.name: node-192-168-0-120 path.data: /opt/elasticsearch-6.2.2/data/ path.logs: /opt/elasticsearch-6.2.2/logs/ bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.unicast.hosts: ["192.168.0.120", "192.168.0.121", "192.168.0.122"] discovery.zen.minimum_master_nodes: 3 http.cors.enabled: true http.cors.allow-origin: "*"
191.168.0.121机器配置
vim /opt/elasticsearch-6.2.2/config/elasticsearch.yml cluster.name: es-application node.name: node-192-168-0-121 path.data: /opt/elasticsearch-6.2.2/data/ path.logs: /opt/elasticsearch-6.2.2/logs/ bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.unicast.hosts: ["192.168.0.120", "192.168.0.121", "192.168.0.122"] discovery.zen.minimum_master_nodes: 3 http.cors.enabled: true http.cors.allow-origin: "*"
191.168.0.122机器配置
vim /opt/elasticsearch-6.2.2/config/elasticsearch.yml cluster.name: es-application node.name: node-192-168-0-122 path.data: /opt/elasticsearch-6.2.2/data/ path.logs: /opt/elasticsearch-6.2.2/logs/ bootstrap.memory_lock: false bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.unicast.hosts: ["192.168.0.120", "192.168.0.121", "192.168.0.122"] discovery.zen.minimum_master_nodes: 3 http.cors.enabled: true http.cors.allow-origin: "*"
1.9 三台机器都修改 Linux下/etc/security/limits.conf文件设置
更改linux的最大文件描述限制要求
添加或修改如下:
* soft nofile 262144
* hard nofile 262144
更改linux的锁内存限制要求
添加或修改如下:
用户(spark) soft memlock unlimited
用户(spark) hard memlock unlimited
最后配置如下
sudo vim /etc/security/limits.conf * soft nofile 262144 * hard nofile 262144 spark soft memlock unlimited spark hard memlock unlimited
1.10 三台机器都修改配置 Linux下/etc/security/limits.d/*-nproc.conf文件设置
更改linux的最大线程数,添加或修改如下:
* soft nproc unlimited
[spark@master opt]$ cd /etc/security/limits.d [spark@master limits.d]$ ls 20-nproc.conf [spark@master limits.d]$ more 20-nproc.conf # Default limit for number of user's processes to prevent # accidental fork bombs. # See rhbz #432903 for reasoning. * soft nproc 4096 root soft nproc unlimited [spark@master limits.d]$ sudo vi /etc/security/limits.d/20-nproc.conf # Default limit for number of user's processes to prevent # accidental fork bombs. # See rhbz #432903 for reasoning. * soft nproc unlimited root soft nproc unlimited ~ ~
其余两台此处省略
1.11 三台机器都修改配置 Linux下/etc/sysctl.conf文件设置
更改linux一个进行能拥有的最多的内存区域要求,添加或修改如下:
vm.max_map_count = 262144
更改linux禁用swapping,添加或修改如下:
vm.swappiness = 1
配置后如下:
sudo vim /etc/sysctl.conf vm.max_map_count = 262144 vm.swappiness = 1
1.12 三台机器都启动
[spark@master elasticsearch-6.2.2]$ bin/elasticsearch [spark@slave1 elasticsearch-6.2.2]$ bin/elasticsearch [spark@slave2 elasticsearch-6.2.2]$ bin/elasticsearch
备注:启动过程中如果三台服务器都未完全启动,会抛出警告等,等到三台服务器的es启动完警告就会消失。
安装完后,验证是否安装启动es成功
访问:
http://192.168.0.120:9200/
http://192.168.0.121:9200/
http://192.168.0.122:9200/ 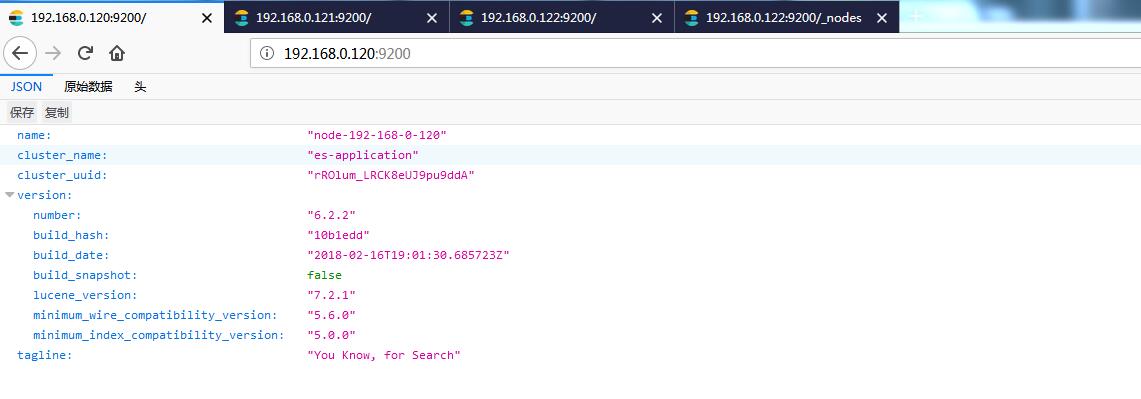
http://192.168.0.120:9200/_nodes/
http://192.168.0.121:9200/_nodes/
http://192.168.0.122:9200/_nodes/
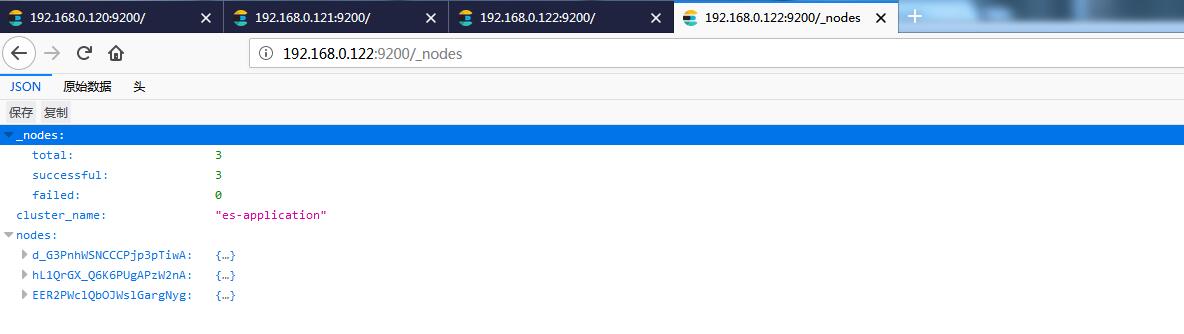
2 安装Head插件
ElasticSearch-Head 是一个与Elastic集群(Cluster)相交互的Web前台。
三台机器只需要一台安装head就可以了
ES-Head的主要作用:
- 它展现ES集群的拓扑结构,并且可以通过它来进行索引(Index)和节点(Node)级别的操作
- 它提供一组针对集群的查询API,并将结果以json和表格形式返回
- 它提供一些快捷菜单,用以展现集群的各种状态
5.x以后的版本安装Head插件比较麻烦,不能像2.x的时候一条#elasticsearch/bin/plugin install mobz/elasticsearch-head #一波搞定
2.1 安装Node.js
由于head插件本质上还是一个nodejs的工程,因此需要安装node,使用npm来安装依赖的包。(npm可以理解为maven),官网nodejs,https://nodejs.org/en/download/
下载nodejs安装包:
[spark@master ~]#cd /opt/ [spark@master opt]#sudo yum install wget #没有安装wget的话,安装wget [spark@master opt]#sudo wget https://nodejs.org/dist/v8.9.1/node-v8.9.1.tar.gz #新版要编译时间太长了用旧版本吧 [spark@master opt]#sudo tar -zxvf node-v8.9.1.tar.gz [spark@master opt]# ll drwxr-xr-x. 9 502 games 4096 Nov 8 2017 node-v8.9.1 -rw-r--r--. 1 root root 31097804 Nov 8 2017 node-v8.9.1.tar.gz [spark@master opt]$ sudo chown -R spark:spark /opt/node-v8.9.1 [spark@master opt]$ ll total 869456 drwxr-xr-x. 9 spark spark 4096 Nov 8 2017 node-v8.9.1 -rw-r--r--. 1 root root 31097804 Nov 8 2017 node-v8.9.1.tar.gz
编译安装nodejs:sudo ./configure --prefix=/opt/node-8.9.1 && make -j 8 && make install
[spark@master opt]$ cd /opt/node-v8.9.1 [spark@master node-v8.9.1]$ sudo ./configure --prefix=/opt/node-8.9.1 && make -j 8 && make install #安装时间比较长,没办法,Centos7的系统要最新版本的nodejs。 WARNING: failed to autodetect C++ compiler version (CXX=g++) WARNING: failed to autodetect C compiler version (CC=gcc) Node.js configure error: No acceptable C compiler found! Please make sure you have a C compiler installed on your system and/or consider adjusting the CC environment variable if you installed it in a non-standard prefix. Makefile:95: *** Missing or stale config.gypi, please run ./configure. Stop.
上边安装抛出错误,原因:需要安装gcc-c++。接下来安装gcc-c++
[spark@master node-v8.9.1]$ sudo yum install gcc-c++ //安装gcc Loaded plugins: fastestmirror 。。。 Complete!
重新开始编译安装nodejs:
[root@master opt]$ cd /opt/node-v8.9.1 [root@master node-v8.9.1]$ sudo ./configure --prefix=/opt/node-v8.9.1 && make -j 8 && make install #安装时间比较长,没办法,Centos7的系统要最新版本的nodejs。
配置PATH,并验证:
# vim /etc/profile #/etc/profile中添加nodejs环境变量。 export NODE_HOME=/opt/node-8.9.1 export PATH=$PATH:$NODE_HOME/bin
# source /etc/profile # node -v v8.9.1 # npm -v
2.2 下载插件包 npm install -g grunt-cli
grunt是一个很方便的构建工具,可以进行打包压缩、测试、执行等等的工作
[spark@master ~]$ [spark@master ~]# npm install -g grunt-cli /opt/node-8.9.1/bin/grunt -> /opt/node-8.9.1/lib/node_modules/grunt-cli/bin/grunt + grunt-cli@1.2.0 updated 1 package in 8.179s
注意:使用spark用户安装出现权限问题时,修改/opt/node-8.9.1/的权限:
chown -R spark:spark /opt/node-8.9.1/
2.3 下载 elasticsearch-head 或者 git clone 到本地
这里采用直接下载从:https://github.com/mobz/elasticsearch-head
上传到master
[spark@master opt]$ sudo unzip elasticsearch-head-master.zip [spark@master opt]$ ll drwxr-xr-x. 6 root root 4096 Sep 15 2017 elasticsearch-head-master -rw-r--r--. 1 root root 921421 Jul 17 23:16 elasticsearch-head-master.zip [spark@master elasticsearch-head-master]# chown -R spark:spark /opt/elasticsearch-head-master/ # 注意分配权限
进入 elasticsearch-head-master目录,进行安装:
如果你的网速较快,可以使用这个命令,推荐使用后面一个命令
npm install # 容易失败,建议使用后边的
使用国内镜像
npm install -g cnpm --registry=https://registry.npm.taobao.org
2.4 修改Elasticsearch配置文件
vim elasticsearch-6.2.2/config/elasticsearch.yml
加入以下内容:
http.cors.enabled: true http.cors.allow-origin: "*"
2.5 修改Gruntfile.js
修改 elasticsearch-head-master/Gruntfile.js,在connect属性中,增加hostname: ‘0.0.0.0’
cd elasticsearch-head-master/ vim Gruntfile.js
修改为
connect: { server: { options: { hostname: '0.0.0.0', port: 9100, base: '.', keepalive: true } } }
2.6 启动 elasticsearch-head
进入elasticsearch-head-master目录
cd /opt/elasticsearch-head-master
#执行
grunt server
#输出
>> Local Npm module "grunt-contrib-jasmine" not found. Is it installed? Running "connect:server" (connect) task Waiting forever... Started connect web server on http://localhost:9100
浏览器访问
启动es
[spark@master elasticsearch-6.2.2]$ bin/elasticsearch [spark@slave1 elasticsearch-6.2.2]$ bin/elasticsearch [spark@slave2 elasticsearch-6.2.2]$ bin/elasticsearch
访问http://192.168.0.120:9100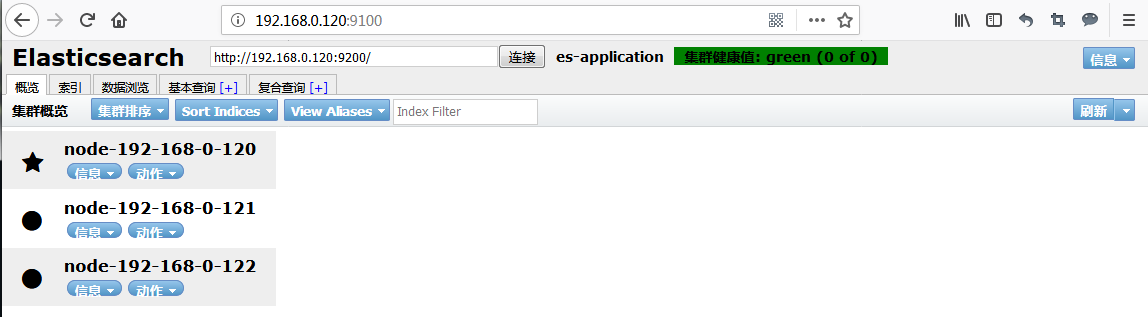
2.7 关闭一个 es 比如192.168.0.122(slave2),重新测试是否可以连接。
^C
[2018-07-18T23:38:31,056][INFO ][o.e.n.Node ] [node-192-168-0-122] stopping ... [2018-07-18T23:38:31,121][INFO ][o.e.n.Node ] [node-192-168-0-122] stopped [2018-07-18T23:38:31,121][INFO ][o.e.n.Node ] [node-192-168-0-122] closing ... [2018-07-18T23:38:31,131][INFO ][o.e.n.Node ] [node-192-168-0-122] closed [spark@slave2 elasticsearch-6.2.2]$
此时测试发现es集群不可以使用了。
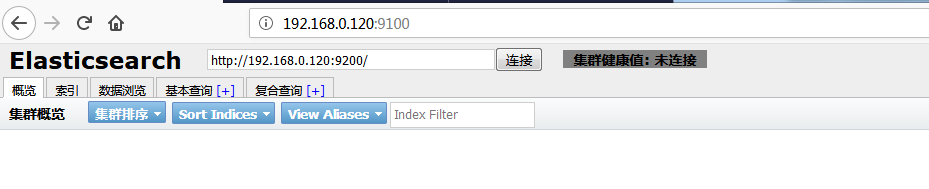
这与我们配置的参数有关系:
## 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.minimum_master_nodes: 2
修改master,slave1,slave2上的该参数为2,之前我们配置的为3。之后重新启动后,通过es-head验证三个节店都是健康运行的,之后ctrl+c关闭slave2,再次通过es-head查看:
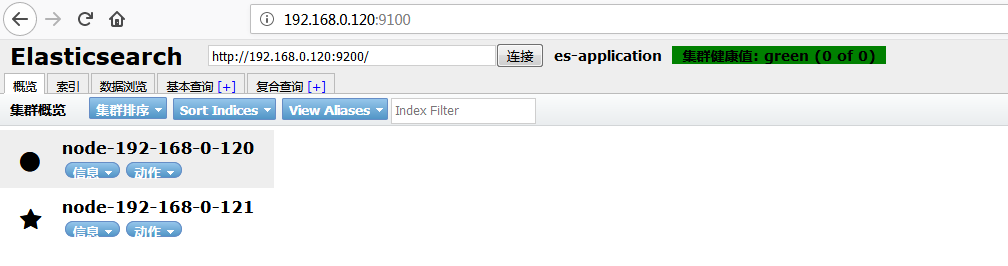
紧接着再次把slave1的es也关闭,再次通过es-head查看:

紧接着,把slave1,或者slave2启动,通过es-head发现es集群又可以运行了。
3 安装Kibana(不需要安装x-pack)
这里只需要在es集群中的一个节点上安装就可以了。
3.1 Kibana介绍
下面就Kibana对ES的查询监控作介绍,就是常提到的大数据日志处理组件ELK里的K。
什么是Kibana?现引用园友的一段对此的介绍,个人觉得比较全。
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。
Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。
设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
主要功能
- Elasticsearch无缝之集成

Kibana架构为Elasticsearch定制,可以将任何结构化和非结构化数据加入Elasticsearch索引。Kibana还充分利用了Elasticsearch强大的搜索和分析功能。
- 整合你的数据

Kibana能够更好地处理海量数据,并据此创建柱形图、折线图、散点图、直方图、饼图和地图。
- 复杂数据分析

Kibana提升了Elasticsearch分析能力,能够更加智能地分析数据,执行数学转换并且根据要求对数据切割分块。
- 让更多团队成员受益

强大的数据库可视化接口让各业务岗位都能够从数据集合受益。
- 接口灵活,分享更容易

使用Kibana可以更加方便地创建、保存、分享数据,并将可视化数据快速交流。
- 配置简单

Kibana的配置和启用非常简单,用户体验非常友好。Kibana 4自带Web服务器,可以快速启动运行。
- 可视化多数据源

Kibana可以非常方便地把来自Logstash、ES-Hadoop、Beats或第三方技术的数据整合到Elasticsearch,支持的第三方技术包括Apache Flume、Fluentd等。
- 简单数据导出

Kibana可以方便地导出感兴趣的数据,与其它数据集合并融合后快速建模分析,发现新结果。
- 与Elasticsearch REST API实现可视化交互

Sense是一个可视化终端,通过Kibana插件支持自动补全、自动缩进和语法检查功能。
参考《https://www.cnblogs.com/zhangs1986/p/7325504.html》
3.2 Kibana安装:
注意kibana的版本要和es的版本一致,否则可能会出现异常,上边我们安装es v6.2.2,因此这里安装kibana-6.2.2((https://artifacts.elastic.co/downloads/kibana/kibana-6.2.2-linux-x86_64.tar.gz))
1.下载https://www.elastic.co/cn/downloads/kibana 版本要和es版本相同
2.直接解压到 /opt/kibana-6.2.2-linux-x86_64
[spark@master opt]$ sudo tar -zxvf kibana-6.2.2-linux-x86_64.tar.gz
3.分配kibana操作spark用户组*用户:
[spark@master opt]$ chown -R spark:spark /opt/kibana-6.2.2-linux-x86_64 [spark@master opt]$ ll drwxrwxr-x. 12 spark spark 232 Feb 17 03:20 kibana-6.2.2-linux-x86_64 -rw-r--r--. 1 root root 83415765 Jul 18 23:58 kibana-6.2.2-linux-x86_64.tar.gz [spark@master opt]$
4.配置
cd /opt/kibana-6.2.2-linux-x86_64 vim config/kibana.yml elasticsearch.url: "http://192.168.0.120:9200" # kibana监控哪台es机器 server.host: "192.168.0.120" # kibana运行在哪台机器
5.启动
[spark@master kibana-6.2.2-linux-x86_64]$ bin/kibana log [16:07:36.833] [info][status][plugin:kibana@6.2.2] Status changed from uninitialized to green - Ready log [16:07:36.880] [info][status][plugin:elasticsearch@6.2.2] Status changed from uninitialized to yellow - Waiting for Elasticsearch log [16:07:36.992] [info][status][plugin:timelion@6.2.2] Status changed from uninitialized to green - Ready log [16:07:37.003] [info][status][plugin:console@6.2.2] Status changed from uninitialized to green - Ready log [16:07:37.010] [info][status][plugin:metrics@6.2.2] Status changed from uninitialized to green - Ready log [16:07:37.045] [info][listening] Server running at http://192.168.0.120:5601 log [16:07:37.073] [info][status][plugin:elasticsearch@6.2.2] Status changed from yellow to green - Ready
6.查看界面http://192.168.0.120:5601 可以直接访问
参考:https://blog.csdn.net/fenglailea/article/details/52934263
http://www.51niux.com/?id=201
https://blog.csdn.net/qq_21383435/article/details/79367821