TensorFlow循环神经网络
实验原理
RNN的网络结构及原理
RNNs包含输入单元(Input units),输入集标记为{x0,x1,...,xt,xt+1,...},而输出单元(Output units)的输出集则被标记为{y0,y1,...,yt,yt+1.,..}。RNNs还包含隐藏单元(Hidden units),我们将其输出集标记为{h0,h1,...,ht,ht+1,...},这些隐藏单元完成了最为主要的工作。
它的网络结构如下:
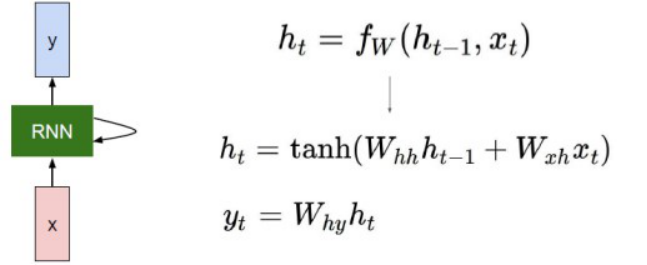
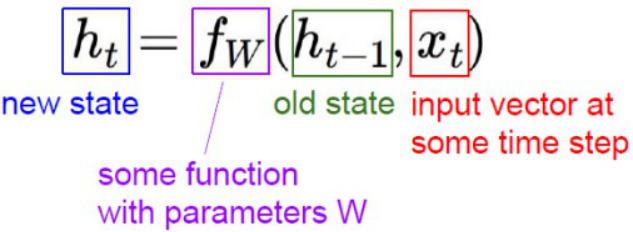
各个变量的含义:
展开以后形式:
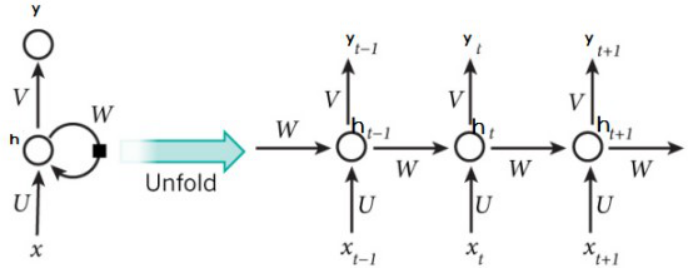
其中每个圆圈可以看作是一个单元,而且每个单元做的事情也是一样的,因此可以折叠成左半图的样子。用一句话解释RNN,就是一个单元结构重复使用。
RNN是一个序列到序列的模型,假设xt-1,xt,xt+1是一个输入:“我是中国“,那么ot-1,ot就应该对应”是”,”中国”这两个,预测下一个词最有可能是什么?就是ot+1应该是”人”的概率比较大。
完整代码
import numpy as np
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
mnist = input_data.read_data_sets("E:/PycharmProjects/TensorFlow/基础/1.3/data", one_hot = True)
#Training Parameters
learning_rate=0.001
training_steps=10000
batch_size=128
display_step=200
#Network Parameters
num_input=28
timesteps=28
num_hidden=128
num_classes=10
#tf Graph input
X=tf.placeholder("float",[None,timesteps,num_input])
Y=tf.placeholder("float",[None,num_classes])
# Define weights
weights={
'out':tf.Variable(tf.random_normal([num_hidden,num_classes]))
}
biases={
'out':tf.Variable(tf.random_normal([num_classes]))
}
def RNN(x,weights,biases):
x=tf.unstack(x,timesteps,1)
#define a lstm cell with tensorflow
lstm_cell=rnn.BasicLSTMCell(num_hidden,forget_bias=1.0)
#Get lstm cell ouput
outputs,states=rnn.static_rnn(lstm_cell,x,dtype=tf.float32)
#Linear activation ,using rnn inner loop last output
return tf.matmul(outputs[-1],weights['out'])+biases['out']
logits=RNN(X,weights,biases)
prediction=tf.nn.softmax(logits)
#Define loss and optimizer
loss_op=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits,labels=Y
))
optimizer=tf.train.GradientDescentOptimizer(learning_rate=learning_rate)
train_op=optimizer.minimize(loss_op)
#Evaluate model(with test logits,for dropout to be disabled)
corrent_pred=tf.equal(tf.argmax(prediction,1),tf.argmax(Y,1))
accuracy=tf.reduce_mean(tf.cast(corrent_pred,tf.float32))
#Initialize the variables
init=tf.global_variables_initializer()
#Start Training
with tf.Session() as sess:
# Run the initializer
sess.run(init)
for step in range(1,training_steps+1):
batch_x,batch_y=mnist.train.next_batch(batch_size)
# Reshape data to get 28 seq of 28 elements
batch_x=batch_x.reshape((batch_size,timesteps,num_input))
#Run optimization op
sess.run(train_op,feed_dict={X:batch_x,Y:batch_y})
if step % display_step ==0 or step==1:
#Calculate batch loss and accuracy
loss,acc=sess.run([loss_op,accuracy],feed_dict={X:batch_x,Y:batch_y})
print('Step'+str(step)+" ,Minibatch Loss"+"{:.4f}".format(loss)+
",Training Accuracy="+"{:.3f}".format(acc))
print("Optimization Finished!")
#Calculate accuracy for 128 mnist test images
test_len=128
test_data=mnist.test.images[:test_len].reshape((-1,timesteps,num_input))
test_label=mnist.test.labels[:test_len]
print("Testing Accuracy:",sess.run(accuracy,feed_dict={X:test_data,Y:test_label}))
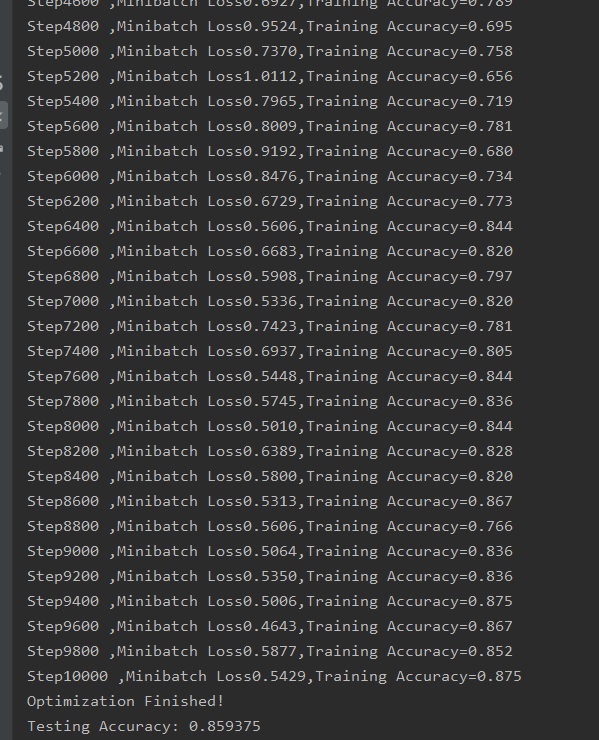
运行结果: