1、 先来说GC工作在哪块区域呢?
程序计数器,虚拟机栈(也就平时所说的栈), 本地方法栈这三区域随着线程而生,随着线程而灭,出栈入栈的操作,在栈中分配配的多少内存都具
有确定性,在这几个区域就不用考虑回收问题了,因为方法结束或线程结束,内存自然就回收了。
而堆区和方法区都是线程共享,堆区主要存放对象实例及数组对象,方法区存储已加载的类信息(每个类都有唯一个 Class<?>类对应着)、常量、
静态变量等,所以只有在程序运行的时候我们才能知道要创建哪些对象,这部分内存的分配和回收都是动态的, 所以这是GC关注的区域。

一。内存分布
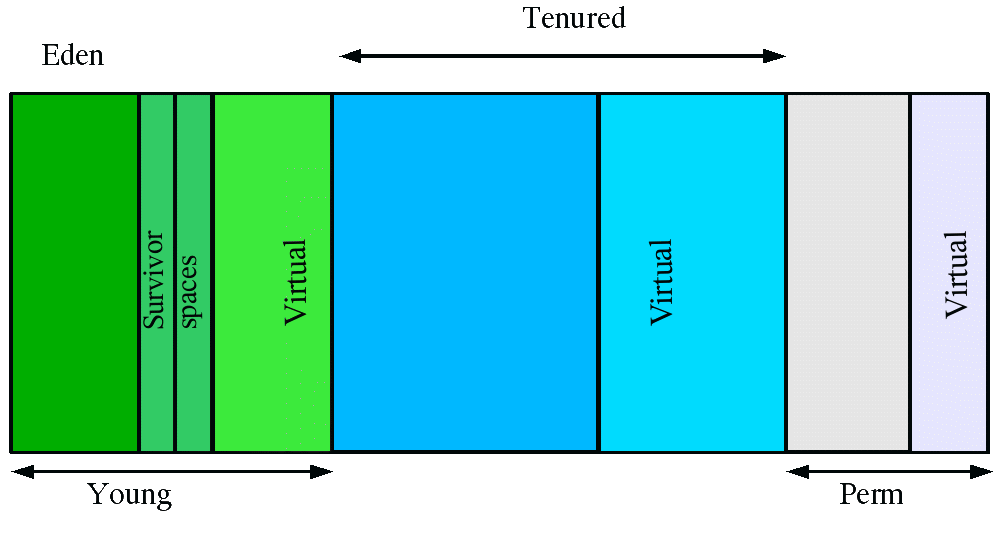
1.默认generation分布
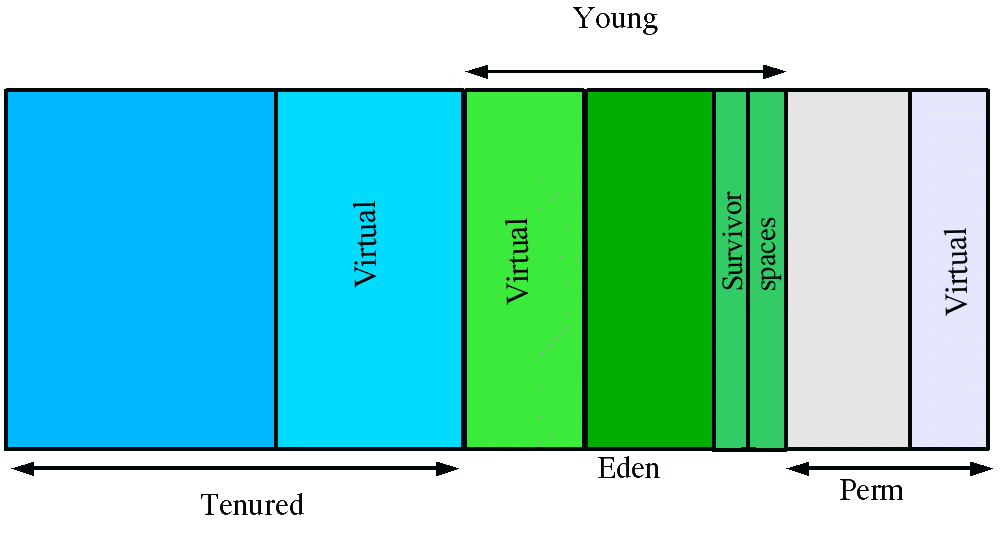
2.parallel collector的generation 分布
二。 内存划分
1. Young Generation
1 ) 生命周期很短的对象,归为 young generation 。由于生命周期很短,这部分对象在 gc 的时候,很大部分的对象已经成为非活动对象。因此针对
young generation 的对象,采用 copy 算法,只需要将少量的存活下来的对象 copy 到 to space 。存活的对象数量越少,那么copy 算法的效率越高。
2 )young generation 的 gc 称为 minor gc 。经过数次 minor gc ,依旧存活的对象,将被移出 young generation ,移到 tenured generation
3 ) young generation 分为:
1.3.1 eden :每当对象创建的时候,总是被分配在这个区域
1.3.2 survivor1 : copy 算法中的 from space
1.3.3 survivor2 : copy 算法中的 to sapce (备注:其中 survivor1 和 survivor2 的身份在每次 minor gc 后被互换)
4 )minor gc 的时候,会把 eden+survivor1(2) 的对象 copy 到 survivor2(1) 去。
2.Tenured Generation
1 )生命周期较长的对象,归入到 tenured generation 。一般是经过多次 minor gc ,还 依旧存活的对象,将移入到 tenured generation 。
(当然,在 minor gc 中如果存活的对象的超过 survivor 的容量,放不下的对象会直接移入到 tenured generation )
2 )tenured generation 的 gc 称为 major gc ,就是通常说的 full gc 。
3 )采用 compactiion 算法。由于 tenured generaion 区域比较大,而且通常对象生命周期都比较常, compaction 需要一定时间。
所以这部分的 gc 时间比较长。
4 ) minor gc 可能引发 full gc 。当 eden + from space 的空间大于 tenured generation 区的剩余空间时,会引发 full gc 。这是悲观算法,
要确保 eden + from space 的对象如果都存活,必须有足够的 tenured generation 空间存放这些对象。
3. Permanet Generation
1 ) 该区域比较稳定,主要用于存放 classloader 信息,比如类信息和 method 信息。
2 ) 对于 spring hibernate 这些需要动态类型支持的框架,这个区域需要足够的空间。
三。回收算法
1.引用计数(Reference Counting)
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。
此算法最致命的是无法处理循环引用的问题。
2.标记-清除(Mark-Sweep)
此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。
此算法需要暂停整个应用,同时,会产生内存碎片。
3.复制(Copying)
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外 一个区域中。
此算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不过出现“碎片”问题。
当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
4.标记-整理(Mark-Compact)
此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,
第一阶段从根节点开始标记所有被引用对象,
第二阶段遍历 整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。
此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
5.增量收集(Incremental Collecting)
实施垃圾回收算法,即:在应用进行的同时进行垃圾回收。
6.分代(Generational Collecting)
基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法进行回收
四。收集器
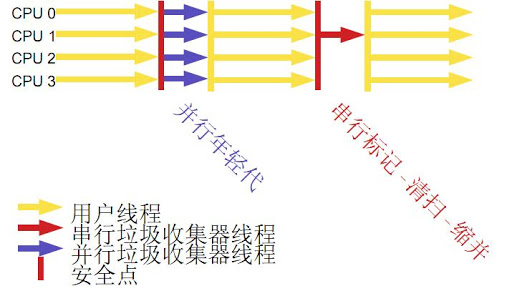
1.serial collector
使用单线程处理所有垃圾回收工作,因为无需多线程交互,所以效率比较高。但是,也无法使用多处理器的优势,所以此收集器适合单处理器机器。
当然,此收集器也可以用在小数据量(100M 左右)情况下的多处理器机器上。可以使用-XX:+UseSerialGC 打开。
2.parallel collector
适用情况:对吞吐量有高要求,多CPU、对应用响应时间无要求的中、大型应用。举例:后台处理、科学计算。
对年轻代进行并行垃圾回收,因此可以减少垃圾回收时间。一般在多线程多处理器机器上使用。使用-XX:+UseParallelGC 打开。
在Java SE6.0中可以堆年老代进行并行收集。使用-XX:+UseParallelOldGC 打开。
此收集器可以进行如下配置:
-XX:ParallelGCThreads=<N> 并行垃圾回收的线程数。此值可以设置与机器处理器数量相等
-XX:MaxGCPauseMillis=<N> 垃圾回收时的最长暂停时间
-XX:GCTimeRatio=<N> 垃圾回收时间与非垃圾回收时间的比值 ,公式为1/(1+N) 。
例如,-XX:GCTimeRatio=19时,表示5%的时间用于垃圾回收。默认情况为99,即1%的时间用于垃圾回收。
3.current collector
适用情况:对响应时间有高要求,多CPU、对应用响应时间有较高要求的中、大型应用。如:Web服务器/应用服务器、电信交换、集成开发环境。
使用-XX:+UseConcMarkSweepGC 打开。
并发收集器使用多处理器换来短暂的停顿时间 。在一个N个处理器的系统上,并发收集时使用K个可用处理器进行回收,一般情况下1 <= K <= N/4
在只有一个处理器的主机上使用并发收集器 ,设置为incremental mode 模式也可获得较短的停顿时间
1)浮动垃圾 :由于在应用运行的同时进行垃圾回收,所以有些垃圾可能在垃圾回收进行完成时产生,这样就造成了“Floating Garbage”,这些垃圾
需要在下次垃圾回收周期时才能回收掉。所以,并发收集器一般需要20% 的预留空间用于这些浮动垃圾。
2)Concurrent Mode Failure :因为并发收集在应用运行时,通过设置-XX:CMSInitiatingOccupancyFraction=<N> 指定还有多少剩余堆时
开始执行并发收集
保证收集完成之前有足够的内存空间供程序使用。