https://github.com/JerryLead/SparkInternals/blob/master/markdown/3-JobPhysicalPlan.md
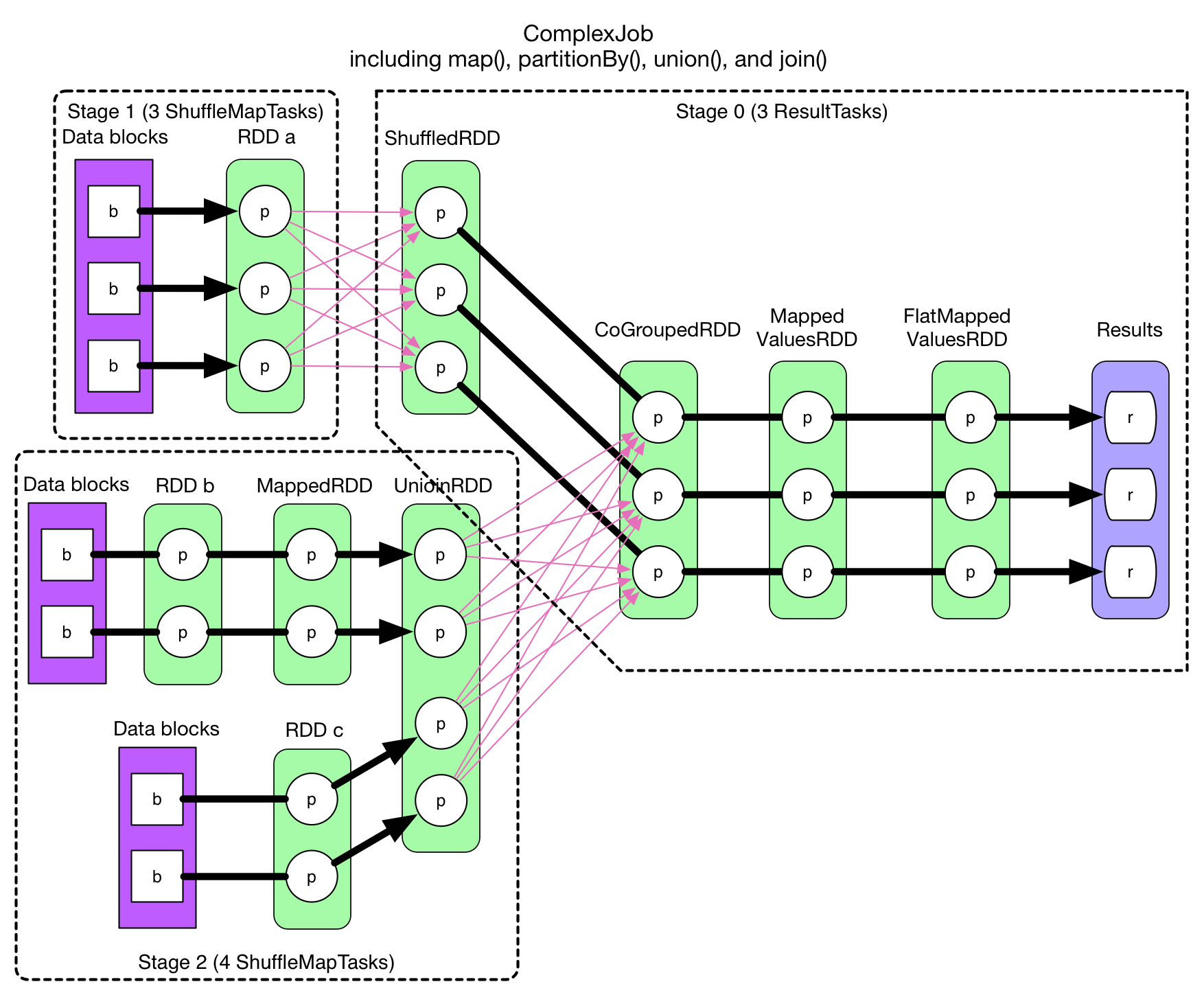
stage 和 task 的划分问题。只要在 ShuffleDependency 处断开,就只剩 NarrowDependency,而 NarrowDependency chain 是可以进行 pipeline 的。
所以划分算法就是:从后往前推算,遇到 ShuffleDependency 就断开,遇到 NarrowDependency 就将其加入该 stage。每个 stage 里面 task 的数目由该 stage 最后一个 RDD 中的 partition 个数决定。
粗箭头表示 task。因为是从后往前推算,因此最后一个 stage 的 id 是 0,stage 1 和 stage 2 都是 stage 0 的 parents。如果 stage 最后要产生 result,那么该 stage 里面的 task 都是 ResultTask,否则都是 ShuffleMapTask。之所以称为 ShuffleMapTask 是因为其计算结果需要 shuffle 到下一个 stage,本质上相当于 MapReduce 中的 mapper。ResultTask 相当于 MapReduce 中的 reducer(如果需要从 parent stage 那里 shuffle 数据),也相当于普通 mapper(如果该 stage 没有 parent stage)。
注意:transformation操作不一定没有shuffle,例如 reduceByKey操作中有shuffle
注意:
Narrow Dependency 指的是 child RDD 只依赖于 parent RDD(s) 固定数量的partition。
Wide Dependency 指的是 child RDD 的每一个partition都依赖于parent RDD(s) 所有partition。(又叫ShuffleDependency )
RDD可以抽象理解为一个大的数组,但这个数组是分布在集群上的。逻辑上的RDD的每个分区叫一个Partition。