一.简介
贝叶斯定理是关于随机事件A和事件B的条件概率的一个定理。通常在事件A发生的前提下事件B发生的概率,与在事件B发生的前提下事件A发生的概率是不一致的。然而,这两者之间有确定的
关系,贝叶斯定理就是这种关系的陈述。其中,L(A|B)表示在B发生的前提下,A发生的概率。L表示要取对数的意思。
关键词解释:
1.p(A),p(B)表示A,B发生的概率,也称先验概率或边缘概率。
2.p(B|A)表示在A发生的前提下,B发生的概率,也称后验概率。
基本公式:p(A|B) = p(AB)/p(B)
图解:

备注:p(AB) = p(BA)都是指A,B同时发生的概率,所以可得贝叶斯公式:p(B|A) = p(AB)/p(A) = p(A|B)p(B)/p(A)导入数据得 = 0.5*0.4/0.8 = 0.25
贝叶斯公式:p(B|A) = p(A|B)p(B)/p(A)
图解:同上
朴素贝叶斯分类是一种十分简单的分类算法,其算法基础是对于给出的待分类项,求解在此项出现的条件下各类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
实现步骤:

二.代码实现【python】
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Tue Oct 28 14:40:38 2018 4 5 @author: zhen 6 """ 7 from sklearn.datasets import fetch_20newsgroups 8 from sklearn.model_selection import train_test_split 9 from sklearn.feature_extraction.text import CountVectorizer 10 from sklearn.naive_bayes import MultinomialNB 11 from sklearn.metrics import classification_report 12 # 数据获取 13 news = fetch_20newsgroups(subset='all') 14 15 # 数据预处理:分割训练集和测试集 16 x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25, random_state=33) 17 # 文本特征向量化 18 vec = CountVectorizer() 19 x_train = vec.fit_transform(x_train) 20 x_test = vec.transform(x_test) 21 22 # 使用朴素贝叶斯进行训练(多项式模型) 23 mnb = MultinomialNB() 24 mnb.fit(x_train, y_train) 25 y_predict = mnb.predict(x_test) 26 27 # 获取预测结果 28 print(classification_report(y_test, y_predict, target_names = news.target_names)) 29 print("the accuracy of MultinomialNB is:", mnb.score(x_test, y_test))
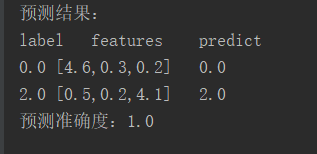
三.结果【python】

四.代码实现【Spark】
1 package big.data.analyse.ml 2 3 import org.apache.log4j.{Level,Logger} 4 import org.apache.spark.NaiveBayes 5 import org.apache.spark.ml.linalg.Vectors 6 import org.apache.spark.ml.feature.LabeledPoint 7 import org.apache.spark.sql.{SparkSession} 8 9 /** 10 * Created by zhen on 2019/9/9. 11 */ 12 object NaiveBayesAnalyse { 13 Logger.getLogger("org").setLevel(Level.WARN) 14 def main(args: Array[String]) { 15 val spark = SparkSession.builder().appName("NaiveBayes").master("local[2]").getOrCreate() 16 17 /** 18 * 加载数据 19 */ 20 val test_data_array = Array("0,1.2-0.5-0.2","0,2.1-0.3-0.2","0,3.6-0.1-1.0","0,4.6-0.3-0.2", 21 "1,0.4-1.5-0.2","1,0.2-2.6-0.8","1,0.6-3.3-0.6","1,0.1-4.3-0.4", 22 "2,0.1-0.4-1.8","2,0.2-0.4-2.1","2,0.3-0.1-3.3","2,0.5-0.2-4.1") 23 24 val sc = spark.sparkContext 25 val test_data = sc.parallelize(test_data_array).map(row => { 26 val array = row.split(",") 27 LabeledPoint(array(0).toDouble,Vectors.dense(array(1).split("-").map(_.toDouble))) 28 }) 29 30 /** 31 * 拆分数据为训练数据和测试数据 32 */ 33 val splits = test_data.randomSplit(Array(0.8, 0.2), seed = 11L) 34 val train = splits(0) 35 val test = splits(1) 36 37 /** 38 * 创建朴素贝叶斯模型并训练 39 * 使用多项式模型 40 */ 41 val model = NaiveBayes.train(train, lambda = 1.0, modelType = "multinomial") 42 43 /** 44 * 预测 45 */ 46 val predict = test.map(row => (row.label, model.predict(row.features))) 47 val predict_show = predict.take(20) 48 val test_take = test.take(20) 49 println("预测结果:") 50 println("label" + " " + "features" + " " + "predict") 51 for(i <- 0 until predict_show.length){ 52 println(predict_show(i)._1 + " " + test_take(i).features +" " + predict_show(i)._2) 53 } 54 55 val acc = 1.0 * predict.filter(row => row._1 == row._2).count() / test.count() 56 println("预测准确度:"+acc) 57 } 58 }
五.模拟源码实现【Spark】
NaiveBayes朴素贝叶斯类:
1 package org.apache.spark 2 3 import org.apache.spark.ml.feature.LabeledPoint 4 import org.apache.spark.ml.linalg.{BLAS, DenseVector, SparseVector, Vector} 5 import org.apache.spark.rdd.RDD 6 7 /** 8 * Created by zhen on 2019/9/11. 9 */ 10 object NaiveBayes{ 11 /** 12 * 多项式模型类别 13 */ 14 val Multinomial : String = "multinomial" 15 16 /** 17 * 伯努利模式类型 18 */ 19 val Bernoulli : String = "bernoulli" 20 21 /** 22 * 设置模型支持的类别 23 */ 24 val supportedModelTypes = Set(Multinomial, Bernoulli) 25 26 /** 27 * 训练一个朴素贝叶斯模型 28 * @param input 样本RDD 29 * @return 30 */ 31 def train(input : RDD[LabeledPoint]) : NaiveBayesModel = { 32 new NaiveBayes().run(input) 33 } 34 35 /** 36 * 训练一个朴素贝叶斯模型 37 * @param input 样本RDD 38 * @param lambda 平滑系数 39 * @return 40 */ 41 def train(input : RDD[LabeledPoint], lambda : Double) : NaiveBayesModel = { 42 new NaiveBayes(lambda, Multinomial).run(input) 43 } 44 45 /** 46 * 训练一个朴素贝叶斯模型 47 * @param input 样本RDD 48 * @param lambda 平滑系数 49 * @param modelType 模型类型 50 * @return 51 */ 52 def train(input : RDD[LabeledPoint], lambda : Double, modelType : String) : NaiveBayesModel = { 53 require(supportedModelTypes.contains(modelType), s"NaiveBayes was created with an unknown modelType:$modelType.") 54 new NaiveBayes(lambda, modelType).run(input) 55 } 56 } 57 58 /** 59 * 贝叶斯分类类 60 * @param lambda 平滑系数 61 * @param modelType 模型类型 62 */ 63 class NaiveBayes private(private var lambda : Double, 64 private var modelType : String) extends Serializable{ 65 66 import NaiveBayes.{Bernoulli, Multinomial} 67 68 def this(lambda : Double) = this(lambda, NaiveBayes.Multinomial) 69 70 def this() = this(1.0, NaiveBayes.Multinomial) 71 72 /** 73 * 设置平滑参数 74 * @param lambda 75 * @return 76 */ 77 def setLambda(lambda : Double) : NaiveBayes = { 78 this.lambda = lambda 79 this 80 } 81 82 /** 83 * 获取平滑参数 84 * @return 85 */ 86 def getLambda : Double = this.lambda 87 88 /** 89 * 设置模型类型 90 * @param modelType 91 * @return 92 */ 93 def setModelType(modelType : String) : NaiveBayes = { 94 require(NaiveBayes.supportedModelTypes.contains(modelType), s"NaiveBayes was created with an unknown modelType :$modelType.") 95 this.modelType = modelType 96 this 97 } 98 99 /** 100 * 获取模型类型 101 * @return 102 */ 103 def getModelType : String = this.modelType 104 105 /** 106 * 运行算法 107 * @param data 108 * @return 109 */ 110 def run(data : RDD[LabeledPoint]) : NaiveBayesModel = { 111 val requireNonnegativeValues : Vector => Unit = (v : Vector) => { 112 val values = v match { 113 case sv : SparseVector => sv.values 114 case dv : DenseVector => dv.values 115 } 116 if(!values.forall(_ >= 0.0)){ 117 throw new SparkException(s"Naive Bayes requires nonnegative feature values but found $v.") 118 } 119 } 120 121 val requireZeroOneBernoulliValues : Vector => Unit = (v : Vector) => { 122 val values = v match{ 123 case sv : SparseVector => sv.values 124 case dv : DenseVector => dv.values 125 } 126 if(!values.forall(v => v == 0.0 || v == 1.0)){ 127 throw new SparkException(s"Bernoulli naive Bayes requires 0 or 1 feature values but found $v.") 128 } 129 } 130 131 132 /** 133 * 对每个标签进行聚合操作,求得每个标签标签对应特征的频数 134 * 以label为key,聚合同一个label的features,返回(label, (计数, features之和)) 135 */ 136 println("训练数据:") 137 data.foreach(println) 138 val aggregated = data.map(row => (row.label, row.features))
.combineByKey[(Long, DenseVector)]( 139 createCombiner = (v : Vector) => { //完成样本从v到c的转化:(v:Vector) -> (c:(Long, DenseVector)) 140 if(modelType == Bernoulli){ 141 requireZeroOneBernoulliValues(v) 142 }else{ 143 requireNonnegativeValues(v) 144 } 145 (1L, v.copy.toDense) 146 }, 147 mergeValue = (c : (Long, DenseVector), v : Vector) => { // 合并 148 requireNonnegativeValues(v) 149 BLAS.axpy(1.0, v, c._2) 150 (c._1 + 1L, c._2) 151 }, 152 mergeCombiners = (c1 : (Long, DenseVector), c2 : (Long, DenseVector)) => { 153 BLAS.axpy(1.0, c2._2, c1._2) 154 (c1._1 + c2._1, c1._2) 155 } 156 ).collect() 157 158 val numLabels = aggregated.length // 类别标签数量 159 160 var numDocuments = 0L // 文档数量 161 aggregated.foreach{case (_, (n, _)) => 162 numDocuments += n 163 } 164 165 val numFeatures = aggregated.head match {case (_, (_, v)) => v.size} // 特征数量 166 167 val labels = new Array[Double](numLabels) // 标签列表列表 168 169 val pi = new Array[Double](numLabels) // pi类别的先验概率 170 171 val theta = Array.fill(numLabels)(new Array[Double](numFeatures)) // theta各个特征在类别中的条件概率 172 173 val piLogDenom = math.log(numDocuments + numLabels * lambda) //聚合计算theta 174 175 var i = 0 176 aggregated.foreach{case (label, (n, sumTermFreqs)) => 177 labels(i) = label 178 pi(i) = math.log(n + lambda) - piLogDenom // 计算先验概率,并取log 179 val thetaLogDenom = modelType match { 180 case Multinomial => math.log(sumTermFreqs.values.sum + numFeatures * lambda) // 多项式模型 181 case Bernoulli => math.log(n + 2.0 * lambda) // 伯努利模型 182 case _ => throw new UnknownError(s"Invalid modeType: $modelType.") 183 } 184 var j = 0 185 while(j < numFeatures){ 186 theta(i)(j) = math.log(sumTermFreqs(j) + lambda) - thetaLogDenom // 计算各个特征在各个类别中的条件概率 187 j += 1 188 } 189 i+= 1 190 } 191 new NaiveBayesModel(labels, pi, theta, modelType) 192 } 193 }
NaiveBayesModel朴素贝叶斯模型类:
1 package org.apache.spark 2 3 import org.apache.spark.ml.linalg.{BLAS, Vector, DenseMatrix, DenseVector} 4 import org.apache.spark.mllib.util.Saveable 5 import org.apache.spark.rdd.RDD 6 7 /** 8 * Created by zhen on 2019/9/12. 9 */ 10 class NaiveBayesModel private[spark]( 11 val labels : Array[Double], 12 val pi : Array[Double], 13 val theta : Array[Array[Double]], 14 val modelType : String 15 ) extends Serializable with Saveable{ 16 17 import NaiveBayes.{Bernoulli, Multinomial, supportedModelTypes} 18 19 private val piVector = new DenseVector(pi) // 类别的先验概率 20 21 private val thetaMatrix = new DenseMatrix(labels.length, theta(0).length, theta.flatten, true) // 各个特征在各个类别的条件概率 22 23 private[spark] def this(labels:Array[Double], pi:Array[Double], theta:Array[Array[Double]]) = this(labels, pi, theta, NaiveBayes.Multinomial) 24 25 /** 26 * java接口的构造函数 27 */ 28 private[spark] def this( 29 labels : Iterable[Double], 30 pi : Iterable[Double], 31 theta : Iterable[Iterable[Double]] 32 ) = this(labels.toArray, pi.toArray, theta.toArray.map(_.toArray)) 33 34 require(supportedModelTypes.contains(modelType), s"Invalid modelType $modelType.Supported modelTypes are $supportedModelTypes.") 35 36 /** 37 * 伯努利模型额外处理 38 */ 39 private val (thetaMinusNegTheta, negThetaSum) = modelType match { 40 case Multinomial => (None, None) 41 case Bernoulli => 42 val negTheta = thetaMatrix.map(value => math.log(1.0 - math.exp(value))) 43 val ones = new DenseVector(Array.fill(thetaMatrix.numCols){1.0}) 44 val thetaMinusNegTheta = thetaMatrix.map{value => value - math.log(1.0 - math.exp(value))} 45 (Option(thetaMinusNegTheta), Option(negTheta.multiply(ones))) 46 case _ => throw new UnknownError(s"Involid modelType: $modelType.") 47 } 48 49 /** 50 * 对样本RDD进行预测 51 */ 52 def predict(testData : RDD[Vector]) : RDD[Double] = { 53 val bcModel = testData.context.broadcast(this) 54 testData.mapPartitions{ iter => 55 val model = bcModel.value 56 iter.map(model.predict) // 调用参数为一个样本的predict 57 } 58 } 59 60 /** 61 * 根据一个样本的特征向量进行预测 62 */ 63 def predict(testData : Vector) : Double = { 64 modelType match { 65 case Multinomial => 66 val prob = thetaMatrix.multiply(testData) 67 RBLAS.axpy(1.0, piVector, prob) 68 labels(prob.argmax) 69 case Bernoulli => 70 testData.foreachActive{(index, value) => 71 if(value != 0.0 && value != 1.0){ 72 throw new SparkException(s"Bernouslli naive Bayes requires 0 or 1 feature values but found $testData.") 73 } 74 } 75 val prob = thetaMinusNegTheta.get.multiply(testData) 76 BLAS.axpy(1.0, piVector, prob) 77 BLAS.axpy(1.0, negThetaSum.get, prob) 78 labels(prob.argmax) 79 case _ => 80 throw new UnknownError(s"Involid modelType: $modelType.") 81 } 82 } 83 84 /** 85 * 保存模型 86 */ 87 def save(sc : SparkContext, path : String) : Unit = { 88 //val data = NaiveBayesModel.SaveLoadV2_0.Data(labels, pi, theta, modelType) 89 //NaiveBayesModel.SaveLoadV2_0.save(sc, path, data) 90 } 91 92 override protected def formatVersion : String = "2.0" 93 }
六.结果【Spark】