Hadoop 集群-本地模式(Local (Standalone) Mode)
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
默认情况下,Hadoop被配置为以非分布式模式作为单个Java进程运行。这对于调试很有用。接下来我们就一起跟着官方文档学习一下如何快速测试本地模式是否成功。
一.查看官方文档
1>.查看对应Apache Hadoop版本的官方文档
博主推荐阅读: http://hadoop.apache.org/docs/r2.10.0/
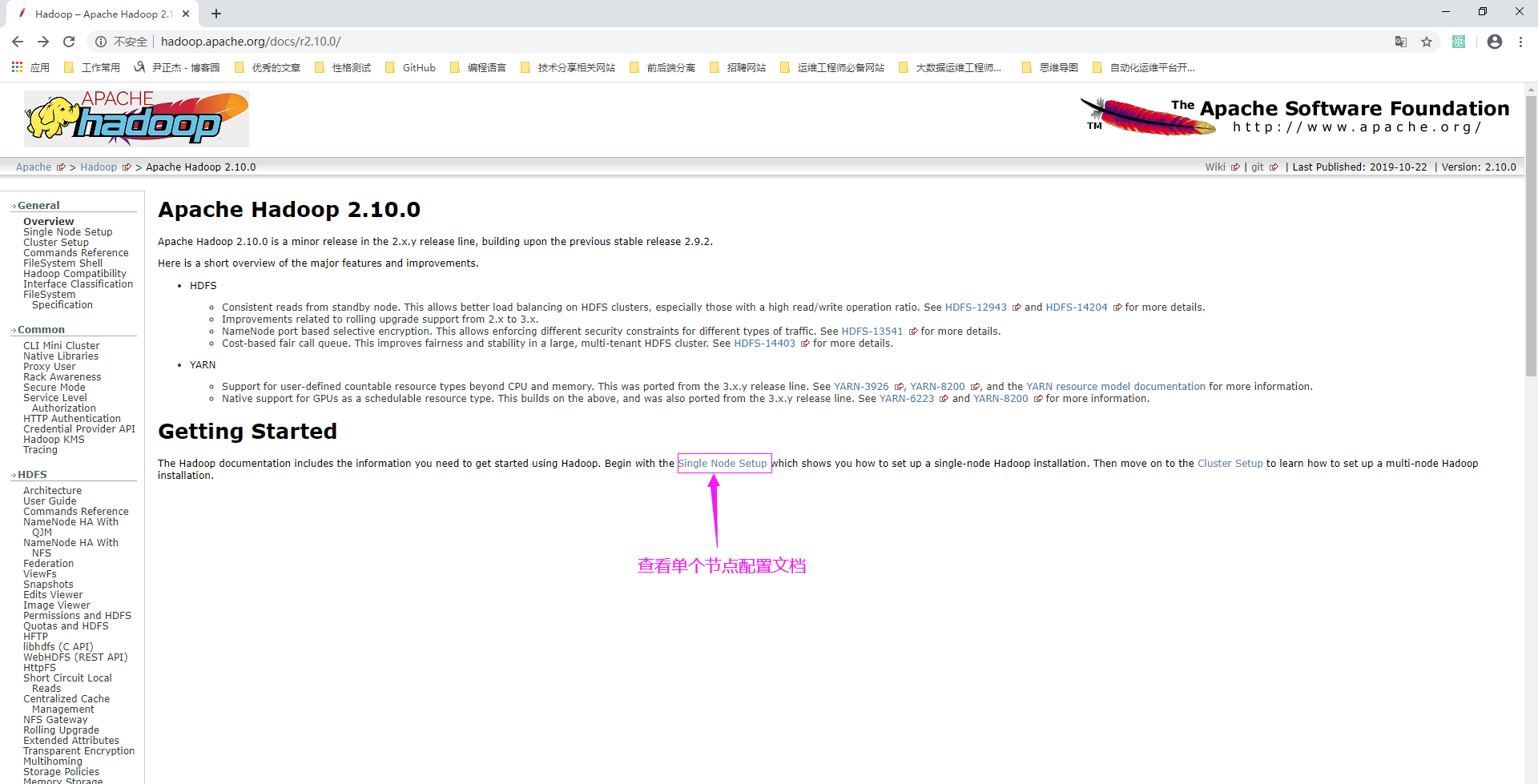
2>.查看Hadoop设置单节点群集的文档
博主推荐阅读: http://hadoop.apache.org/docs/r2.10.0/hadoop-project-dist/hadoop-common/SingleCluster.html#Standalone_Operation

二.本地运行模式-WordCount案例
1>.Hadoop运行环境搭建
博主推荐阅读: https://www.cnblogs.com/yinzhengjie2020/p/12422758.html
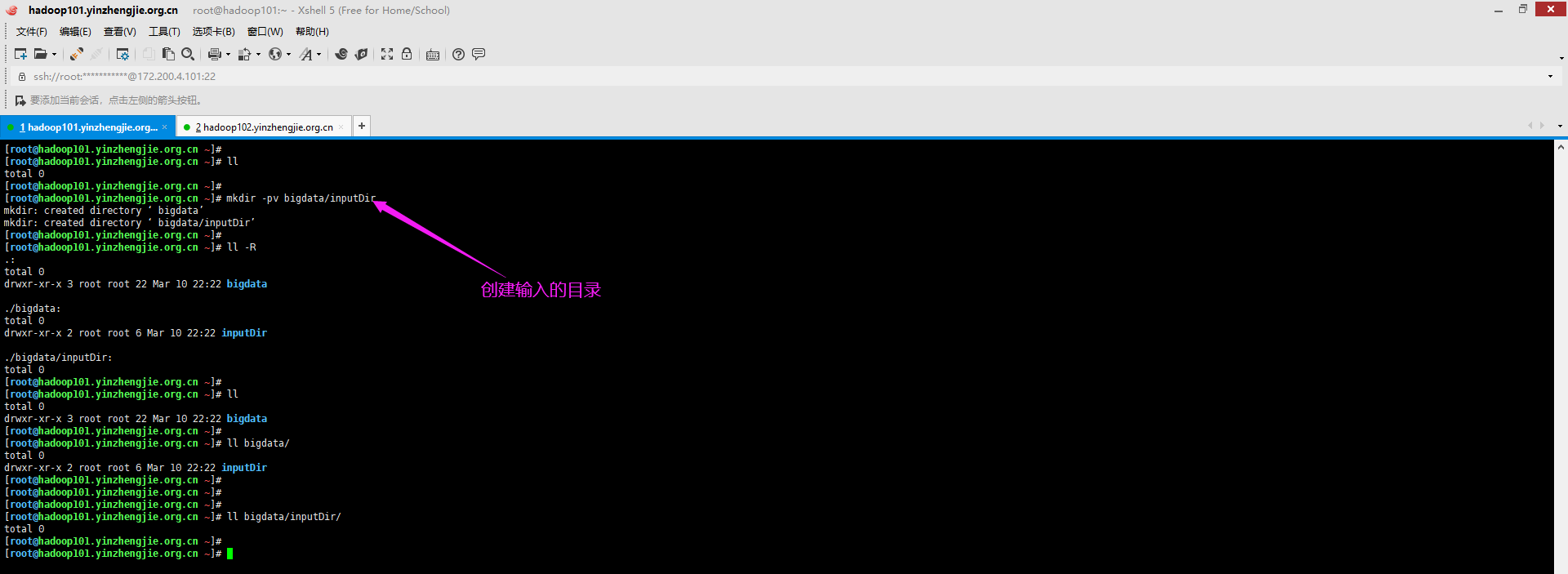
2>.创建输入目录
[root@hadoop101.yinzhengjie.org.cn ~]# mkdir -pv bigdata/inputDir
3>.将官方默认的配置文件拷贝到咱们自定义的空目录中
[root@hadoop101.yinzhengjie.org.cn ~]# cp /yinzhengjie/softwares/hadoop-2.10.0/etc/hadoop/*.xml bigdata/inputDir/

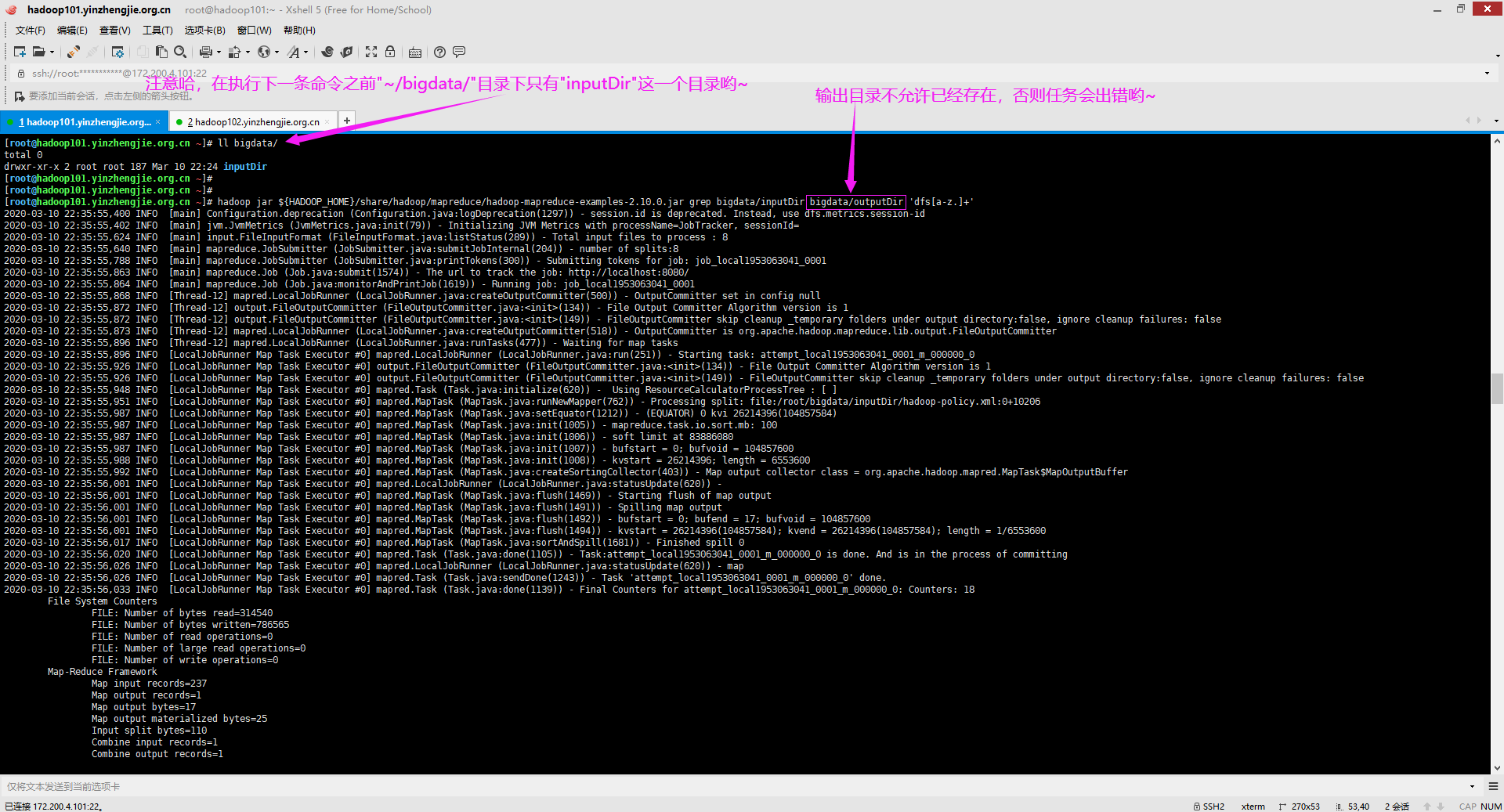
4>.执行Apache Hadoop官方文档的Grep案例
[root@hadoop101.yinzhengjie.org.cn ~]# ll bigdata/ total 0 drwxr-xr-x 2 root root 187 Mar 10 22:24 inputDir [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar grep bigdata/inputDir bigdata/outputDir 'dfs[a-z.]+'
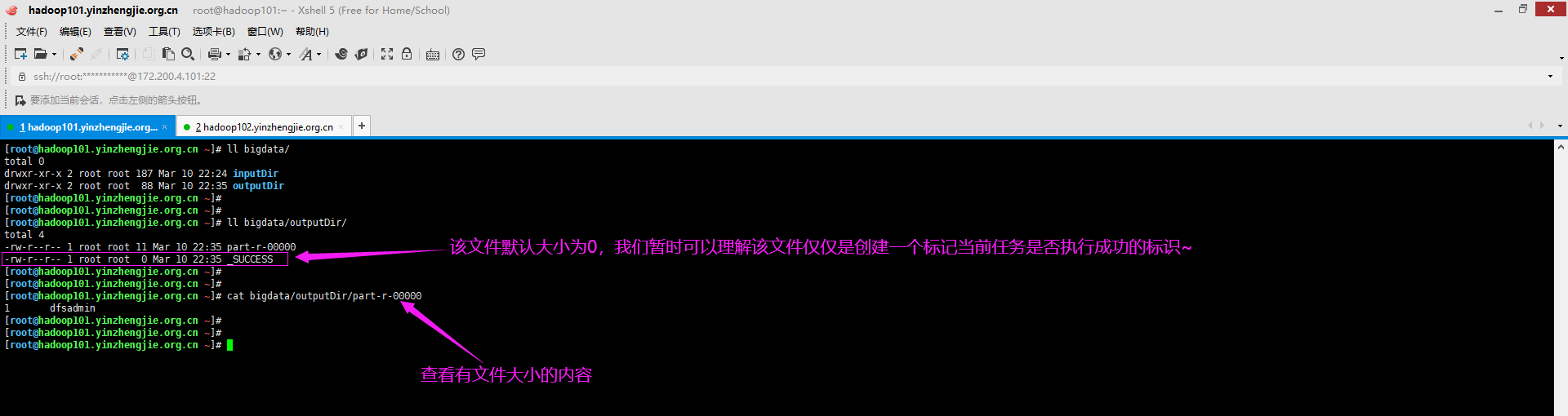
5>.查看输出目录数据信息
[root@hadoop101.yinzhengjie.org.cn ~]# ll bigdata/ total 0 drwxr-xr-x 2 root root 187 Mar 10 22:24 inputDir drwxr-xr-x 2 root root 88 Mar 10 22:35 outputDir [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# ll bigdata/outputDir/ total 4 -rw-r--r-- 1 root root 11 Mar 10 22:35 part-r-00000 -rw-r--r-- 1 root root 0 Mar 10 22:35 _SUCCESS [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# cat bigdata/outputDir/part-r-00000 1 dfsadmin [root@hadoop101.yinzhengjie.org.cn ~]#
三.本地运行模式-WordCount案例
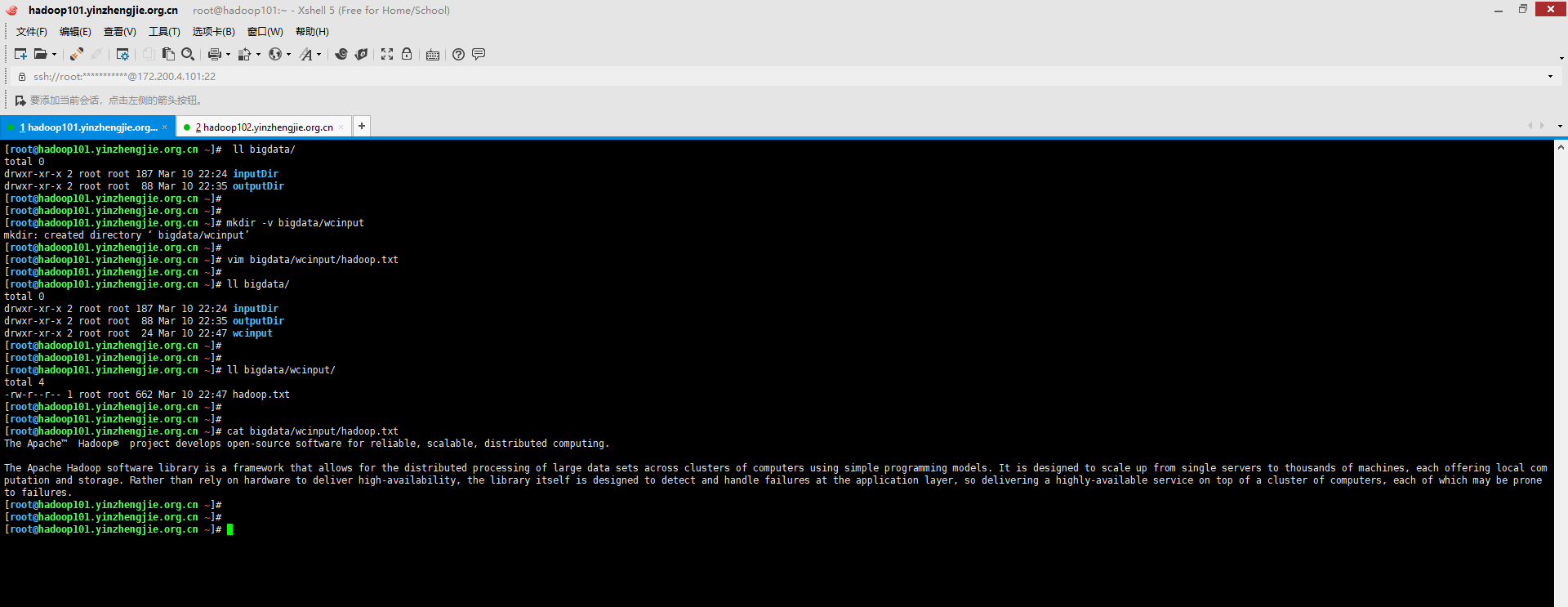
1>.创建测试数据
[root@hadoop101.yinzhengjie.org.cn ~]# mkdir -v bigdata/wcinput mkdir: created directory ‘bigdata/wcinput’ [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# vim bigdata/wcinput/hadoop.txt [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# cat bigdata/wcinput/hadoop.txt The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local com putation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
[root@hadoop101.yinzhengjie.org.cn ~]#
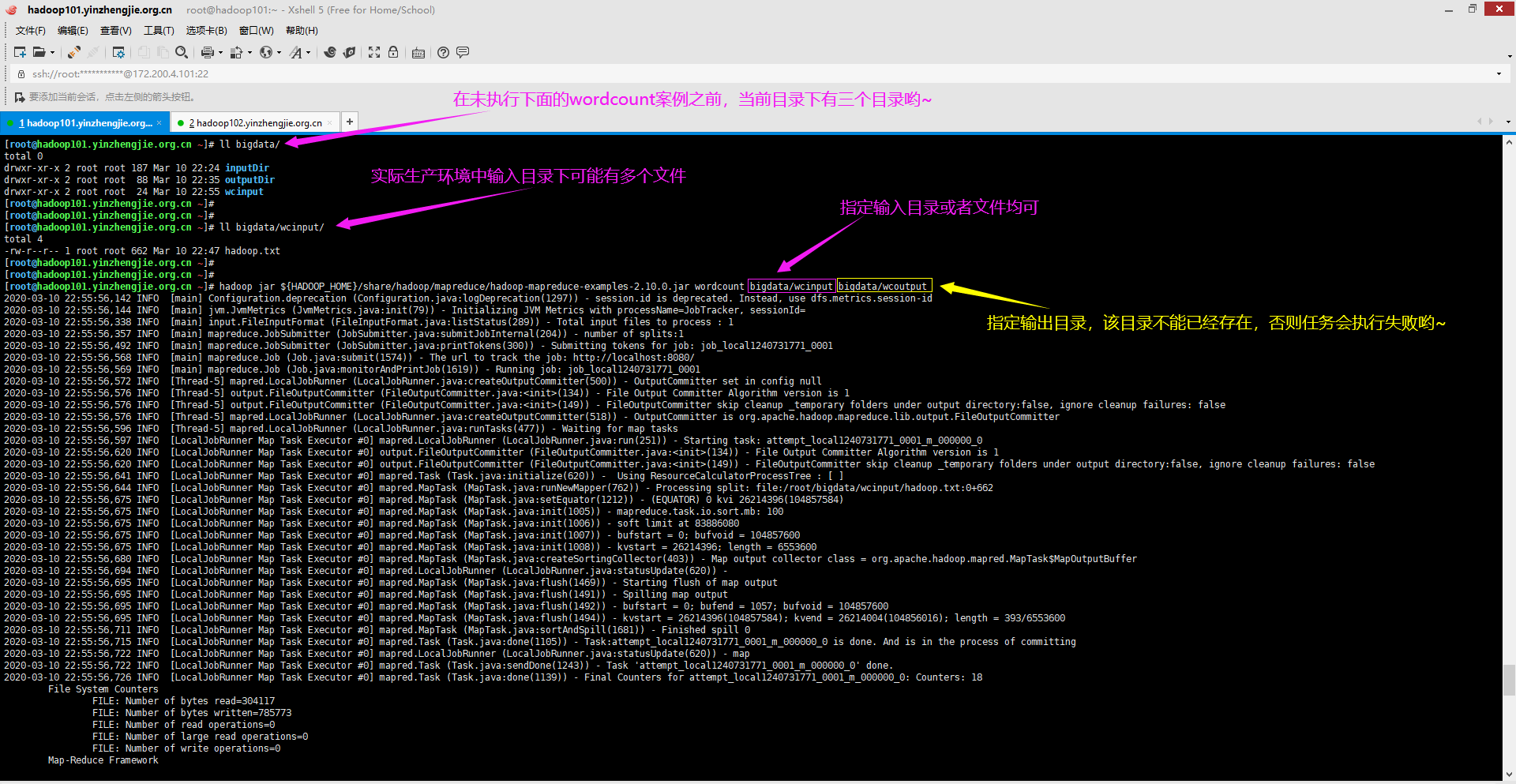
2>.执行wordcount案例
[root@hadoop101.yinzhengjie.org.cn ~]# ll bigdata/ total 0 drwxr-xr-x 2 root root 187 Mar 10 22:24 inputDir drwxr-xr-x 2 root root 88 Mar 10 22:35 outputDir drwxr-xr-x 2 root root 24 Mar 10 22:55 wcinput [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# ll bigdata/wcinput/ total 4 -rw-r--r-- 1 root root 662 Mar 10 22:47 hadoop.txt [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# hadoop jar ${HADOOP_HOME}/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount bigdata/wcinput bigdata/wcoutput
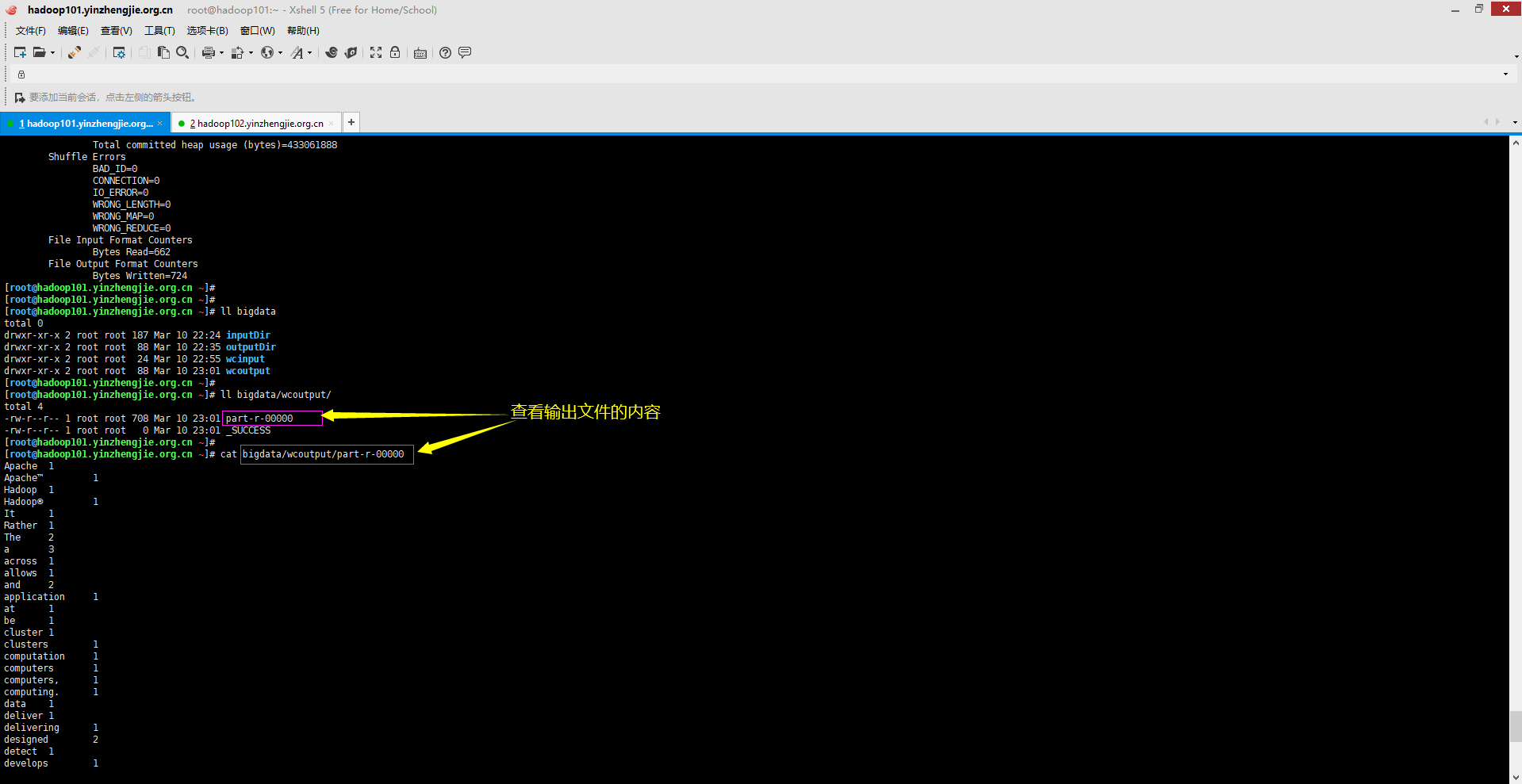
3>.查看输出的结果
[root@hadoop101.yinzhengjie.org.cn ~]# ll bigdata total 0 drwxr-xr-x 2 root root 187 Mar 10 22:24 inputDir drwxr-xr-x 2 root root 88 Mar 10 22:35 outputDir drwxr-xr-x 2 root root 24 Mar 10 22:55 wcinput drwxr-xr-x 2 root root 88 Mar 10 23:01 wcoutput [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]# ll bigdata/wcoutput/ total 4 -rw-r--r-- 1 root root 708 Mar 10 23:01 part-r-00000 -rw-r--r-- 1 root root 0 Mar 10 23:01 _SUCCESS [root@hadoop101.yinzhengjie.org.cn ~]#


[root@hadoop101.yinzhengjie.org.cn ~]# cat bigdata/wcoutput/part-r-00000 Apache 1 Apache™ 1 Hadoop 1 Hadoop® 1 It 1 Rather 1 The 2 a 3 across 1 allows 1 and 2 application 1 at 1 be 1 cluster 1 clusters 1 computation 1 computers 1 computers, 1 computing. 1 data 1 deliver 1 delivering 1 designed 2 detect 1 develops 1 distributed 2 each 2 failures 1 failures. 1 for 2 framework 1 from 1 handle 1 hardware 1 high-availability, 1 highly-available 1 is 3 itself 1 large 1 layer, 1 library 2 local 1 machines, 1 may 1 models. 1 of 6 offering 1 on 2 open-source 1 processing 1 programming 1 project 1 prone 1 reliable, 1 rely 1 scalable, 1 scale 1 servers 1 service 1 sets 1 simple 1 single 1 so 1 software 2 storage. 1 than 1 that 1 the 3 thousands 1 to 5 top 1 up 1 using 1 which 1 [root@hadoop101.yinzhengjie.org.cn ~]# [root@hadoop101.yinzhengjie.org.cn ~]#