前文已经介绍完了tensorflow2.0自定义layer、model、loss function,本文将结合前述知识,搭建一个稀疏自动编码器SAE。
(一)tensorflow2.0 - 自定义layer
(二)tensorflow2.0 - 自定义Model
(三)tensorflow2.0 - 自定义loss function(损失函数)
(四)tensorflow2.0 - 实战稀疏自动编码器SAE
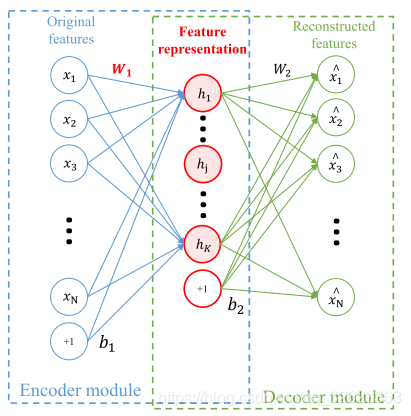
先简单介绍稀疏自动编码器SAE,其架构如下图所示(图源网络,侵删),三层结构,输出层应尽量和输入层接近,其重点在于中间的隐藏层,隐藏层将数据进行了重新编码,这样做的目的是获得输入数据更好的数据表示。在普通自动编码器中,往往要求隐藏层元素个数要比输入层元素个数少,但是稀疏自动编码器的要求不同,它可以允许隐藏层元素比输入层元素多,但是要保证稀疏性,即大多数隐藏层节点的输出值为0。
而SAE的损失函数,则为:
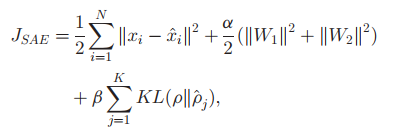
第一部分为预测值与真实值的SAE,第二部分为对权重的惩罚项,第三部分ρ和ρ帽分别代表期望的稀疏度和实际的稀疏度。
下面放上代码:
import tensorflow as tf
import numpy as np
import pandas as pd
from tensorflow.keras import *
import tensorflow.keras.backend as kb
import sys
import matplotlib.pyplot as plt
# 输入输出为16 × 1的列表
# inputList为输入列表
def SAEFC(inputList):
inputList = np.array(inputList)
# 输入特征个数
inputFeatureNum = len(inputList[0])
# 隐藏层参数个数:输入特征3倍
hiddenNum = 3 * inputFeatureNum
# 稀疏度(密度)
density = 0.1
lossList = []
saeModel = SAEModel(inputList.shape[-1], hiddenNum)
for i in range(1000):
loss = saeModel.network_learn(tf.constant(inputList))
lossList.append(loss)
print(loss)
# 绘制损失值图像
x = np.arange(len(lossList)) + 1
plt.plot(x, lossList)
plt.show()
return saeModel
# 自定义隐藏层
class SAELayer(layers.Layer):
def __init__(self, num_outputs):
super(SAELayer, self).__init__()
# 该层最后一个节点,其值固定为1,
# 前期可以按照同样的手段让该节点和其他节点一样进行计算,
# 最后在传递给下一层前,将其设置为1即可(即其值固定为1)
self.num_outputs = num_outputs
def build(self, input_shape):
self.kernel = self.add_variable("kernel",
shape=[int(input_shape[-1]),
self.num_outputs - 1])
self.bias = self.add_variable("bias",
shape=[self.num_outputs - 1])
def call(self, input):
output = tf.matmul(input, self.kernel) + self.bias
# sigmoid函数
output = tf.nn.sigmoid(output)
bias_list = tf.ones([input.shape[0], 1])
output = tf.concat([output, bias_list], 1)
self.result = output
return output
# 自定义模型
class SAEModel(Model):
# 可以传入一些超参数,用以动态构建模型
# __init_——()方法在创建模型对象时被调用
# input_shape: 输入层和输出层的节点个数(输入层实际要比这多1,因为有个bias)
# hidden_shape: 隐藏层节点个数,隐藏层节点的最后一个节点值固定为1,也是bias
# 使用方法:直接传入实际的input_shape即可,在call中也直接传入原始Input_tensor即可
# 一切关于数据适配模型的处理都在模型中实现
def __init__(self, input_shape, hidden_shape=None):
# print("init")
# 隐藏层节点个数默认为输入层的3倍
if hidden_shape == None:
hidden_shape = 3 * input_shape
# 调用父类__init__()方法
super(SAEModel, self).__init__()
self.train_loss = None
self.layer_2 = SAELayer(hidden_shape)
self.layer_3 = layers.Dense(input_shape, activation=tf.nn.sigmoid)
def call(self, input_tensor, training=False):
# 将input_tensor最后加一列1
bias_list = tf.ones([len(input_tensor), 1])
input_tensor = tf.concat([input_tensor, bias_list], 1)
# 输入数据
# x = self.layer_1(input_tensor)
hidden = self.layer_2(input_tensor)
output = self.layer_3(hidden)
return output
def get_loss(self, input_tensor):
# print("get_loss")
bias_list = tf.ones([len(input_tensor), 1])
new_input = tf.concat([input_tensor, bias_list], 1)
hidden = self.layer_2(new_input)
output = self.layer_3(hidden)
# 计算loss
# 计算MSE
mse = (1 / 2) * tf.reduce_sum(kb.square(input_tensor - output))
# 计算权重乘法项
alpha = 0.1
W1 = self.layer_2.kernel
W2 = self.layer_3.kernel
weightPunish = (alpha / 2) * (tf.reduce_sum(kb.square(W1)) + tf.reduce_sum(kb.square(W2)))
# 计算KL散度
beita = 0.1
desired_density = 0.1
layer2_output = self.layer_2.result
# 实际密度是所有输入数据的密度的平均值
actual_density = tf.reduce_mean(tf.math.count_nonzero(layer2_output, axis=1) / layer2_output.shape[1])
actual_density = tf.cast(actual_density, tf.float32)
if actual_density == tf.constant(1.0, dtype=tf.float32):
actual_density = tf.constant(0.999)
actual_density = actual_density.numpy()
KL = desired_density * np.log(desired_density / actual_density)
KL += (1 - desired_density) * np.log((1 - desired_density) / (1 - actual_density))
KL *= beita
ans = tf.constant(mse + weightPunish + KL)
return ans
def get_grad(self, input_tensor):
with tf.GradientTape() as tape:
tape.watch(self.variables)
L = self.get_loss(input_tensor)
# 保存一下loss,用于输出
self.train_loss = L
g = tape.gradient(L, self.variables)
return g
def network_learn(self, input_tensor):
g = self.get_grad(input_tensor)
optimizers.Adam().apply_gradients(zip(g, self.variables))
return self.train_loss
# 如果模型训练好了,需要获得隐藏层的输出,直接获取麻烦,则直接运行一遍
def getReprestation(self, input_tensor):
bias_list = tf.ones([len(input_tensor), 1])
new_input = tf.concat([input_tensor, bias_list], 1)
hidden = self.layer_2(new_input)
return hidden