1.1、Answer:web crawler question 1
概述
Question 1
1、cookie、JavaScript的关系?怎么产生的cookie?cookie包含哪些内容?JavaScript的功能在crawler代码中通过python的第三方库selenium,selenium用于执行JavaScript的脚本语
言,那selenium是什么?运行脚本语言的脚本语言?
Cookie产生背景
Cookie背景和意义:web应用包含多个页面,每个页面都对应一个url地址。web浏览器向Web服务器发送了两个请求,申请了两个页面。这两个页面的请求是分别使用了两个单独
的HTTP连接。由于HTTP是无状态的协议,浏览器和Web服务器会在第一个请求完成以后关闭连接通道,在第二个请求的时候重新建立连接。如果没有cookie,Web服务器并不区分
哪个请求来自哪个客户端,对所有的请求都一视同仁,都会针对这些请求建立单独的连接。无状态的协议优点:每个连接资源能够很快被其他客户端所重用;缺点:同一个用户发送的
请求都建立单独的连接产生多余的时间消耗!Cookie:记录用户登陆状态,可以优化HTTP是无状的缺点,而且设置cookie的域范围实现跨三级域名之间的cookie共享,那么有一个问
题如何实现跨二级域名之间的登陆信息共享呢、比如www.taobao.com和www.tmall.com之间就是登陆信息共享的。HTTP1.0版本无状态协议,HTTP1.1版本是支持持久连接的!
一、cookie
假设:web服务器接收到http请求,根据http请求的IP数据包中请求头中的客户端IP(key-value应该有映射关系)、coding(客户端编译器的语言)、浏览器url、等信息,使用???
数据结构抽象出一个结构体保存这些信息。保存在浏览器?这个结构体就是cookie。
拓展:1、JSESSIONID是一个Cookie,Servlet容器(tomcat,jetty)用来记录用户session
cookie
1、web crawler书籍解释:cookie是网站记录和跟踪用户登录凭据,包含用户是否已登录状态信息。cookie结构体包含:令牌、登录有效时限、状态跟踪信息
2、https://www.jianshu.com/p/6fc9cea6daa2解释:http协议本身是无状态的,web客户端使用http协议与web服务器交互,web服务器可以通过每次提交的IP数据包的请求头获取客户
端IP,将web服务器中的资源传递到对应的web客户端,但是web服务器无法跟踪web客户端。web客户端在web浏览器输入url地址(同一资源定位),发送IP数据报web服务端,web
服务端使用response向客户端浏览器颁发一个Cookie。Cookie保存在web浏览器。web浏览器再请求该网站时,web浏览器把请求的网址连同该Cookie一同提交给web服务器。web
服务器检查该Cookie,以此来跟踪用户状态。
二、cookie的结构体
1、https://blog.csdn.net/talking12391239/article/details/9665185的分析:
Cookie 结构体:Set-Cookie: NAME=VALUE;Expires=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
NAME=VALUE:NAME是该Cookie的名称,VALUE是该Cookie的值。在字符串“NAME=VALUE”中,不含分号、逗号和空格等字符
Expires=DATE:Expires变量确定了Cookie有效终止日期。该属性值DATE必须以特定的格式来书写:星期几,DD-MM-YY HH:MM:SS GMT,GMT表示这是格林尼治时间。反之,
不以这样的格式来书写,系统将无法识别。
注:Expires变量可省,如果缺省时,则Cookie的属性值不会保存在用户的硬盘中,而仅仅保存在内存当中,Cookie文件将随着浏览器的关闭而自动消失
Domain=DOMAIN-NAME:Domain变量确定了哪些Internet域中的Web服务器可读取浏览器所存取的Cookie,即只有来自这个域的页面才可以使用Cookie中的信息。这项设置是可选
的,如果缺省时,设置Cookie的属性值为该Web服务器的域名,所指定的域必须以点号(.)来开始如:.cnblogs.com
注:Internet域包含多个web服务器
Path=PATH:Path属性定义了Web服务器上哪些路径下的页面可获取服务器设置的Cookie。一般如果用户输入的URL中的路径部分从第一个字符开始包含Path属性所定义的字符串,
浏览器就认为通过检查。如果Path属性的值为“/”,则Web服务器上所有的WWW资源均可读取该Cookie。同样该项设置是可选的,如果缺省时,则Path的属性值为Web服务器传给浏
览器的资源的路径名。
Secure:Secure变量表明:只有当 web 浏览器和 Web 服务器之间的通信协议为加密认证协议时,浏览器才向服务器提交相应的Cookie。当前这种协议只有一种,即为HTTPS!
max-age: 与expires作用相同,用来告诉浏览器此cookie多久过期(单位是秒),而不是一个固定的时间点。正常情况下,max-age的优先级高于expires。maxAge属性为负数,则表
示该Cookie只是一个临时Cookie,不会被持久化,仅在本浏览器窗口或者本窗口打开的子窗口中有效,关闭浏览器后该Cookie立即失效。maxAge设置为0表示立即删除该Cookie
三、cookie的发送
web服务器利用响应报头Set-Cookie以键值的方式来发送COOKIE信息,在RFC2109中定义的SET-COOKIE响应报头的格式为:
Set-Cookie: Name = Value; Comment = value; Domain = value; Max-Age = value; Path = Value;Secure; Version = 1 * DIGIT;
注: 1、Name=Value属性值对必须首先出现,在此之后的属性-值对可以以任何顺序出现
2、Comment属性是可选的,因为Cookie可能包含其它有关用户私有的信息,这个属性允许服务器说明这个Cookie的使用,用户可以检查这个消息
3、web浏览器会将domain和path都相同的cookie保存在一个文件里,cookie间用*隔开
4、多个子键值对的cookie格式是name=key1=value1&key2=value2。可以理解为单键值对的值保存一个自定义的多键值字符串
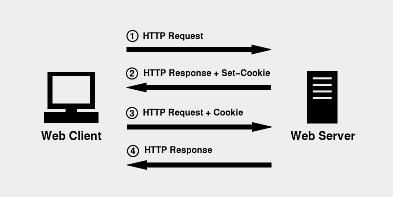
四、cookie:客户端存取cookie、服务器端解析cookie
1、服务器端解析cookie:cookie可以设置不同的域与路径,所以对于同一个name value,在不同域不同路径下是可以重复的,浏览器会按照与当前请求url或页面地址最佳匹配的顺序
来排定先后顺序
2、客户端的存取cookie:web浏览器将后台传递过来的cookie进行管理。开发者在JavaScript中使用document.cookie来存取cookie,但是cookie中设置了HttpOnly属性,那么通过js
脚本(document.cookie)将无法读取到cookie信息,而且document.cookie会由于使用方式不同而表现出不同的行为
2.1、document.cookie并不会覆盖cookie,除非设置的name value domain path都与一个已存在cookie重复
Cookie安全性
cookie中的数据通常会包含用户的隐私数据,Cookie安全性首先要保证数据的保密性,其次要保证数据不能被伪造或者篡改。基于这两点,cookie内容需要进行加密,加密方式:
对称加密(单密钥,如DES)或非对称加密(一对密钥,如RSA)。密钥需要保存在服务器端一个安全的地方。没有密钥就无法对数据进行解密,也无法伪造或篡改数据。重要的cookie数
据需要设置成HttpOnly的,避免跨站脚本获取你的cookie,保证了cookie在浏览器端的安全性。cookie可以设置只作用于安全的协议(https)通过Cookie类的setSecure(boolean flag)
来设置cookie只会在https下发送,而不会再http下发送,保证了cookie在服务器端的安全性。JavaEE中的Cookie类。
二、selenium
Selenium产生的背景
web客户端向web服务器发送请求,web服务器向web浏览器响应一个硬编码的HTML模板(不带有任何内容的HTML模板),web浏览器需要单独的Ajax请求来加载内容,并将这些内容放到HTML模板中的正确位置(slot),即HTML创建任务、内容管理系统已经从web服务器端移植到web浏览器端和web客户端。Selenium是web应用程序的测试工具,Selenium直接运行于浏览器中,过程包括:请求硬编码的HTML模板、执行任意的JavaScript、允许加载所有的数据、抓取网页的数据。Selenium加载的数据包括所有的数据,包括‘额外’:调用跟踪程序、加载侧边栏广告、调用侧边栏广告的跟踪程序、图像、CSS、第三方的字体数据等等。这是Selenium的缺点之一:由于在获取页面的过程中会发送很多请求,所以效率非常低,所以在很多时候需要酌情使用。Selenium的优点:Selenium能够执行页面上的js,对于js渲染的数据和模拟登陆处理起来非常容易
一、Selenium库包含的模块
1、Selenium库是一个完整的web应用程序测试系统,包括:录制(selenium IDE),编写及运行(Selenium Remote Control)、测试的并行处理(Selenium Grid)
2、Selenium库和JavaScript关系:Selenium获取硬编码的HTML模板(不带有任何内容的HTML模板),Selenium 的 webdiver 中集合了浏览器的中JavaScript的解析操作,Selenium通过driver.execute_script(some JavaScript code ),执行给定的JavaScript代码,加载所有的数据、抓取网页的数据!
3、Selenium库包含的模块:
3.1、webdiver
实例化webdiver对象
from selenium import webdriver
driver= webdriver.Chrome()
driver= webdriver.Firefox()
driver= webdriver.PhantomJS()
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ("Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36")
driver = webdriver.PhantomJS(desired_capabilities=dcap)
1、发送GET请求:driver.get(url)
from selenium import webdriver#导入库 driver= webdriver.Chrome()#声明浏览器 url = 'https:www.baidu.com' driver.get(url)#打开浏览器预设网址 print(browser.page_source)#打印网页源代码 driver.close()#关闭浏览器
2、添加cookie:driver.add_cookie( )、获取cookie:driver.get_cookie( )
# 添加cookie
cookies={
'username':'xxx',
'password':'xxx'
}
driver.add_cookie(cookie_dict=cookies)
driver.get('http://example.com')
# 获取cookie
driver.get_cookies()
3、获取当前页面的URL:driver.current_url( )
# 获取当前页面的URL url=driver.current_url
4、获取HTML源码:driver.page_source( )
# 获取HTML源码 source=driver.page_source
5、刷新:driver.refresh( )
# 刷新 driver.refresh()
6、截图:driver.save_screenshot( )
# 截图
driver.save_screenshot('sougou.png')
7、前进:driver.forward( ) ;后退:driver.back()
# 前进 driver.forward() # 后退 driver.back()
8、最大化窗口:driver.maximize_window( ) ;关闭当前页面(如果是最后一个页面,则退出浏览器):driver.close();退出浏览器:driver.quit()
# 最大化窗口 driver.maximize_window() # 关闭当前页面(如果是最后一个页面,则退出浏览器) driver.close() # 退出浏览器 driver.quit()
9、获取网页中的元素:查找单个元素(通用方法、特定方法)、查找多个元素(通用方法、特定方法)
# 查找单个元素
# 通用查找方法,by参数指定查找类型,value参数指定查找值
# By.ID
# By.CLASS_NAME
# By.XPATH
# By.CSS_SELECTOR
# By.LINK_TEXT
# By.PARTIAL_LINK_TEXT
# By.NAME
# By.TAG_NAME
# 导入By模块
from selenium.webdriver.common.by import By
element=driver.find_element(by=By.ID,value='id')
# 特定查找方法
element = driver.find_element_by_id('id')
element=driver.find_element_by_class_name('class')
element=driver.find_element_by_xpath('xpath')
element=driver.find_element_by_css_selector('css_selector')
element=driver.find_element_by_link_text('link_text') # 通过完整链接定位
element=driver.find_element_by_partial_link_text('partial_link_text') # 通过部分链接定位
element=driver.find_element_by_name('name') # 通过元素name标记定位
element=driver.find_element_by_tag_name('tag_name') # 通过元素名称定位
# 查找多个元素(同上,返回list)
# 通用查找方法
elements=driver.find_elements(by=By.XPATH,value='xpath')
# 特定查找方法
elements=driver.find_elements_by_id('id')
10、元素的方法:1、清空输入框中的内容:element.clear() ;2、模拟向输入框输入文字:element.send_keys('Python');
3、模拟按下回车键:element.send_keys(Keys.RETURN);4、模拟点击(要求element为可点击按钮:element.click()
# 清空输入框中的内容
element.clear()
# 模拟向输入框输入文字
element.send_keys('Python')
# 模拟按下回车键
element.send_keys(Keys.RETURN)
# 模拟点击(要求element为可点击按钮)
element.click()
11、处理弹窗:driver.switch_to.alert,alert适用于其他情况:切换新开的窗口:window(current_windows[1]);切换网页中嵌套的另一个网页:frame()等;实现过程一样
# 处理弹窗 alert_ele=driver.switch_to.alert alert_ele.dismiss()
12、拖拽元素ActionChains(动作链)
# 拖拽元素ActionChains(动作链) source_element=driver.find_element(By.ID,'id') target_element=driver.find_element(By.ID,'id') action_chains=ActionChains(driver) action_chains.drag_and_drop(source=source_element,target=target_element).perform()
13、页面时间:1、页面加载时间:driver.set_page_load_timeout(time/s);2、页面的等待时间:
# 设置页面加载超时时间,单位:秒
driver.set_page_load_timeout(30)
# 处理加载页面时的等待
# 方式一:执行命令等待的最长时间,单位:秒
driver.implicitly_wait(5)
# 方式二:休眠线程
import time
time.sleep(5)
# 方式三:显式等待
try:
element=WebDriverWait(driver,timeout=10).until(
EC.presence_of_all_elements_located((By.ID,'id'))
)
finally:
driver.quit()
注:1、方式三:显式等待中的 until或until_not 中的可执行方法method参数,method参数一定要是可以调用的,即这个对象一定有 call() 方法,否则会抛出异常:TypeError: 'xxx' object is not callable;但是element对象不是!
2、需要导入'EC'模块:from selenium.webdriver.support import expected_conditions as EC
14、导入容错的模块:exceptions
from selenium.common import exceptions
try:
driver.get('https://www.baidu.com/')
except exceptions.TimeoutException as err:
print(err,'请求超时')
15、执行JS脚本:driver.execute_script( )
# 执行JS脚本 js='window.scrollTo(0,document.body.scrollHeight);' # 滚动到页面底部 driver.execute_script(js) time.sleep(3)
注:1、window.scrollTo:JS控制滚动条的位置:(0,0):滚动到页面顶部;(0,document.body.scrollHeight):滚动到页面底部