闲聊
好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫。所以小颖就自己试着做了个爬博客园数据的demo。嘻嘻......
小颖最近养了条泰日天,自从养了我家仔仔后,我觉得我走上一条不归路,每天不到七点半就起床烧热水,然后给我家仔仔烫狗粮,给仔仔烫好狗粮后,我开始收拾自己,出门前给他再把热水瓶里的热水换了,每天跟伺候小孩一样伺候着我家小不点仔仔,然而在上周天他还是生病了,拉稀.......带宠物医院好不容易看好,医生说是低血糖,我就懵逼了,低血糖就不能让他饿着,可是他压根就不好好吃饭,我有什么办法,哎......操碎了心,祈祷吧希望我家小仔仔能健健康康快快乐乐的长大嘻嘻。

看代码啦:
1.首先先安装node。
2.新建package.json:
在自己创建的一个工程目录下打开cmd ,在里面输入命令npm init
3.新建data和img文件夹
4.新建app.js
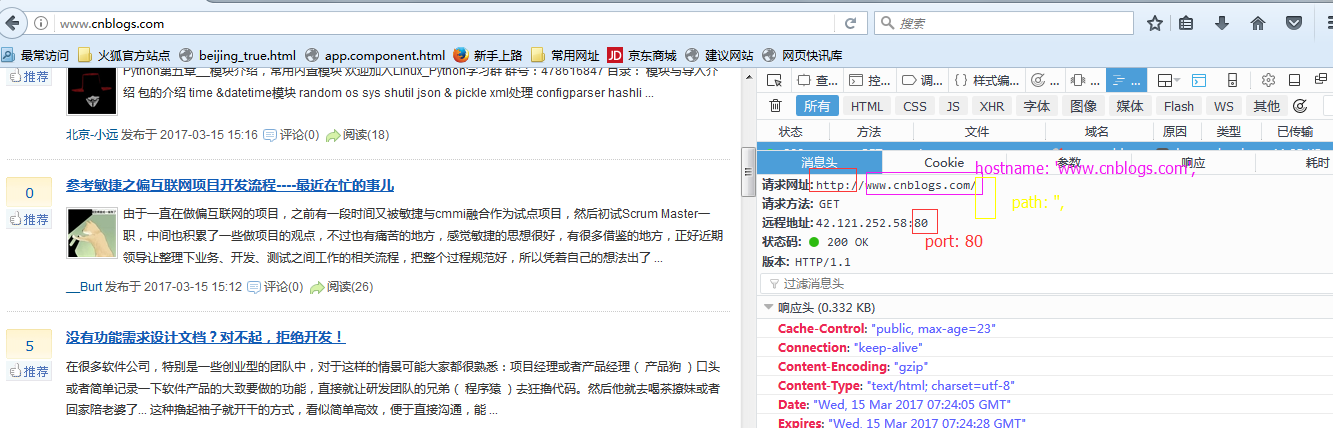
"use strict"; // 引入模块 var http = require('http'); var fs = require('fs'); var path = require('path'); var cheerio = require('cheerio'); // 爬虫的UR L信息 var opt = { hostname: 'www.cnblogs.com', path: '', port: 80 }; // 创建http get请求 http.get(opt, function(res) { var html = ''; // 保存抓取到的HTML源码 var blogs = []; // 保存解析HTML后的数据,即我们需要的电影信息 // 前面说过 // res 是 Class: http.IncomingMessage 的一个实例 // 而 http.IncomingMessage 实现了 stream.Readable 接口 // 所以 http.IncomingMessage 也有 stream.Readable 的事件和方法 // 比如 Event: 'data', Event: 'end', readable.setEncoding() 等 // 设置编码 res.setEncoding('utf-8'); // 抓取页面内容 res.on('data', function(chunk) { html += chunk; }); res.on('end', function() { // 使用 cheerio 加载抓取到的HTML代码 // 然后就可以使用 jQuery 的方法了 // 比如获取某个class:$('.className') // 这样就能获取所有这个class包含的内容 var $ = cheerio.load(html); // 解析页面 // 每篇文章都在 item class 中 $('#post_list .post_item .post_item_body').each(function() { // 获取图片链接 var blog = { title: $('.post_item_body .titlelnk', this).text(), // 获取文章标题 titleUrl: $('.post_item_body a', this).attr('href'), //文章链接地址 peopleUrl: $('.post_item_summary a', this).attr('href'), // 博客地址 peopleImg: $('.post_item_summary img', this).attr('src'),// 园友头像 intro: $('.post_item_summary', this).text(), // 获取文章简介 name: $('.post_item_foot .lightblue', this).text() // 获取文章简介 }; // 把所有文章放在一个数组里面 blogs.push(blog); if (blog.peopleImg) {// 如果有图片则下载图片 downloadImg('img/', 'http:' + blog.peopleImg); } }); // 保存抓取到的文章数据 saveData('data/data.json', blogs); }); }).on('error', function(err) { console.log(err); }); /** * 保存数据到本地 * * @param {string} path 保存数据的文件 * @param {array} blogs 文章信息数组 */ function saveData(path, blogs) { // 调用 fs.writeFile 方法保存数据到本地 fs.writeFile(path, JSON.stringify(blogs, null, 4), function(err) { if (err) { return console.log(err); } console.log('Data saved'); }); } /** * 下载图片 * * @param {string} imgDir 存放图片的文件夹 * @param {string} url 图片的URL地址 */ function downloadImg(imgDir, url) { http.get(url, function(res) { var data = ''; res.setEncoding('binary'); res.on('data', function(chunk) { data += chunk; }); res.on('end', function() { // 调用 fs.writeFile 方法保存图片到本地 fs.writeFile(imgDir + path.basename(url), data, 'binary', function(err) { if (err) { return console.log(err); } console.log('Image downloaded: ', path.basename(url)); }); }); }).on('error', function(err) { console.log(err); }); }
5.打开cmd执行 node app.js
然后看data文件夹下会生成data.json文件,img文件夹下会生成许多图片。
补充
// 爬虫的UR L信息
var opt = {
hostname: 'www.cnblogs.com',
path: '',
port: 80
};