神经网络与深度学习(更新至第6讲 循环神经网络)_哔哩哔哩_bilibili
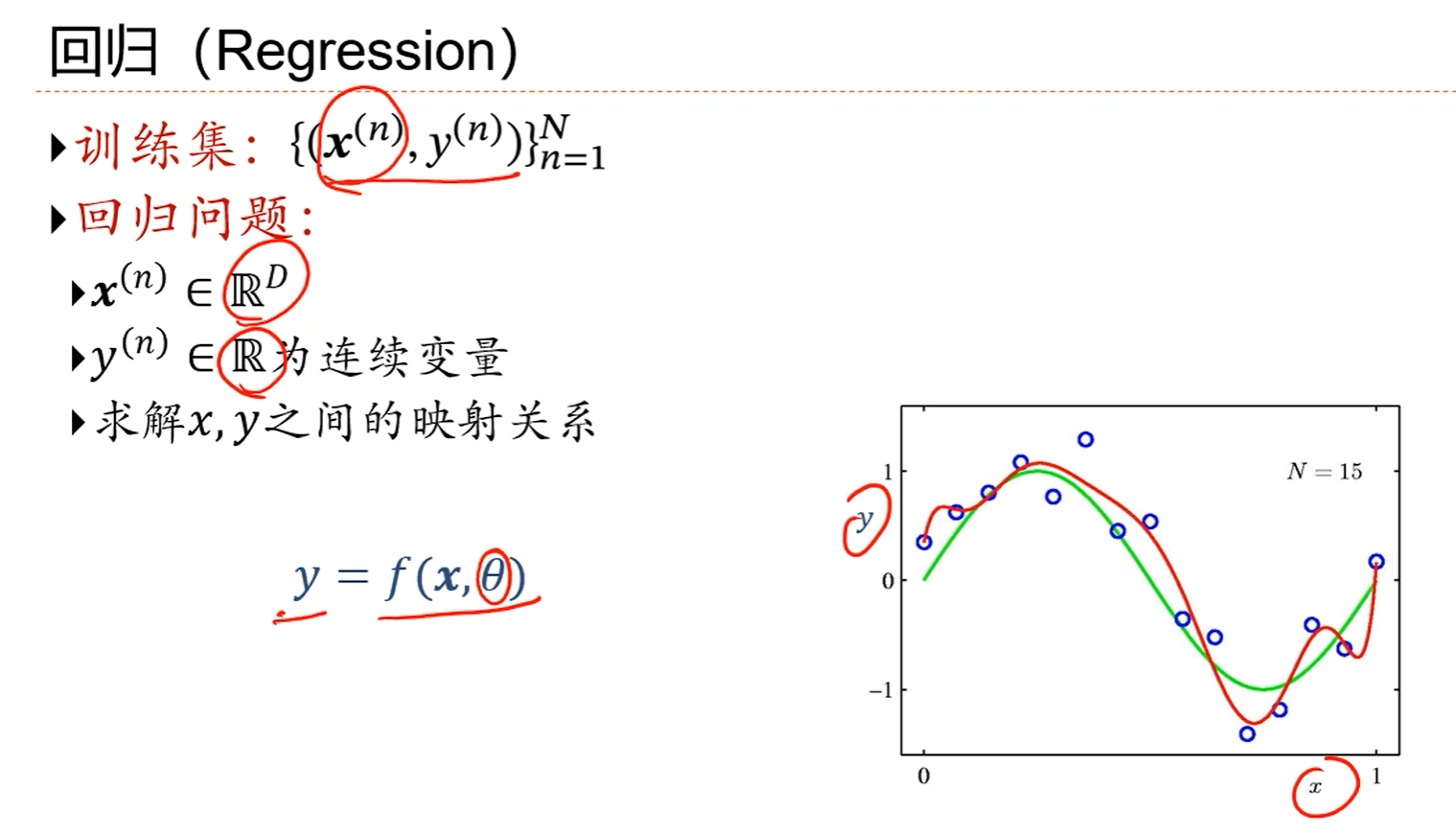
注解:
1.在这个例子中,x是个一维的标量,在很多问题中,x是一个一维的向量。
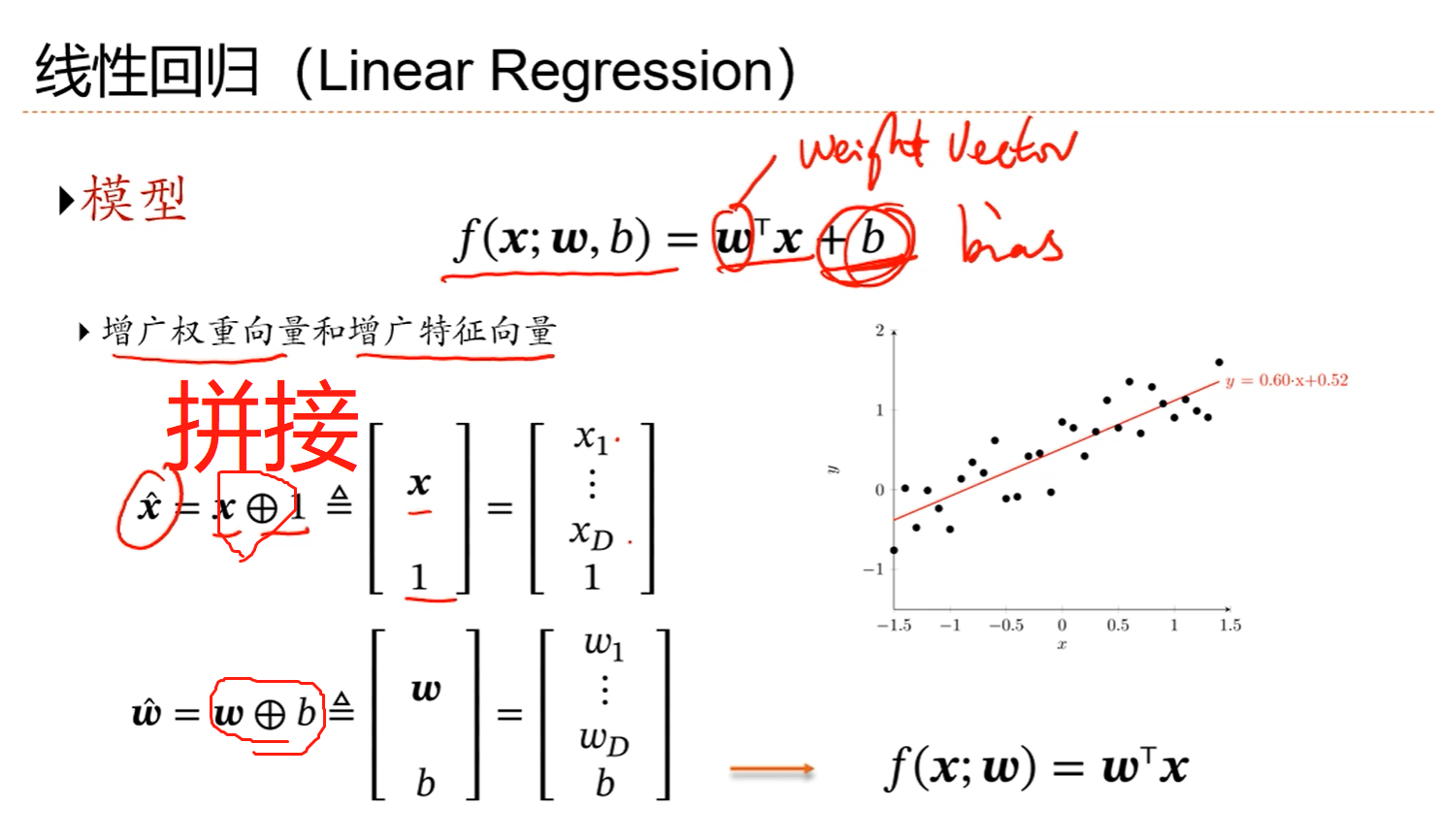
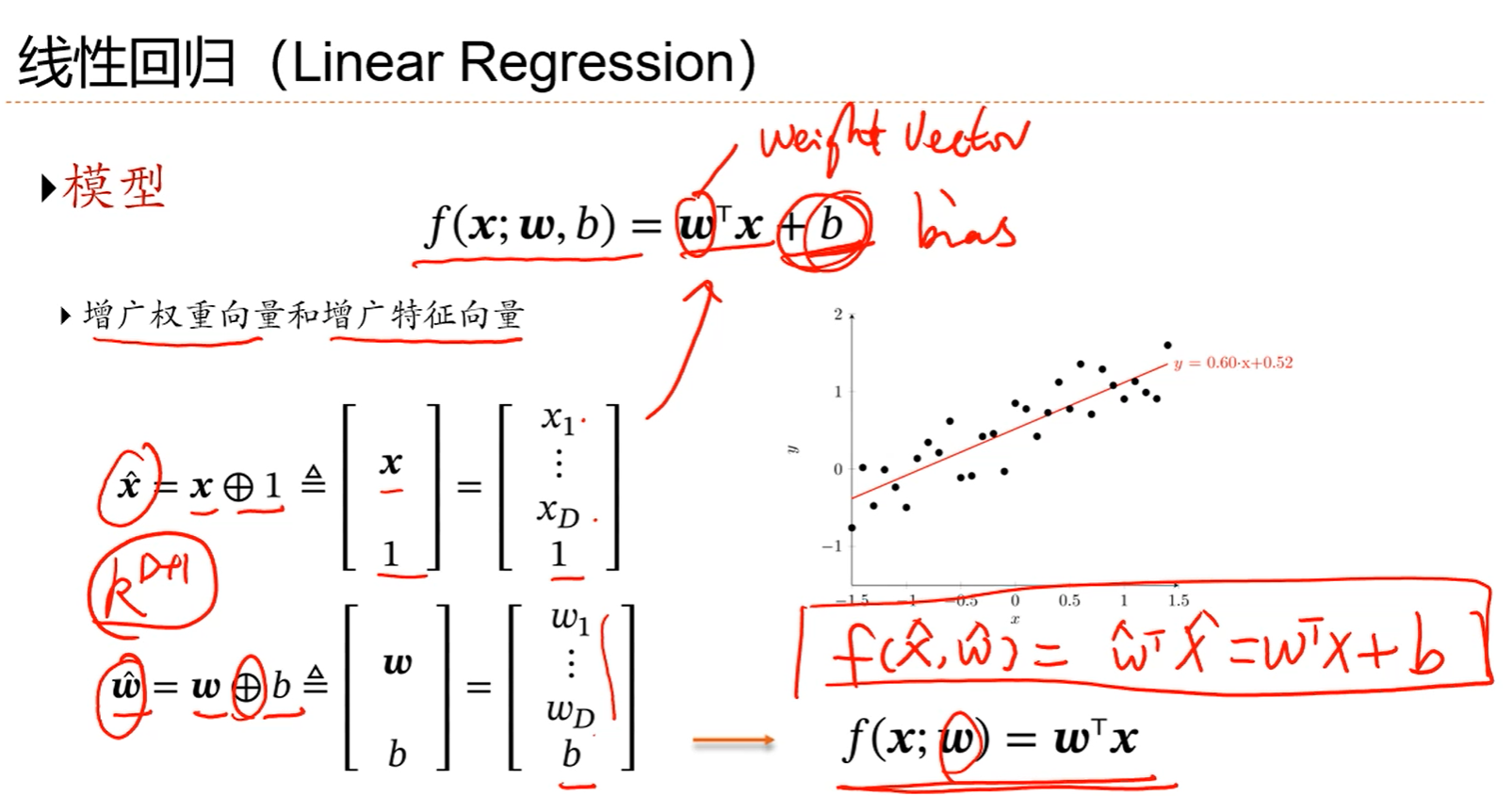
注解:
1.如果不加偏置,相当于模型穿过原点,如果加上偏置,相当于直线上移了一点。
2.可以通过增广的权重向量和增广的特征向量把在形式上b消除掉。
3.如果只有一个变量,就是一维线性回归,如果是多个自变量量,或者说是多个特征,就是多维线性回归。

注解:
1.为了简便起见,把损失函数表达式中求平均的分母N去掉了。
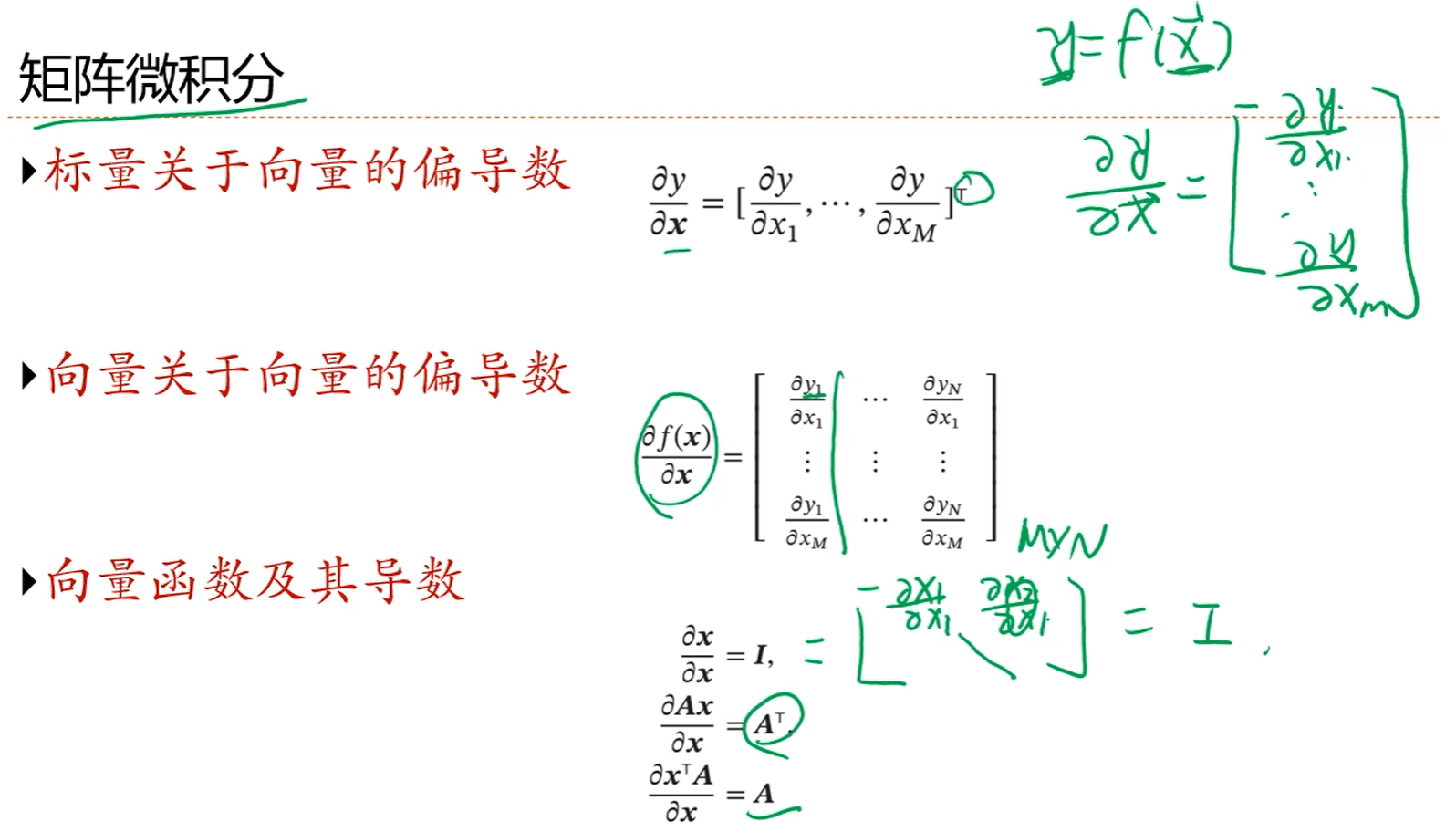

注解:
1.这个解法也叫参数的最小二乘解。
2.但是这个解法在系数矩阵(B)不满秩的时候是没有最小二乘解的。
最小二乘解方程组的一个类比:
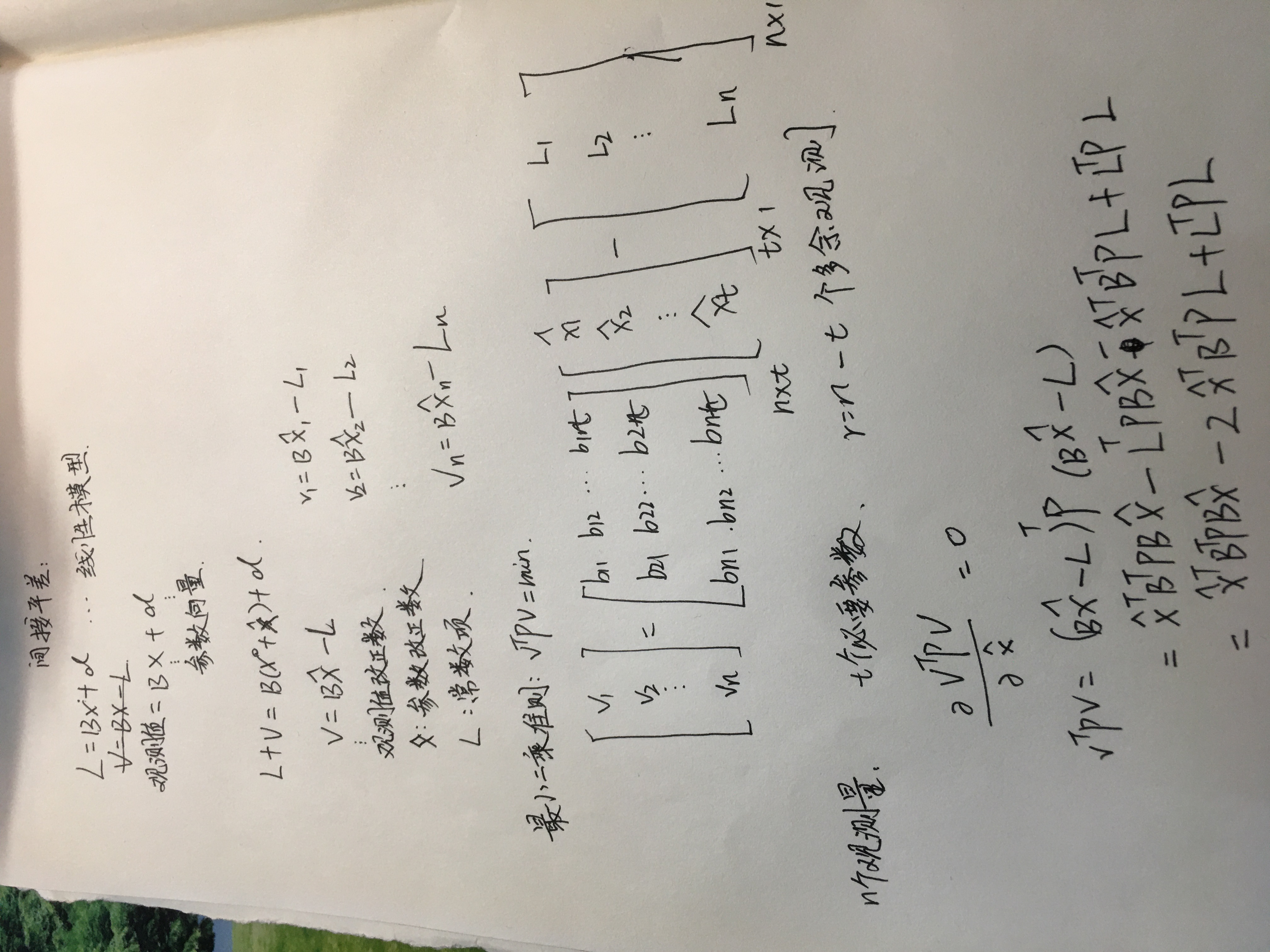

2.但是这个解法在系数矩阵(B)不满秩的时候是没有最小二乘解的,那此时的解决办法如下:
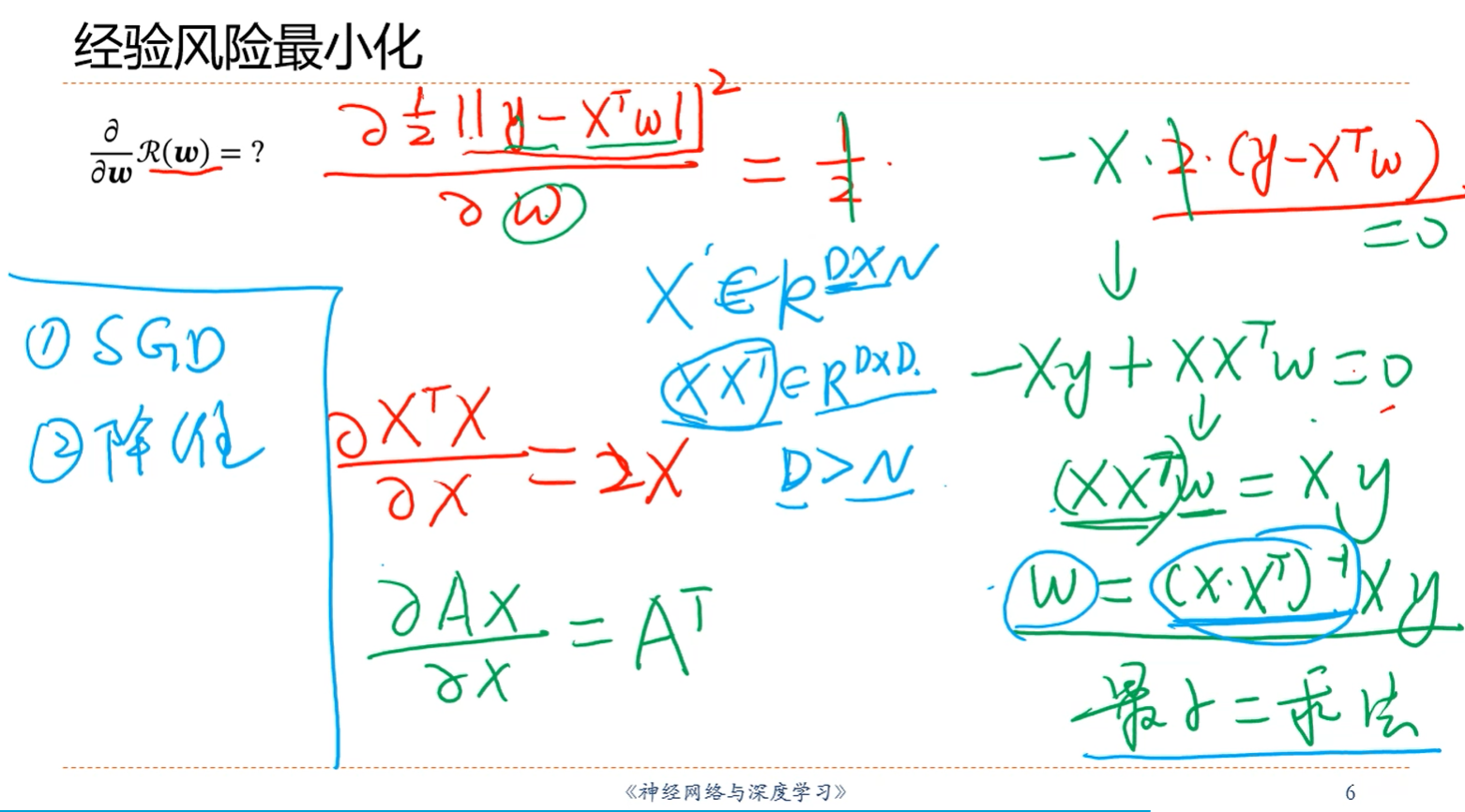
注解:
1.方法一:不使用最小二乘,即不使用BTPB=min,而使用随机梯度下降的办法,即一个样本一个样本的遍历。
2.方法二:降维度。当每个样本的维度D大于样本数量的时候,矩阵不满秩,有无穷多解或者说没有唯一解,那此时降低样本的维度,降到小于样本的数量时为止,此时方程个数会大于样本维度,BTPB会变成满秩矩阵,即会有最小二乘解。
3.思考一个问题:为什么方程数小于参数个数的时候,或者说参数个数(特征数量)大于方程数量(样本数量)的时候,会造成BTPB秩亏?

注解:
1.特征之间存在共线性,就意味着3个方程3个未知数的方程组里面,会因为其中两个特征之间的线性关系,而使得方程组变成2个方程。这就会使得BTPB这个t*t的系数矩阵秩亏,不满秩。这在深度学习中叫做特征(x1,x2,x3)冗余,就是说特征有冗余性。
2.假如存在两个特征xi和xj之间有线性关系,那么它们的权重组合可能会出现一种情况:当权重同时变的非常大的时候,它们的权重组合仍然趋近于0(就是说权重同时发生变化的时候,结果可能会不发生变化).此时,权重之解会变得很不稳定。x很小的扰动会造成解有很大的变化(?)。这样的话,就希望对w的取值进行一个约束,即使存在某种共线问题,也希望它的取值不要很大。

注解:
1.约束项就叫做正则化项,λ叫做正则化项系数。是在学习之前就人工设置一个超参数。

注解:
1.相当于是对XXT这个矩阵的对角线上的值全部加上一个小值λ,然后再求逆。
2.这样就算是XXT不可逆,但是对角线上同时加上一个大于0的小正数之后,它就变得可逆了,此时最小二乘解就一定是存在的了。这种方法在统计学上对应一个方法,叫做“岭回归”。
3.w*的求解过程:
本节小结:用一个线性回归的例子讲解了线性回归的过程,包括方程组的列法,解法。以及利用最小二乘解线性回归方程组的方法,讨论了矩阵何时秩亏(方程个数小于未知数个数的时候,也就相当于是样本观测量少于特征数的时候),对利用最小二乘准则化简之后的方程,其系数矩阵不满秩的时候怎样做。不满秩的时候加上一个正则项就行了,这个方法也叫岭回归。在深度学习中是说加入一个惩罚项,在统计中,叫做岭回归。其本质是在秩亏矩阵的对角线上同时加上要给小正数,以对秩亏矩阵进行改造,改善秩亏的现状,使秩亏方程组变得有解。