selenium如何操作页面树状列表??举个例子:我要怎么操作如下图所示的树状结构列表?我要对这个树状结构列表做什么操作?

一、思路
1.根据driver.find_element_by_xpath(‘//*[@id="vehGroupTree_1_switch"]’).click() 选中顶级节点;如上图的XX管理(id属性为"vehGroupTree_1_switch"),获取XX管理的id属性;
2.观察节点之间的规律;如上图的id属性的数字部分逐级+1
3.获取树状结构列表所有显示内容?问题:在获取树状结构列表内容的时候,节点没有展开是否可以获取得到?
4.获取树状结构列表分组数目,包括子集?
5.遍历展开所有节点?
二、操作
1.遍历点击“+”按钮,展开树状结构列表的子集
a = 'vehGroupTree_1_switch' # 顶级节点的id属性 b = a.split('_') # 拆分id属性 c = [] # 存放id属性的数字部分列表 e = [] # 存放生成的id属性 # 生成id属性的数字部分
for x in range(2,21): # 从2开始遍历,避免点击到顶级节点,使后续节点获取不到属性,导致报错;21为树状结构列表内容总数n+1(总数为n) c.append(x) print(c)
# 组合id属性 for i in c: g = b[0] + '_' + str(i) + '_' + b[2] # 组合 : e.append(g) print(g) print(e) # 遍历点击“+”按钮,展开树状结构列表的子集 for k in e: print(k) print("//*[@id='" + k + "']") d.find_element_by_xpath("//*[@id='" + k + "']").click()
2.获取树状结构列表分组数目,包括子集,并获取列表的所有内容
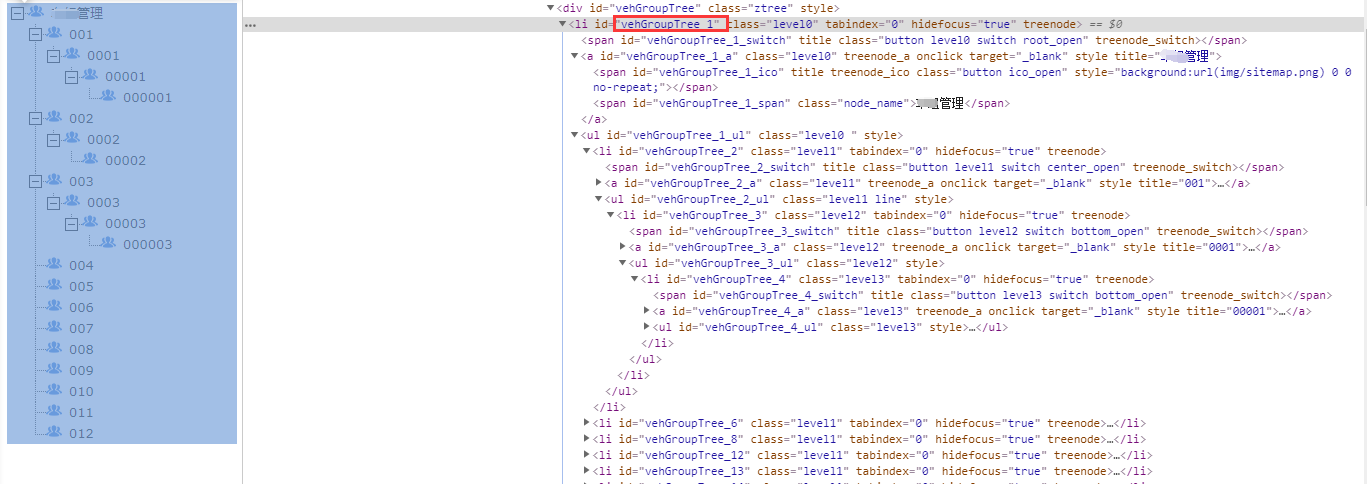
注意:如果没有所有子集展示出来,是获取不到子集内容的(统计包括子集在内的总数)
a = d.find_elements_by_xpath('//*[@id="vehGroupTree_1"]') # 定位到整个树状结构列表元素 b = [] for p in a: c = p.text b.append(a) print(c, p.get_attribute("href")) # 打印遍历标签出来的内容 print(b) print(b[0].split(' ')) # 以分隔符拆分 print(len(b[0].split(' '))) # 统计
3、贴上完整代码
from selenium import webdriver import time d = webdriver.Chrome() d.maximize_window() d.get(url) d.find_element_by_xpath('//*[@id="userName"]').send_keys(username) d.find_element_by_xpath('//*[@id="userPwd"]').send_keys(passworld) d.find_element_by_xpath('//*[@id="login"]').click() time.sleep(2) d.find_element_by_xpath('//*[@id="menu_ul"]/li[5]/a').click() d.switch_to_frame('mainframe2') d.find_element_by_xpath('//*[@id="nav-accordion"]/li[2]/a').click() d.switch_to_frame('mainframe') d.switch_to_frame('vehIframe') a = 'vehGroupTree_1_switch' b = a.split('_') c = [] e = [] for x in range(2,21): c.append(x) #print(c) for i in c: g = b[0] + '_' + str(i) + '_' + b[2] e.append(g) #print(g) #print(e) # 遍历点击展示子集节点 for k in e: #print(k) #print("//*[@id='" + k + "']") d.find_element_by_xpath("//*[@id='" + k + "']").click() he = d.find_elements_by_xpath('//*[@id="vehGroupTree_1"]') lists = [] for p in he: a = p.text lists.append(a) print(a, p.get_attribute("classname")) # 打印遍历标签出来的内容 print(lists) print(lists[0].split(' ')) print(len(lists[0].split(' ')))