我们先来讲一个故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢?从前有座山,山里有座庙,庙里有个老和尚讲故事,讲的什么呢.....
递归函数表示如下:
def story(): s = """ 从前有个山,山里有座庙,庙里老和尚讲故事, 讲的什么呢? """ print(s) story() story() # 递归函数有最大递归深度,超过便会报错
初识递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
- 递归的定义-----在一个函数里再调用这个函数本身
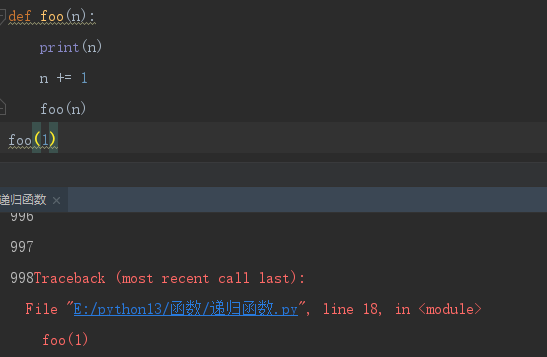
- 递归的最大深度-----997
递归函数如果不受外力的阻止会一直执行下去。但是我们之前已经说过关于函数调用的问题,每一次函数调用都会产生一个属于它自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题,于是python为了杜绝此类现象,强制的将递归层数控制在了997。
再谈递归
来看例子:
age(4) = age(3) + 2 age(3) = age(2) + 2 age(2) = age(1) + 2 age(1) = 40 # 递归函数 def age(n): if n == 1: return 40 else: return age(n-1)+2 print(age(4))
计算阶乘:n! = 1x2x3x......xn 用函数fact(n)表示,可以看出: fact(n) = n! = 1 x 2 x 3 x ... x (n-1) x n = (n-1)! x n = fact(n-1) x n 所以,fact(n)可以表示为n x fact(n-1),只有n=1时需要特殊处理。 # 递归函数 def fact(n): if n == 1: return 1 return fact(n-1) * n print(fact(3))
递归优化 python中没有对递归进行优化
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。可以试试fact(1000):
>>> fact(1000) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 4, in fact ... File "<stdin>", line 4, in fact RuntimeError: maximum recursion depth exceeded
解决递归调用栈溢出的方法是通过尾递归优化,事实上尾递归和循环的效果是一样的,所以,把循环看成是一种特殊的尾递归函数也是可以的。
尾递归是指,在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
上面的fact(n)函数由于return n * fact(n - 1)引入了乘法表达式,所以就不是尾递归了。要改成尾递归方式,需要多一点代码,主要是要把每一步的乘积传入到递归函数中:
def fact(n): return fact_iter(n, 1) def fact_iter(num, product): if num == 1: return product return fact_iter(num - 1, num * product)
可以看到,return fact_iter(num - 1, num * product)仅返回递归函数本身,num - 1和num * product在函数调用前就会被计算,不影响函数调用。
fact(5)对应的fact_iter(5, 1)的调用如下:
===> fact_iter(5, 1) ===> fact_iter(4, 5) ===> fact_iter(3, 20) ===> fact_iter(2, 60) ===> fact_iter(1, 120) ===> 120
尾递归调用时,如果做了优化,栈不会增长,因此,无论多少次调用也不会导致栈溢出。
遗憾的是,大多数编程语言没有针对尾递归做优化,Python解释器也没有做优化,所以,即使把上面的fact(n)函数改成尾递归方式,也会导致栈溢出。
小结
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
针对尾递归优化的语言可以通过尾递归防止栈溢出。尾递归事实上和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环。
Python标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出的问题。