(mathtt{Link})
(mathtt{Description})
给定一个无向连通图,不能走已经经过的点,可以回溯,每到一个新点记录编号,求字典序最小的编号序列。
(mathtt{Data} ext{ } mathtt{Range})
点数 (n) 和边数 (m) 的关系:(m in {n - 1, n})
(1 le n le 5 imes10^5)
(mathtt{Solution})
看完这题后没啥思路……但一看 (m in {n - 1, n}),感觉到好像不太对。也就是这张图只可能是一个树或者一个基环树?
那就分情况讨论呗。
(m = n - 1)
也就是树。
直接从1号节点开始,从小到大遍历出边的顶点进行dfs即可。
然后,就没有然后了……
这个竟然占了 (60 exttt{pts}),划算到爆炸(
(m = n)
基环树。
基环树就是树连了一条边,也就是树中带一个环。
首先考虑将环上的所有节点标记上:
bool flcyc;
void dfscyc(int u, int fa) {
vis[u] = true;
for (int i = head[u]; i; i = e[i].nxt) {
int v = e[i].v;
if (v != fa) {
if (vis[v]) {
flcyc = cyc[v] = cyc[u] = true;
return ;
}
dfscyc(v, u);
if (cyc[v] && flcyc) {
if (cyc[u])
flcyc = false;
cyc[u] = true;
return ;
}
}
}
}
然后可以想到,基环树中一定有一条边没有走过。(并且这条边在环上)
这个其实很好理解,基环树上的环的边如果都走过,那就不可能满足 每个点除了第一次访问或者回溯不能再次访问 这一题目条件了。
那么我们可以暴力删边跑 (m = n - 1),(mathcal{O}(n^2))。这个能过弱化,但是本题数据显然过不了,考虑在dfs上做手脚。
首先从 (1) 开始一直dfs,直到到达在环上的节点。
我们定义一次“反悔操作”为对于一个节点,没遍历完所有子节点就回到上一个节点的操作。
显然,(m = n - 1) 时不需要,也不能进行反悔操作(否则会有点到不了),但是 (m = n) 可以反悔一次使得答案更优。(不能反悔两次)
理论上讲太晦涩,我们举个例子。
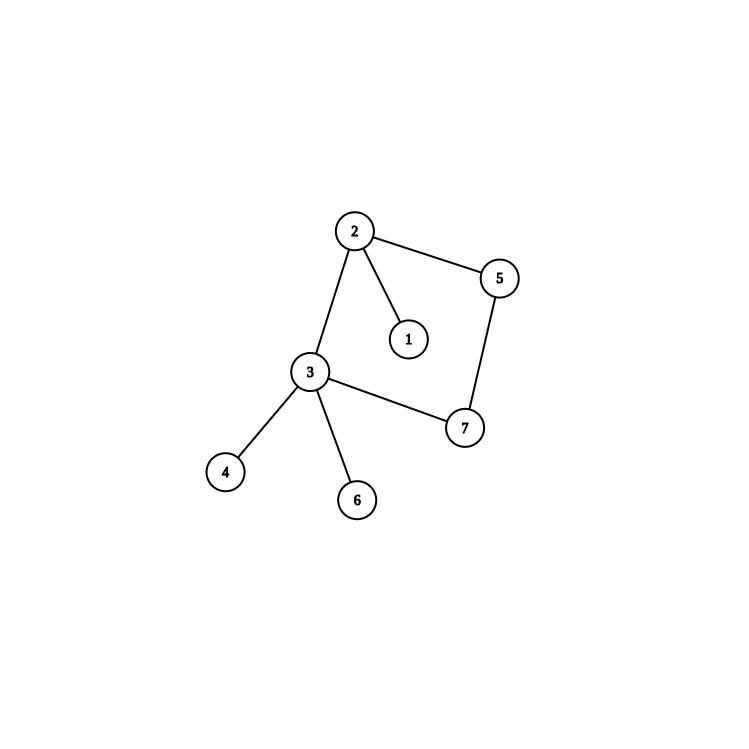
这张图如果按照正常dfs跑,答案是1 2 3 4 6 7 5
但是如果在3跑完4和6的时候,使用反悔大法,退到2节点,然后继续,答案就是1 2 3 4 6 5 7,显然后者更优。
那么现在问题来了,反悔只能用一次,该用在什么时候呢?
首先,如果你还有不在环上的孩子没走完,你能反悔吗?不能。如果你现在反悔,那么那些不在环上的孩子城市就永远无法到达。
换句话说,所有不在环上的孩子走完,只剩一个在环上的孩子,你才可以选择反悔。
那剩下的问题就简单了。现在只需要考虑只有一个没走完的孩子在环上的点能否反悔。
首先来看看反悔的本质能给我们带来什么好处吧。
一次反悔,能让你反悔到上一个还有孩子没走完的祖先的下一个要走的孩子。
我们把没反悔之前本来要走的节点记为 (p),上一个还有孩子没走完的祖先的下一个要走的孩子(其实就是反悔到的位置)记为 (q)。
比如上边那张图,本来我要遍历到 (p = 7) 了,结果反悔到了上一个还没有走完孩子的祖先 (2),它下一个要走的孩子是 (q = 5).
那么字典序本来这个要填(p = 7),现在因为反悔要填 (q = 5) 了。
字典序前面的遍历序列已经确定,而字典序又是在前面的做主,那么显然决定字典序的只在于 (p) 和 (q) 的大小关系,哪个小对应的字典序就小。因此,如果 (q < p),就可以得到一个更小的字典序,也就是说这次反悔划算。如果 (q > p),那就不划算了。
还有一个问题:是早反悔好还是晚反悔好呢?
当然是早反悔好了!早反悔,可以把字典序越前面的数变小,那么整个字典序显然比晚反悔优。
总结一下,当同时满足以下三个条件时:
- 之前还没反悔过;
- 当前节点 (u) 有且仅有一个没遍历过的儿子 (p),且 (p) 在环上;
- 要反悔到的位置(上一个还有孩子没走完的祖先的下一个要走的孩子) (q) 满足 (q < p)。
那就立刻反悔。
其他情况正常dfs即可,那么 (mathtt{Sol}) 就这么华丽丽的结束了。
(mathtt{Time} ext{ } mathtt{Complexity})
暴力删边: (mathcal{O}(n^2)),较紧。
正解:(mathcal{O}(nlog n))。
带一个 (log) 是因为dfs的时候要从小到达选择出边点。有两种解决方法:
- dfs前把所有边按照顶点排序再插入
- dfs中维护一个单调队列
不管哪种,复杂度都会带一个 (log)。
ps:据说可以用一种类SA的基数排序思想使得 (log) 降掉。整体时间复杂度可以降为 (mathcal{O}(n))。不过常数较大……
(mathtt{Code})
/*
* @Author: crab-in-the-northeast
* @Date: 2020-11-28 10:37:32
* @Last Modified by: crab-in-the-northeast
* @Last Modified time: 2020-11-29 17:25:54
*/
#include <bits/stdc++.h>
inline int read() {
int x = 0;
bool f = true;
char ch = getchar();
while (ch < '0' || ch > '9') {
if (ch == '-')
f = false;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 1) + (x << 3) + ch - '0';
ch = getchar();
}
if (f)
return x;
return ~(x - 1);
}
const int maxn = 500005;
const int maxm = 500005;
const int maxinf = 0x3f3f3f3f;
struct edges {
int v, nxt;
}e[maxm << 1];
int head[maxn], ecnt;
int ans[maxn], cnt;
bool vis[maxn], cyc[maxn];
inline void insert(int u, int v) {
e[++ecnt] = (edges){v, head[u]};
head[u] = ecnt;
return ;
}
bool flcyc;
void dfscyc(int u, int fa) {
vis[u] = true;
for (int i = head[u]; i; i = e[i].nxt) {
int v = e[i].v;
if (v != fa) {
if (vis[v]) {
flcyc = cyc[v] = cyc[u] = true;
return ;
}
dfscyc(v, u);
if (cyc[v] && flcyc) {
if (cyc[u])
flcyc = false;
cyc[u] = true;
return ;
}
}
}
}
bool fl;
void dfs(int u, int fa, int back) {
std :: priority_queue <int, std :: vector <int>, std :: greater <int> > q;
vis[u] = true;
ans[++cnt] = u;
for (int i = head[u]; i; i = e[i].nxt) {
int v = e[i].v;
if (v != fa && !vis[v])
q.push(v);
}
while (!q.empty()) {
int v = q.top();
q.pop();
if (!fl && cyc[v] && q.empty() && back < v) {
fl = true;
return ;
}
if (!vis[v])
dfs(v, u, (!q.empty() && cyc[u]) ? q.top() : back);
}
}
int main() {
int n = read(), m = read();
for (int i = 1; i <= m; ++i) {
int u = read(), v = read();
insert(u, v);
insert(v, u);
}
dfscyc(1, 1);
std :: memset(vis, 0, sizeof(vis));
dfs(1, 1, maxinf);
for (int i = 1; i <= cnt; ++i)
std :: printf("%d ", ans[i]);
puts("");
return 0;
}
(mathtt{More})
基环树找环这种基本操作一定要会,然后考场上别想复杂,大胆暴力 (n ^ 2) 是可以过朴素数据的。
类SA的基数排序优化就不写了。因为常数挺大的,写了并没有什么用(