一. 啥是索引:
索引是排好序的数据结构。 这里关键是有序,数据结构
二.索引的结构
1. 索引为何不用二叉树结构
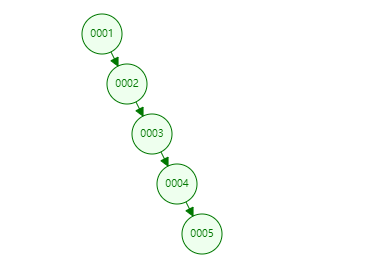
原因:当索引字段递增时,如主键索引,二叉树会退化成一个链表,如果是数据有几百上千万,那链表就会很长,查询数据如果在链表最末尾,那就相当于全表扫描了:如图:
2. 索引为何不用红黑树,红黑树可以通过左右旋转进行平衡:
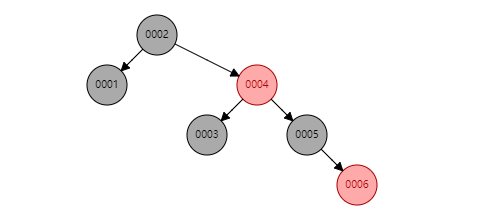
原因:考虑树的高度,假如数据有100万,索引都是递增的,那么会导致树的高度非常高,红黑树查询的顺序:如查找0005号数据,会先从根节点开始查询,比根节点数字大,查询根的右节点,之后比较0004,以此类推,每次加载根节点都是一次IO操作
所以,树的深度越深,那么IO的次数越高,性能越低;解决方案:红黑树一个节点就占用内存的一块区域,如果我在这个区域中,存放多个索引的值,在mysql中,节点存放索引值的内存,叫做页大小,pageSzie,mysql的默认页大小是16kb,因此如果只放一个
索引就浪费了,假如一个索引的大小是8Byte,索引之间的区域是6byte,那么一个页,大概可以存16000/(8+6) 大约 711个索引,因此引出了B-树和B+树,如果高度是3的树,那么大约可以存 711x711x711大约等于3千万数据,所以大大减少了IO的操作
3. 索引为何不是B-树:

由于Inodb的索引文件和数据是在同一个文件中,如果按照B-树的结构,一个页是16kB,如果数据大小就是8kB的话,那么一个页能存的数据就只有2个索引了,这样一样会导致树的深度变高,此外,索引的每个节点的数据都不重复
叶子节点也没指向下一个节点,在范围查询中,性能就会很差,因此B+树在此基础上做了优化:
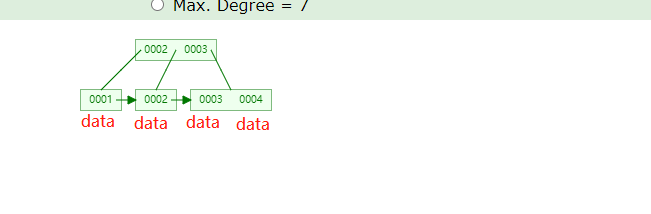
在B+树中,只有叶子节点才会存数据,非叶子节点不会存数据,叶子节点拥有所有的索引值,并且每个节点会指向下一个节点,这样做范围查询就非常简单了,如要查询大于0002的数据,定位到0002节点,然后通过它找下一个,一直找下去,因为
叶子节点的数据是排好顺序的,其实它是一个双向链表,上面标识的不完整;
主键索:在Inodb中,叶子节点存放的是data 数据,对于MyIsm,因为他们的索引和数据是分开存的,所以,它的叶子节点存放的是数据地址,因此需要回表查询才能查询到数据
对于非主键索引,叶子节点存的是主键;
啥是非聚簇(集)索引和聚簇(集)索引,对于Inodb那种数据和索引在同一个文件的就是聚簇索引,对于MyIsm就是非聚簇索引
思考1:为何索引要求是最好是递增的整型? 索引如果不是递增的,新增数据时,树的结构需要不断的调整,这个很费性能,用整型比字符串的比较大小的性能更高
思考2:联合索引是怎么样存储的呢?
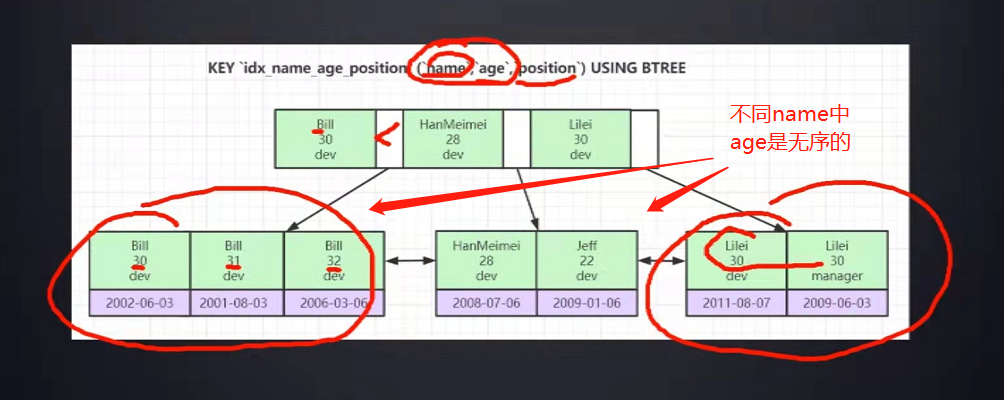
索引的结构是B+树,那么联合索引的结构本质还是B+树,将上面主键索引换成联合索引怎么弄,索引主要是有序,联合索引只要能比较大小即可,如name,age进行联合索引,字符串name的比较是一个个字符比较大小,如果都相同
再比较第二个值,也就是age,因此遵循最左匹配原则,如果查询条件是age>30,因为在叶子节点中,name是有顺序的,而对于age是没有顺序的,只有同名的数据中,age才是有顺序的,因此会导致全表扫描; 联合索引结构如下
我们再看看B+树的查询:

如果我要查询的索引数据是20,那么先从根节点找起,将所有根节点数据加载到内存,然后二分查找,发现20在15和56之间,根据之间的内存地址,找到下一个节点的数据,也就是 15 20 49这个page的数据,
根据同样的逻辑去比较,发现20就是所找的数据,然后找到根节点20对应的data
附加:Inodb和MyIsm的存储区别:
