1. 什么是Phoenix
Phoenix完全使用Java编写,将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。Phoenix主要能做以下这些事情:
将SQL查询编译为HBase扫描scan
确定scan的开始和停止位置
将scan并行执行
将where子句中的谓词推送到服务器端进行过滤
通过服务器端挂钩(称为协处理器co-processors)执行聚合查询
除了这些之外,phoenix还进行了一些有趣的增强,以进一步优化性能:
二级索引,以提高非行键查询的性能(这也是我们引入phoenix的主要原因)
跳过扫描过滤器来优化IN,LIKE和OR查询
可选的对行键进行加盐以实现负载均衡,避免热点
2. Phoniex架构
Phoenix结构上划分为客户端和服务端两部分:
客户端包括应用程序开发,将SQL进行解析优化生成QueryPlan,进而转化为HBase Scans,调用HBase API下发查询计算请求,并接收返回结果;
服务端主要是利用HBase的协处理器,处理二级索引、聚合及JOIN计算等。
Phoiex的旧版架构采用重客户端的模式,在客户端执行一系列的parser、query plan的过程,如下图所示:
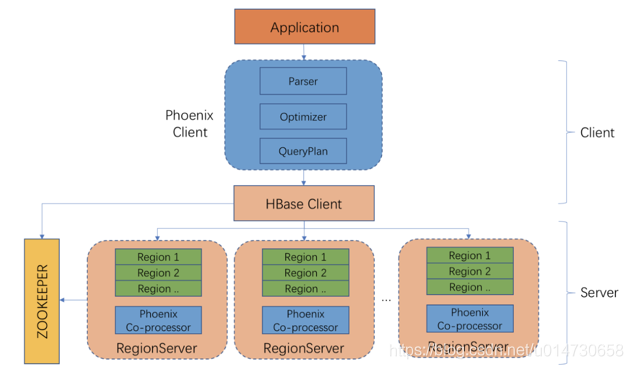
这种架构存在使用上的缺陷:
应用程序与Phoenix core绑定使用,需要引入Phoenix内核依赖,一个单独Phoenix重客户端集成包已达120多M;
运维不便,Phoenix仍在不断优化和发展,一旦Phoenix版本更新,那么应用程序也需要对应升级版本并重新发布;
仅支持Java API,其他语言开发者不能使用Phoenix。
因此,社区进行改造,引入了新的“轻客户端”模式:
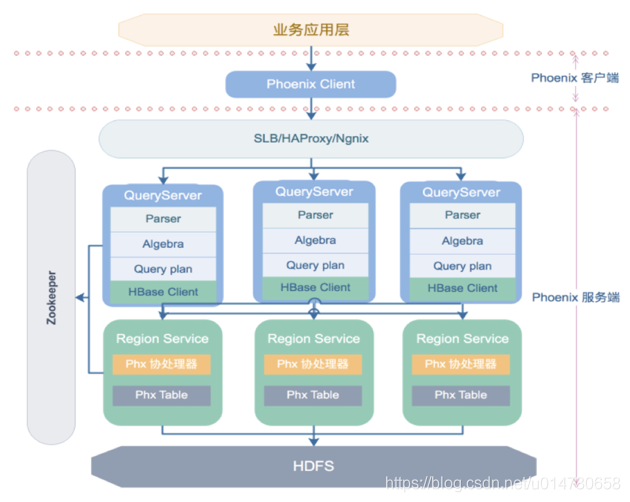
轻客户端架构将Phoenix分为两部分:
客户端是用户最小依赖的JDBC驱动程序,与Phoenix依赖进行解耦,支持Java、Python、Go等多种语言客户端;
将QueryServer部署为一个独立的的HTTP服务,接收轻客户端的请求,对SQL进行解析、优化、产生执行计划;
3. 为什么需要用二级索引?
对于HBase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询。如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄。对于较大的表,全表扫描的代价是不可接受的。但是,很多情况下,需要从多个角度查询数据。例如,在定位某个人的时候,可以通过姓名、身份证号、学籍号等不同的角度来查询,要想把这么多角度的数据都放到rowkey中几乎不可能(业务的灵活性不允许,对rowkey长度的要求也不允许)。所以,需要secondary index(二级索引)来完成这件事。secondary index的原理很简单,但是如果自己维护的话则会麻烦一些。现在,Phoenix已经提供了对HBase secondary index的支持。
4. 二级索引分类
索引最常用的三个类型:覆盖索引、全局索引、本地索引。
1) 覆盖索引 Covered Index
如果创建的是覆盖索引,那么查询语句中的条件字段、返回字段都必须创建过索引,否则就会触发full table scan。如:
create index coverindex user_index on user (name) include (cellphone);
因此它的特点是:只需要通过索引就能返回所要查询的数据
2) 全局索引 Global indexes
global是默认的索引格式。
全局索引适用于多读少写的场景,在写操作上会给性能带来极大的开销,因为所有的更新和写操作(DELETE,UPSERT VALUES和UPSERT SELECT)都会引起索引的更新,在读数据时,Phoenix将通过索引表来达到快速查询的目的。如;
CREATE INDEX DWD_MS_BASE_COMP_GEO_COMPNAME_INDEX ON DWD_MS_BASE_COMP_GEO ("compName"); CREATE INDEX USERIDINDEX ON CSVTABLES(USERID);
它有一个缺陷,如果查询语句中的条件字段或返回字段不是索引字段,就会触发全表扫描。如:
SELECT USERID,KEYWORD FROM CSVTABLES WHERE USERID='9bb8b2af92df3c3'
解决办法有两个:
一是和覆盖索引一样,创建索引时把相关字段include进来。
CREATE INDEX MYINDEX ON CSVTABLES(USERID) INCLUDE(KEYWORD);
二是强制使用索引
SELECT /*+ INDEX(my_table my_index) */ "v1" FROM my_table WHERE "v3" = '13406157616';
这样的查询语句会导致二次检索数据表,第一次检索是去索引表中查找符合v3='13406157616'的数据,这时候发现 KEYWORD 字段并不在索引字段中,会去CSVTABLES 表中第二次扫描,
因此只有当用户明确知道符合检索条件的数据较少的时候才适合使用,否则会造成全表扫描,对性能影响较大。
3) 本地索引 Local Indexing
与Global Indexing不同,当使用Local Indexing的时候即使查询的所有字段都不在索引字段中时也会用到索引进行查询(这是由Local Indexing自动完成的)。
本地索引适用于写多读少的场景,Phoneix在查询时会自动选择是否使用本地索引,为避免进行写操作所带来的网络开销,索引数据将放到表数据所在的服务器中。由于无法预先确定region的位置,所以在读取数据时会检查每个region上的数据因而带来一定性能开销。
CREATE LOCAL INDEX MYINDEX ON CSVTABLES(USERID);
5. 可变索引和不可变索引
1) 不可变索引
immutable index,不可变索引,适用于数据只增加不更新并且按照时间先后顺序存储(time-series data)的场景,如保存日志数据或者事件数据等。不可变索引的存储方式是write one,append only。当在Phoenix使用create table语句时指定IMMUTABLE_ROWS = true表示该表上创建的索引将被设置为不可变索引。Phoenix默认情况下如果在create table时不指定IMMUTABLE_ROW = true时,表示该表为mutable。不可变索引分为Global immutable index和Local immutable index两种。
2) 可变索引
mutable index,可变索引,适用于数据有增删改的场景。Phoenix默认情况创建的索引都是可变索引,除非在create table的时候显式地指定IMMUTABLE_ROWS = true。可变索引同样分为Global immutable index和Local immutable index两种。
强制走索引
SELECT /*+ INDEX(my_table my_index) */ "v1" FROM my_table WHERE "v3" = '13406157616';
6.upsert 语句
示例语法如下:
UPSERT INTO test.targetTable(col1, col2) SELECT col3, col4 FROM test.sourceTable WHERE col5 < 100
UPSERT INTO foo SELECT * FROM bar;