一、鸭子类型和多态
多态:根据代码类型的具体实现来采取不同的行为。
在go和python中,能够直接体现多态的是接口,最后都执行相同的函数却返回不同的结果。
在python是没有接口类这种类型的,只是为了更好的规范代码而人为定义的,但是这并不影响多态特性的体现。
但是go和python中实现多态的过程却完全不一样。
python从语言的层面来讲,它本身就是一个支持多态的语言。
在go中,函数的参数类型和方法绑定的类型都已经被写死了。
决定行为不同的因素是对象的类型。不同的对象在调用同一个方法的时候会产生不同的行为。
例如在go中:
type Phone interface { call() //接口中有一个call方法 } //定义诺基亚结构体 type NokiaPhone struct { } //实现call方法 func (nokkiaPhone NokiaPhone) call() { fmt.Println("I am Nokia") } //定义苹果结构体 type Iphone struct { } //实现call方法 func (iphone Iphone) call() { fmt.Println("I am iphone") } func main() { //根据接口声明变量 var phone Phone //同一个接口变量就能实现多个结构体中的方法 phone = new(NokiaPhone) //创建一个指定类型的值,并返回该值的指针 phone.call() phone = new(Iphone) phone.call() }
NokiaPhone和Iphone在执行call方法的时候有不同的结果,这就是go中的多态特性,根据类型的不同而产生不同的行为。
在python中决定代码不同行为的,是对象的属性和方法集。
class Animal(object): def run(self): print("Animal is running") class Dog(Animal): def run(self): print("Dog is running") class Cat(Animal): def run(self): print("Cat is running") def run_twice(animal): animal.run() #Animal()是一个实例,只是没有进行赋值 run_twice(Animal()) # Animal is running run_twice(Cat()) # Cat is running run_twice(Dog()) # Dog is running
只要你实现了run方法,不管你是何种类型的对象,都可以调用run_twice函数。
上面这个例子之所以没有展示成接口类的实例,是因为这样能够更好的展示python语言的灵活性。
下面的例子也许会让你有更加深刻的认识。
a = [1,2] #a属于列表 b = [3,4] tuple_s = (6,7) set_s = set([7,8]) a.extend(b) #将一个列表追加到列表a中 print(a) a.extend(tuple_s) #将一个元组追加到列表a中 print(a) a.extend(set_s) #将一个结合追加到列表a中 print(a)
是不是感觉不可以思议,类型不同还可以相互操作。
可以看一下extend的定义:
def extend(self, iterable)
只要是一个可迭代对象就可以。
也就是对于extend函数来说,对象中实现了iter()或者__iter__方法就被操作,而不会去关心你是什么类型。
在静态类型的Go语言中,是类型决定了行为的不同。而在python中是对象的属性和方法集决定了行为不同。
为什么在python中就会如此的随性了?这就需要说到鸭子类型。
在程序设计中,鸭子类型是动态类型的一种风格。
在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由当前方法和属性的集合决定。
维基百科这样定义“鸭子类型”:
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子”
在鸭子类型中,关注的不是对象类型本身,而是它是如何使用的。
鸭子类型是python这个语言在创建之初就定义好的。你像鸭子一样走路,我就可以说你是鸭子,我不会管你是不是鸭子。
鸭子类型让python的语言更加的灵活。
根据多态的不同原理,我们就引出了鸭子类型。
二、抽象基类
abc模块是Abstract base class的缩写。
python是动态语言,动态语言是没有变量的类型的。
实际上,在python中变量只是一个符号而已,它可以指向任何类型的对象。
动态语言无法做类型检查,只能在运行的是获取错误。
鸭子类型与魔法函数构成了python语言的基础。
python本身不是去继承某个类而获取某个特性,而是只需要去实现某个魔法函数,它就是某个类的对象。
比如对象拥有__abs__方法,我们就可以将这个对象视为“int”类型。
不同的魔法函数具有的特性,这种特性在python之中我们又把它叫做协议。
我们在编程的时候,应该尽量去遵循这些协议,这样的代码才比较“python”
在基础的类当中,我们去设定好一些方法,所有继承这个基类的类都必须去覆盖这些方法。
同时抽象基类无法用来实例化。
模拟抽象基类:
class Person: def set(self,key,value): raise NotImplementedError class NewPerson(Person): def set(self,key,value): pass person = NewPerson() person.set("k","v")
如果在New中,没有定义set方法,那么就会报错。
通过父类方法主动抛出异常可以使子类中必须实现set方法,这样就可以实现抽象基类的效果。
但是这种方法必须在调用时才会抛出异常,不能在初始化时就抛出异常。
如果子类中,没有实现set就会报错
from abc import ABCMeta,abstractmethod class Person(metaclass=ABCMeta): @abstractmethod def set(self): pass class NewPeason(Person): pass person = NewPeason() #TypeError: Can't instantiate abstract class NewPeason with abstract methods set
正确的方法:
from abc import ABCMeta,abstractmethod class Person(metaclass=ABCMeta): @abstractmethod def set(self): pass class NewPeason(Person): def set(self): pass person = NewPeason()
在python中如果想要知道一个对象
三、type和isinstance
在python中type和isinstance这两个方法都可以判断对象的类型。
class A: pass class B(A): pass b = B() print(type(b)) #<class '__main__.B'> print(type(b) is B) #True print(type(b) is A) #False print(id(A),id(B)) #2075447987256 2075447956104 #A虽然是B的父类,但是毕竟代表着不同的类型,所以内存地址也是不一样的 print(isinstance(b,B)) #True print(isinstance(b,A)) #True
type虽然可以判断对象的数据类型,但是并不能判断继承关系,
所以推荐使用isinstance,因为type会有不少误区。
在python中"is"是用来判断内存地址是否相同。而"=="用来判断值是否相等。
print(type(b)) #<class '__main__.B'> print(B) #<class '__main__.B'>
四、多重继承
在python新式类中使用的是C3算法来处理多重继承问题。
在python中,属性的继承和方法的继承所遵循的继承顺序是一样的。
首先我们来剖析一下深度优先和广度优先本身存在的问题所在。
(1)深度优先DFS(Depth first)
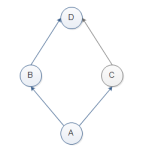
class D: def set(self): print("D") class C(D): def set(self): print("C") class B(D): pass class A(B,C): pass a = A() a.set()
按照深度优先的原则,执行:A>B>D>C,所以a.set()=D
但是在上述代码中,C重写了set方法,但是最后却是调用的D中set方法,
A继承的是B、C,这样C中重写的set方法就没有意义,C中定义的set方法就是多余的了。
在python2.7中依然遵循的是深度优先的原则。
(2)广度优先BFS(Breadth first)
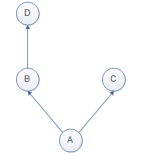
class D: def set(self): print("D") class C:: def set(self): print("C") class B(D): pass class A(B,C): pass a = A() a.set()
按照深度优先的原则,执行顺序:A>B>C>D a.set()=C
但是在上述代码中,虽然B中没有定义set方法,但是D中有啊,也就是B中其实有set方法,凭什么要去C中找了。
此时BD应该看作一个整体。
(3)C3
貌似深度优先:
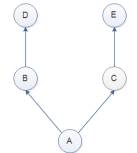
class E: pass class D: pass class C(E): pass class B(D): pass class A(B,C): pass a = A() print(A.mro()) #[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.C'>, <class '__main__.E'>, <class 'object'>]
最终执行顺序:
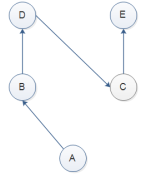
貌似广度优先:
class D: def set(self): print("D") class C(D): def set(self): print("C") class B(D): pass class A(B,C): pass a = A()
继承关系如下:
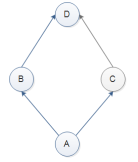
print(a.set()) #C
print(A.mro()) #[<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>]
执行路线如下:
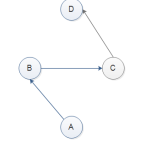
上面只是巧合。
在有些情况下,貌似是广度优先,有些情况又貌似是深度优先,其实是属于C3算法。
五、类方法、静态方法、示例方法
实例方法:在类中定义的方法,实例化之后才可以被调用
静态方法:在类中定义的普通函数,只是改变了作用域的范围,与类之间多了一层绑定的关系。
类方法:在类中定义的普通方法,只是绑定在类上,这样在实例化之前就可以使用,与静态方法类似。
实例方法与静态方法和类方法的最大的不同之处在作用的生命周期不一样。
类方法与静态方法的最大不同之处在于——类方法会自动将类作为参数传进去,
有时候我们不需要将类作为参数传入,你使用类方法就必须传,传进去你又不用,传进去不是多余的吗。
在python中,向函数中传递参数可以不使用而不会报错。同时你不需要为啥要传,这不是浪费资源吗。
类方法和静态方法都是可以继承。

1.对象方法
class Date: def __init__(self,year,month,day): self.year = year self.month = month self.day = day def tomorrow(self,num=1,date_format='%Y/%m/%d'): today_str = "{}/{}/{}".format(self.year,self.month,self.day) tomorrow_datetime = datetime.datetime.strptime(today_str, date_format) + datetime.timedelta(days=num) tomorrow_str = tomorrow_datetime.strftime(date_format) return tomorrow_str def __str__(self): return "{}/{}/{}".format(self.year,self.month,self.day) today = Date(2019,4,17) print(today.tomorrow(-10))
上面我们定义了Date类,然后在里面定义了一个tomorrow对象方法。
2.静态方法
然而我在实例化的时候,我可能不是以Date(2019,4,17)这种手动输入的方式,
而是给你一个字符串,比如"2019-1-10",这个时候我们就需要在实例化的时候先处理这个字符串。
我们可以在初始化的时候进行解析:
def __init__(self,parses_tr): year,month,day = parses_tr.split(split_flag) self.year = int(year) self.month = int(month) self.day = int(day)
这样一来,实例化的时候不就只能传入字符串了吗?这样代码的功能其实被削弱了。
这里为什么不能定义一个对象方法了?这部分操作是在代码实例化过程中被调用,而对象方法是在实例化之后才能被调用。
所以我们可以在外边定义parse_the_date_str专门用来处理这些情况。
class Date: def __init__(self,year,month,day): self.year = year self.month = month self.day = day #obejct method def tomorrow(self,num=1,date_format='%Y/%m/%d'): today_str = "{}/{}/{}".format(self.year,self.month,self.day) tomorrow_datetime = datetime.datetime.strptime(today_str, date_format) + datetime.timedelta(days=num) tomorrow_str = tomorrow_datetime.strftime(date_format) return tomorrow_str def __str__(self): return "{}/{}/{}".format(self.year,self.month,self.day) def parse_the_date_str(parses_tr): split_flag = "/" if "-" in parses_tr: split_flag = "-" elif "." in parses_tr: split_flag = "." y_str,m_str,d_str = parses_tr.split(split_flag) today = Date(int(y_str),int(m_str),int(d_str)) return today today = Date(2019,4,17) print(today) #2019/4/17 print(today.tomorrow()) #2019/04/18 new_date = parse_the_date_str("2019.5.17") print(new_date) #2019/5/17 print(new_date.tomorrow()) #2019/05/18
但是这个方法其实是伴随着Date类而存在的,为啥要独立存在。
那一天我们将方法和类分开,到最后parse_the_date_str是啥我们都可能不知道,
所以我们可以使用静态方法staticmethod.
class Date: def __init__(self,year,month,day): self.year = year self.month = month self.day = day @staticmethod def parse_the_date_str(parses_tr): split_flag = "/" if "-" in parses_tr: split_flag = "-" elif "." in parses_tr: split_flag = "." y_str, m_str, d_str = parses_tr.split(split_flag) today = Date(int(y_str), int(m_str), int(d_str)) return today #obejct method def tomorrow(self,num=1,date_format='%Y/%m/%d'): today_str = "{}/{}/{}".format(self.year,self.month,self.day) tomorrow_datetime = datetime.datetime.strptime(today_str, date_format) + datetime.timedelta(days=num) tomorrow_str = tomorrow_datetime.strftime(date_format) return tomorrow_str def __str__(self): return "{}/{}/{}".format(self.year,self.month,self.day) today = Date(2019,4,17) print(today) #2019/4/17 print(today.tomorrow()) #2019/04/18 new_date = Date.parse_the_date_str("2019.5.17") print(new_date) #2019/5/17 print(new_date.tomorrow()) #2019/05/18
这样我们就将函数的命名空间转移到了类的区域范围了,
虽然在编写代码时,我们一直强调的是解绑,但是必要的绑定还是需要的,不然会影响代码的可读性。
3.类方法
但是上述代码还有一个小的问题。
today = Date(int(y_str), int(m_str), int(d_str))
这里的Date类名写死了,如果哪一天我修改了类名,那整个代码需要修改的地方就非常多了。
因此我们可以采用类方法:
class Date: def __init__(self,year,month,day): self.year = year self.month = month self.day = day @classmethod def parse_the_date_str(cls,parses_tr): split_flag = "/" if "-" in parses_tr: split_flag = "-" elif "." in parses_tr: split_flag = "." y_str, m_str, d_str = parses_tr.split(split_flag) today = cls(int(y_str), int(m_str), int(d_str)) return today #obejct method def tomorrow(self,num=1,date_format='%Y/%m/%d'): today_str = "{}/{}/{}".format(self.year,self.month,self.day) tomorrow_datetime = datetime.datetime.strptime(today_str, date_format) + datetime.timedelta(days=num) tomorrow_str = tomorrow_datetime.strftime(date_format) return tomorrow_str def __str__(self): return "{}/{}/{}".format(self.year,self.month,self.day) today = Date(2019,4,17) print(today) #2019/4/17 print(today.tomorrow()) #2019/04/18 new_date = Date.parse_the_date_str("2019.5.17") print(new_date) #2019/5/17 print(new_date.tomorrow()) #2019/05/18
这个有一个关键变量cls,代表这个类本身。cls只是一个变量名,写self也是可以的。
六、python的自省机制
自省是通过一定的机制查询到对象的内部结构
class User(object): """user doc info""" def __init__(self,name,age): self.name = name self.age = age ming = User("ming",18) #__dict__:以键值对的形式返回对象里面的属性值,通过这些属性信息,我们就可以知道对象内部结构。 print(User.__dict__) # {'__module__': '__main__', # '__init__': <function User.__init__ at 0x0000020206DE7158>, # '__dict__': <attribute '__dict__' of 'User' objects>, # '__weakref__': <attribute '__weakref__' of 'User' objects>, # '__doc__': 'user doc info'} print(ming.__dict__) #{'name': 'ming', 'age': 18} #还可以通过向__dict__中添加键值对,来添加属性 ming.__dict__["sex"] = "boy" print(ming.sex) #boy #dir()可以答应对象中所有的属性和方法,比__dict__更加全面。 print(dir(ming))
七、super真的是继承父类吗?
在编写子类的时候,如果我们不重写__init__构造函数,那么就会默认继承父类的构造函数。
如果我们要重写__init__构造函数,可以重新定义对象的属性。
如果你要继承父类的属性,那么就会全部继承,不可能说只要部分,如果你不要全部,那么就自己定义。
可以使用super()来继承父类的属性。
class Person(object): def __init__(self,name,age): self.name = name self.age = age class NewPerson(Person): def __init__(self,name,age,sex): super().__init__(name,age) #需要全部继承 # super(NewPerson,self).__init__(name, age) # Person.__init__(self,name,age) self.sex = sex #添加新的属性 person = NewPerson("kebi",18) print(person.name)
super真的是继承父类吗?
class A: def __init__(self): print("A") class B(A): def __init__(self): print("B") super().__init__() class C(A): def __init__(self): print("C") super().__init__() class D(B,C): def __init__(self): print("D") super().__init__() if __name__ == "__main__": d = D() print(D.mro()) 执行结果: D B C A #类型A的继承顺序。 [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
如果super继承父类,那么打印结果应该是D > B > A > C
关键在于B这个类:
class B(A): def __init__(self): print("B") super().__init__()
如果super找的父类,那么应该接下来打印A,但是打印的C。
那么super就不是继承父类,而是按照继承规则进行继承。
通过D.mro()可以看到继承顺序为DBCA,与super的继承顺序一样。
之前按照super继承父类的方式,感觉答应结果为D > B > A > C > A,
因为A的__init__被初始化了两次,现在super不是继承父类,问题迎刃而解。
这也从侧片证实super不是继承父类。
八、上下文管理器
在写项目的时候,经常会遇到文件操作、数据库操作,在进行这些操作的时候,时常会忘记关闭连接。
方法1:try..expect...finally
这种做法可以用来做文件操作和数据库操作。
try: print("打开文件") # 这里是一些操作 except KeyError as e: print("key error") finally: print("关闭连接")
方法2:with语句
通过with语句操作文件既可以很巧妙的回避掉文件的关闭问题,但是这种方式如何做数据库的连接了。
with open('maoxian','r',encoding='utf-8') as f: content = f.read() print(content)
方法3.__enter__、__exit__
这两个魔法方法是python专门配合with做上下文管理操作的。
class Sample: def __enter__(self): print("start 获取资源") return self def __exit__(self, exc_type, exc_val, exc_tb): print("exit 释放资源") def do_something(self): print("doing something") with Sample() as s: s.do_something()
#执行结果:
start 获取资源
doing something
exit 释放资源
__enter__会在with语句开始的时候执行,__exit__会在with语句退出的时候执行。
这样不仅自动的关闭数据库,并且只会进行一次连接与关闭操作。
下面是一个操作mysql数据库的实例:
import pymysql mysql_info = { "host":"127.0.0.1", "user":"root", "password":"123", "database":"s8", "charset":"utf8" } class SQLManager(object): """数据库操作""" def __init__(self): self.__conn = None self.__cursor = None def __enter__(self): self.__conn = pymysql.connect(**mysql_info) self.__cursor = self.__conn.cursor() return self def __exit__(self, exc_type, exc_val, exc_tb): self.__conn.close() self.__cursor.close() def get_one_data(self,sql): self.__cursor.execute(sql) ret = self.__cursor.fetchone() return ret def get_some_data(self,sql): self.__cursor.execute(sql) ret = self.__cursor.fetchall() return ret def del_or_update_data(self,sql): self.__cursor.execute(sql) self.__conn.commit() return def create_one_data(self,sql): self.__cursor.execute(sql) self.__conn.commit() last_id = self.__cursor.lastrowid return last_id if __name__ == "__main__": with SQLManager() as m: get_all = m.get_some_data("SELECT id,name FROM info") print(get_all) #((1, '科比'), (2, '毛线'), (3, '小鸟'))
4.contextlib
上述的__enter__、__exit__是在CBV(面向对象编程)中使用,
那如何在FBV(面向函数编程)中使用了,python内置了contextlib包,可以将一个函数变成上下文管理器。
import contextlib @contextlib.contextmanager #将file_open()变成一个上下文管理器 def file_open(): print("file open") yield {} #这是一个生成器 print("file end") with file_open() as f_open: print("file processing") # 执行结果 # file open # file processing # file end
这种方式可以看作是对原生with语句的补充。