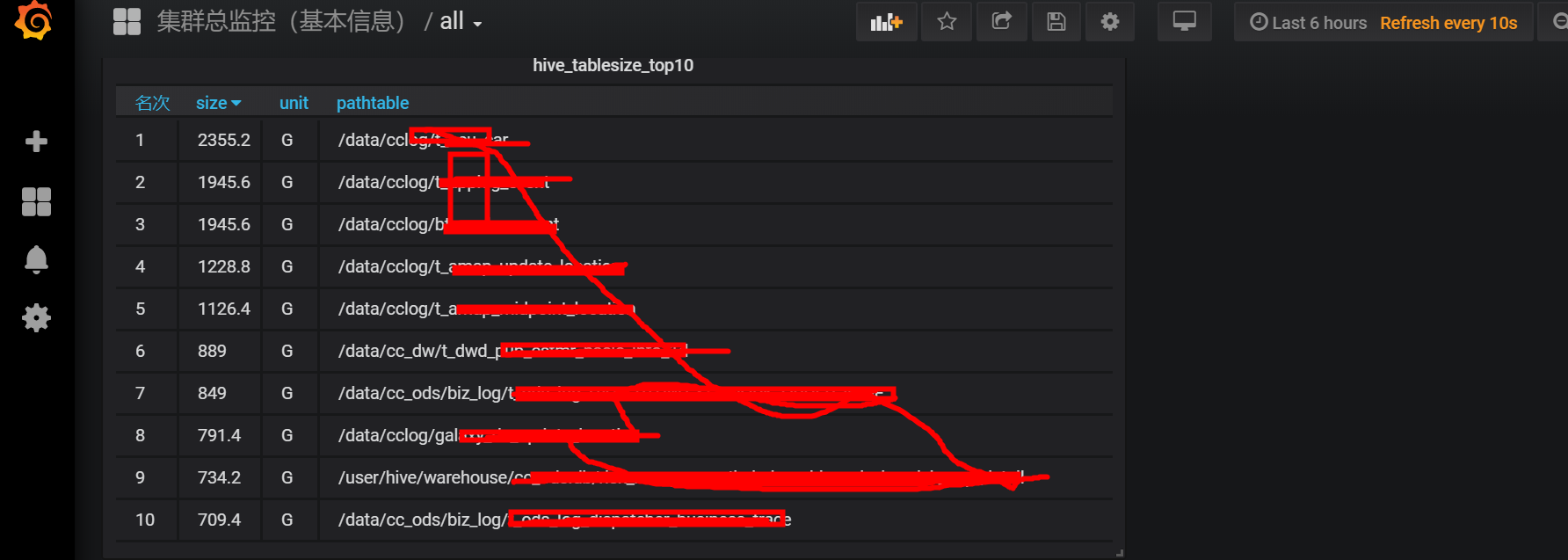
历时2天半,完成了从获取数据到清洗数据到最终的展示过程。
需求:hive中有很多表,他们的存储量很大,磁盘吃紧,为了以后能清楚的看到hive库中最大的10张表,所以需要做一个展示。
整理思路:
获取数据的途径:使用hadoop fs -du -s -h 表的绝对路径
为了后期开发简单,所以就把获取的数据尽量精简
给获取的数据进行排序,根据实际情况,前10的表一定是T或者是G级别的所以在获取数据的时候就把M和K级别的给过滤掉了
hadoop fs -du -h -s /data/cc_ads/*|grep T |sort -rn |head -5
hadoop fs -du -h -s /data/cc_ads/*|grep G |sort -rn |head -5
解释:grep T和G是只取单位为T或者G的,sort -rn 从大到小排序 head -5 取最大的前五条数据。之所以取前五是因为调研之后,每个库下大的表就那么几张,前五就基本上可以涵盖了,再多就没有意义了,当然 ,你在做的时候也可以根据实际情况判断。这里在开发完成以后发现一个更优秀的办法
就是不要单位直接显示字节,后期统一换算成G即可
获取的数据格式
2.3 T /data/cclog/t_neu_car
把获得数据的命令(即hadoop fs -du -h -s /data/cc_ads/*|grep G |sort -rn |head -5)统一放到一个test.sh文件中,最后>命令覆盖到一个hdfs.log文件中,
即sh test.sh>hdfs.log,这样hdfs.log里的数据就是我们需要的数据。
数据获取之后,清洗数据。我们的目的是把数据写到mysql里然后展示到grafana中。
通过spark,我们可以读取文件并转化成RDD,最后转换成DF,再把DF写入mysql,听起来so easy,实际上也so easy,但是真正实施的过程中,会有各种各样奇怪的情况需要考虑。
首先最经常出现的就是数组越位,如果你的思路没问题,那么就请去检查你的数据把,一定是有脏数据导致的问题。
我出现数组越位主要是在grep T和G中,有的表名字也带有这两个字母,这就导致有一个目录下的两张表没有数据,大小为零,同时单位也没有,如下
0 /data/cc_ods/mysql/zkdagh
0 /data/cc_ods/mysql/umtll
这就导致我在split的时候,出现了数组越界的问题
下面是代码
package Caocao_project import org.apache.spark.sql.types._ import org.apache.spark.sql.Row import org.apache.spark.sql.SparkSession //import scala.sys.process.processInternal.IOException object TableSizeApp { def main(args: Array[String]): Unit = { val num=args(0) val spark =SparkSession.builder()// .master("yarn")// // .master("local[*]")// .appName("TableSizeApp")// .getOrCreate() val sc = spark.sparkContext // val tablesize = sc.textFile("file:///C:\Users\小十七\Desktop\flume-ng-core-1.7.0\create_table_7.txt"). val tablesize = sc.textFile("hdfs://spark01:9000/tmp/admin/mysql/hdfs.log"). map(line => { val arr = line.split(" ") val arr1 = arr(0).toDouble
//这里的if主要就是处理了脏数据,本来应该用try catch的,但是用的不太熟练,所以改用了if if (arr(1) == "T") { (arr1 * 1024, "G", arr(3)) } else if (arr(1) == "G") { (arr1, arr(1), arr(3)) } else {(arr1, "G", arr(2)) } } ).map(p => Row(p._1,p._2,p._3)) // ..toString()map(p => Row(p(0), p(1))) //构造schema用到了两个类StructType和StructFile,其中StructFile类的三个参数分别是(字段名称,类型,数据是否可以用null填充) val schema = StructType(Array(StructField("size",DoubleType , true), StructField("unit", StringType, true),StructField("pathtable", StringType, true))) //step3.在行 RDD 上通过 createDataFrame 方法应用模式 val sizeDF = spark.createDataFrame(tablesize, schema) //sizeDF.registerTempTable("peopleTable") sizeDF.createGlobalTempView("Sizetable") val result = spark.sql(s"select * from global_temp.Sizetable order by size desc limit $num") // val result = spark.sql(s"select * from global_temp.Sizetable order by size desc limit 10") // result.show(40) result.write.mode("overwrite").format("jdbc").option("url","jdbc:mysql://172.16.150.89:15361/airflow").option("driver","com.mysql.jdbc.Driver").option("dbtable","Sizetable").option("user","admin").option("password","9a9F839N4q2maLVC").save() spark.stop() } }
grafana的展示