本文仅供学习使用
这是清华大学2019年在EMNLP发表的工作,文本生成方向。
ARAML: A Stable Adversarial Training Framework for Text Generation (EMNLP 2019)
最大似然估计是语言生成中的最常用的方法,但该方法面临包括偏差(Exposure Bias)问题。不少工作提出可以使用生成式对抗网络(Generative Adversarial Network, GAN)对文本生成进行优化,但在应用至离散的文本生成任务时会遇到梯度无法回传的问题。目前有两类主要方法来解决该问题:1) 连续性松弛:将离散的生成结果近似为连续空间的向量;2) 强化学习:将文本生成问题转化为强化学习中的序列决策问题,利用策略梯度(Policy Gradient)进行优化。
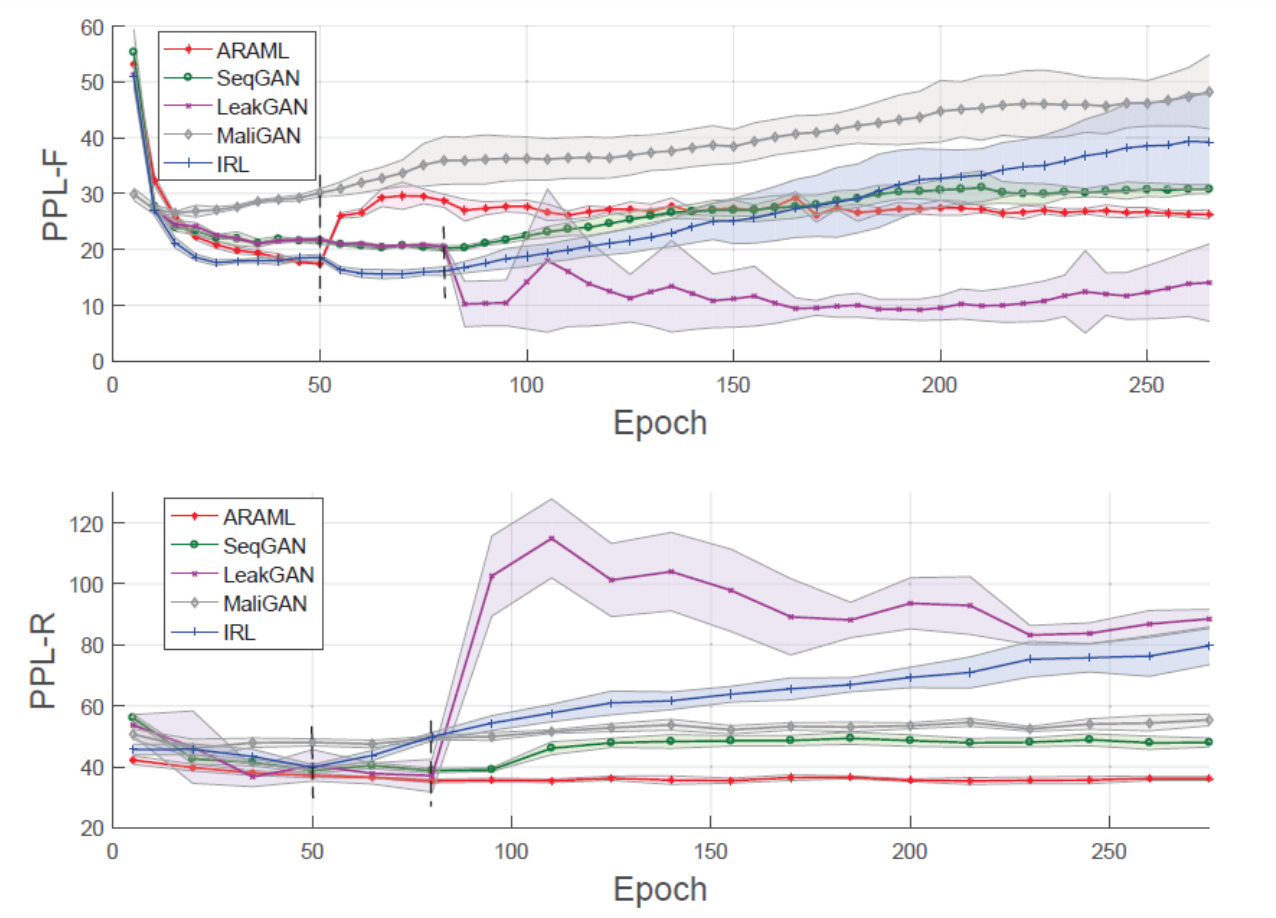
本工作主要关注强化学习优化方法中出现的训练不稳定问题,该问题主要来源于GAN生成器的采样过程。根据已有工作及实验,虽然GAN在文本生成领域通常会先用最大似然估计(Maximum Likelihood Estimation, MLE)对生成器进行预训练,但从生成器中采样得到的样本质量依然偏低,这导致判别器在策略梯度的优化过程中不能提供稳定的奖励信号,从而使得训练过程不稳定。
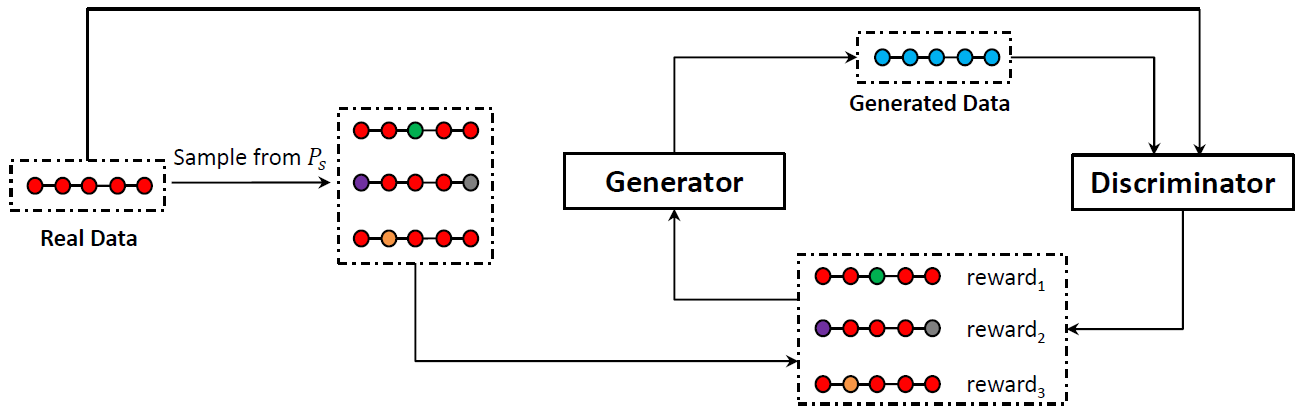
针对GAN训练不稳定问题,本工作提出了结合对抗奖励的最大似然优化框架(Adversarial Reward Augmented Maximum Likelihood, ARAML),该框架在训练生成器时会从与真实数据分布很接近的静态分布中采样,而不会像策略梯度方法那样从生成器的分布中采样,避免从生成器中获得质量差且明显偏离真实数据分布的训练样本。生成器的优化目标为带权的负对数似然函数,其中权重可根据判别器给出的分数计算,具体推导可参考论文https://www.aclweb.org/anthology/D19-1436。

实验结果表明,ARAML在COCO和EMNLP 2017 WMT数据集上均取得了较好的生成质量和多样性,且在多次重复实验中表现出了比其他baseline更好的稳定性。我们还对模型生成结果的指标随训练过程的变化趋势进行了可视化,结果表明ARAML显著提升了GAN在文本生成任务中的训练稳定性。本工作还在对话数据集上进行了测试和人工评价,并对模型中的重要设计做了消融实验,具体可参考论文。