https://github.com/google-research/pegasus
ICML 2020 接收的论文,https://arxiv.org/abs/1912.08777
Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence models, or PEGASUS, uses self-supervised objective Gap Sentences Generation (GSG) to train a transformer encoder-decoder model.
PEGASUS:基于句子间隙的抽取式摘要预训练模型
PEGASUS专用于机器摘要生成。使用谷歌预训练的模型,在1000个样本进行测试,结果不差于人类评估结果。
谷歌发现,选择“重要”句子去遮挡效果最好,这会使自监督样本的输出与摘要更加相似。根据ROUGE标准对输出结果进行评判,通过查找与文档其余部分最相似的句子来自动识别这些句子。
与谷歌之前提出的T5对比,参数数量仅为T5的5%。
使用3种模型在12个数据集做实验,训练动态间隙句生成模型
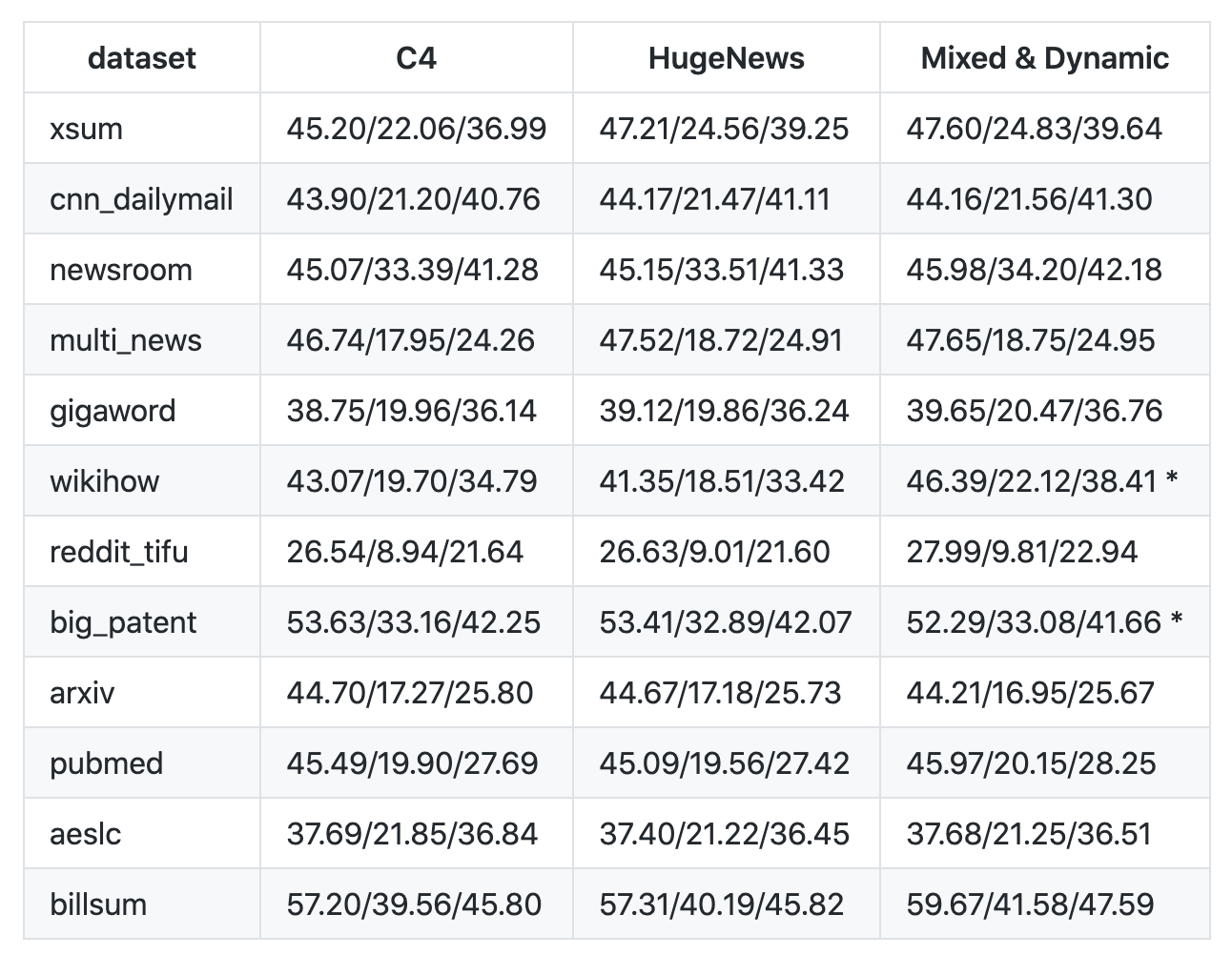
12个不同的数据集,包括新闻、科学论文、专利文件、短篇小说、电子邮件、法律文件和使用说明,表明该模型框架适用于各种主题。
准备环境
代码是需要机器和环境才可以运行的。
源代码给出的是gcloud命令,我没有使用它,而是使用阿里云机器。
具体配置为:
ubuntu 16.04 64位
硬盘500G
1块V100
GPU驱动相关版本号:
CUDA:10.2.89
Driver:440.64.00
CUDNN:7.6.5
试了CUDA10.1.168,有报错。所以,CUDA版本很重要,别选错。具体谷歌自己使用的是哪个版本,我目前没找到相关资料。
cat /usr/local/cuda/version.txt
CUDA Version 10.1.168
tensorflow.python.framework.errors_impl.NotFoundError: libtensorflow_framework.so.2: cannot open shared object file: No such file or directory
正确的提示是:
2020-06-22 11:08:56.423661: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7
gcloud也试了一下,提示权限不对。国内FQ有些费劲呀。
安装pegasus
我使用的是Ancona3
cd ~/git
git clone https://github.com/google-research/pegasus
cd pegasus
source ~/anaconda3/bin/activate
# conda create --name env_pegasus python=3.7 创建时需要
conda activate env_pegasus
pip3 install -r requirements.txt
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
python3 setup.py install & build
下载数据
共12个数据集,使用gsutil工具下载。
gsutil工具安装参考https://cloud.google.com/storage/docs/gsutil_install
需要准备35G磁盘空间。我电脑磁盘空间不够,用了外挂移动硬盘。
gsutil工具安装完毕之后,就可以下载数据了。
mkdir ckpt
gsutil cp -r gs://pegasus_ckpt/ ckpt/
下载完毕之后,将预训练的模型文件上传到服务器对应的目录。 下载速度依网速而定,我用了大概两天时间吧。
最终的数据为:

训练完毕之后,pegasus/ckpt/pegasus_ckpt/aeslc目录:

数据集
下面的训练和评估,均使用aeslc数据集。
AESLC (Zhang & Tetreault, 2019) consists of 18k email bodies and their subjects from the Enron corpus (Klimt & Yang, 2004), a collection of email messages of employees in the Enron Corporation.
训练
python3 pegasus/bin/train.py --params=aeslc_transformer
--param_overrides=vocab_filename=ckpt/pegasus_ckpt/c4.unigram.newline.10pct.96000.model
--train_init_checkpoint=ckpt/pegasus_ckpt/model.ckpt-1500000
--model_dir=ckpt/pegasus_ckpt/aeslc
以上代码我在运行的时候有报错,依赖模块未找到。我把train.py 文件拷贝到仓库根目录,然后再运行,结果显示可以。
评估
训练完毕之后,就可以评估模型了。
python3 pegasus/bin/evaluate.py --params=aeslc_transformer
--param_overrides=vocab_filename=ckpt/pegasus_ckpt/c4.unigram.newline.10pct.96000.model,batch_size=1,beam_size=5,beam_alpha=0.6
--model_dir=ckpt/pegasus_ckpt/aeslc
同上,evaluate.py文件也拷贝到仓库的根目录。
评估结果:
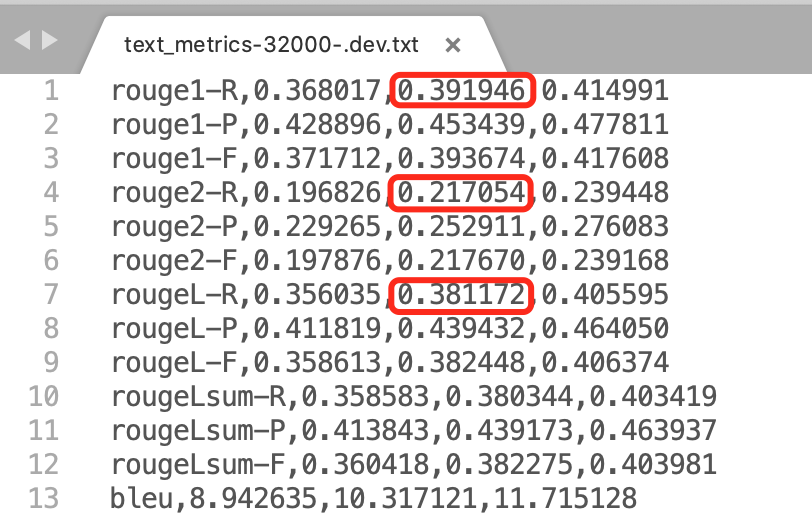
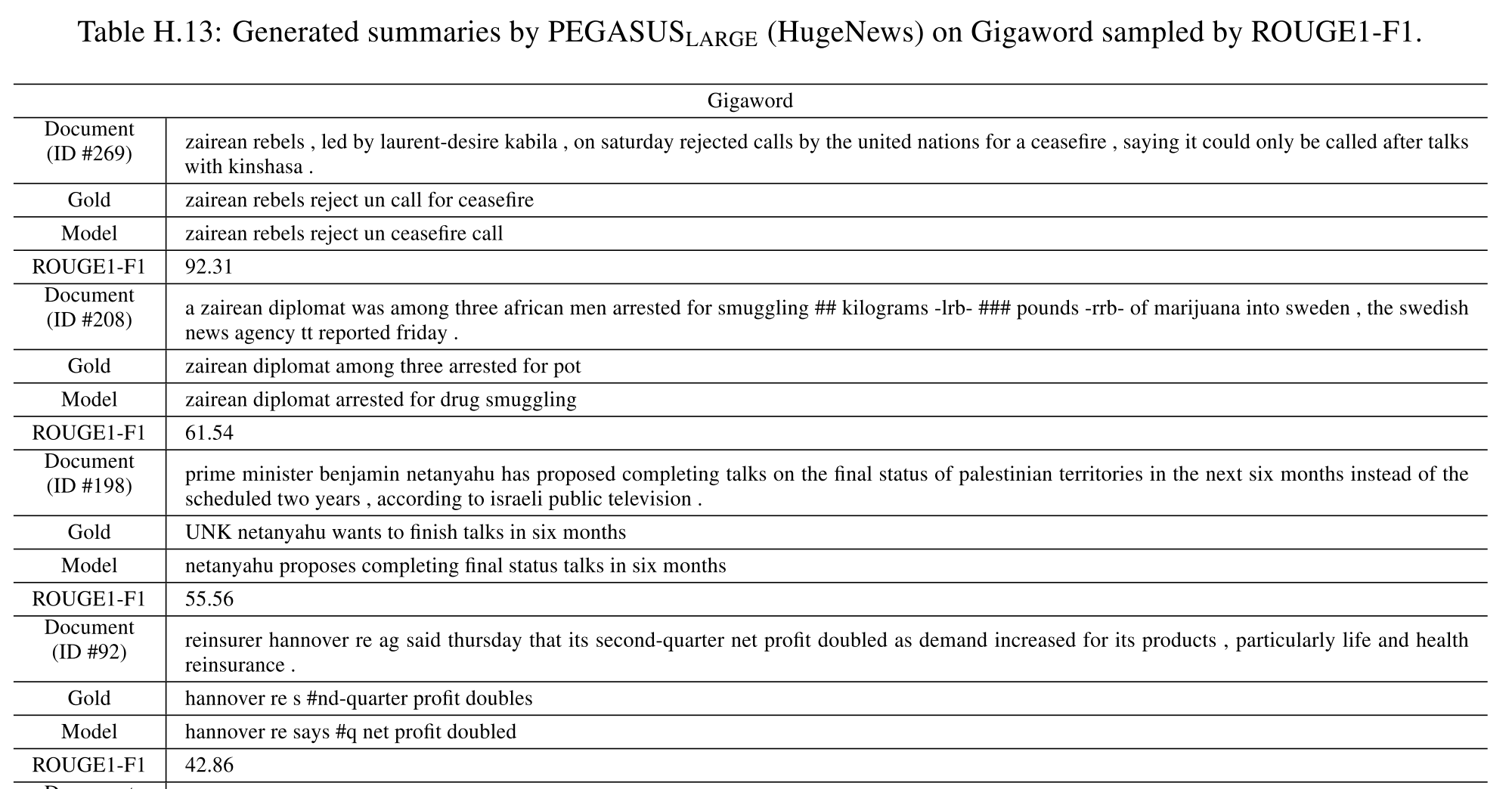
可见,和谷歌公布的结果基本一致。
37.69/21.85/36.84
使用自己的数据
支持2种格式的数据集:TensorFlow Datasets (TFDS) 、 TFRecords.
评测指标
ROUGE is the main metric for summarization quality.
BLEU is an alternative quality metric for language generation.
Extractive Fragments Coverage & Density are metrics that measures the abstractiveness of the summary.
Repetition Rates measures generation repetition failure modes.
Length statistics measures the length distribution of decodes comparing to gold summary.
摘要结果示例:

数据集
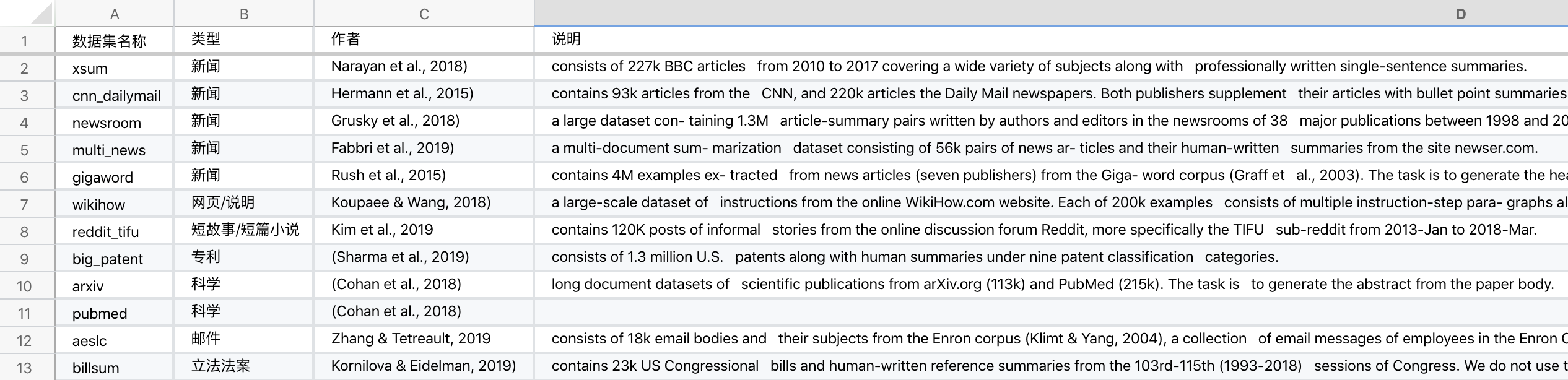
7个领域,共12个数据集。
7个领域分别为:新闻、科学、短篇小说、说明、电子邮件、专利、立法法案
1. news (Hermann et al., 2015; Narayan et al., 2018; Grusky et al., 2018; Rush et al., 2015; Fabbri et al., 2019), 【新闻,5个数据集】
2. science (Cohan et al., 2018), 【科学,2个数据集】
3. short stories (Kim et al., 2019), 【短故事/短篇小说,1个数据集】
4. instructions (Koupaee & Wang, 2018), 【网页/说明,1个数据集】
5. emails (Zhang & Tetreault, 2019), 【邮件,1个数据集】
6. patents (Sharma et al., 2019), 【专利,1个数据集】
7. legislative bills (Kornilova & Eidelman, 2019). 【立法法案,1个数据集】
【科学】数据集
arXiv, PubMed (Cohan et al., 2018) are two long document datasets of scientific publications from arXiv.org (113k) and PubMed (215k). The task is to generate the abstract from the paper body.




【网页/说明】数据集
WikiHow (Koupaee &Wang, 2018) is a large-scale dataset of instructions from the online WikiHow.com website. Each of 200k examples consists of multiple instruction-step para- graphs along with a summarizing sentence. The task is to generate the concatenated summary-sentences from the paragraphs.
Koupaee, M. and Wang, W. Y. Wikihow: A large scale text summarization dataset. arXiv preprint arXiv:1810.09305, 2018.


【新闻】数据集



NEWSROOM摘要是一句话