AlexNet模型
《ImageNet Classification with Deep Convolutional Neural Networks》阅读笔记
一直在使用AlexNet,本来早应该读这篇经典论文了。可能是这篇论文涉及到的理论有点多,解释不是很通俗,有了一段时间的实际经验后读完这篇论文深有感悟。
下面按论文的标题分别记录:
The Dataset
ILSVRC:1000类,每类约1000张图片,大约有120w训练图片,5w张验证图片,15w张测试图片。
AlexNet输入为固定尺寸:256*256,从原始图片进行resize and crop得到。唯一一个预处理是所有图像在进入网络时减去整体均值。
ReLU Nonlinearity
ReLU是一种不饱和非线性函数,相对传统的饱和非线性函数具 有更快的收敛速度,可以加速拟合训练集。Jarrettet用ReLU来阻止过拟合。
Training on Multiple GPUs
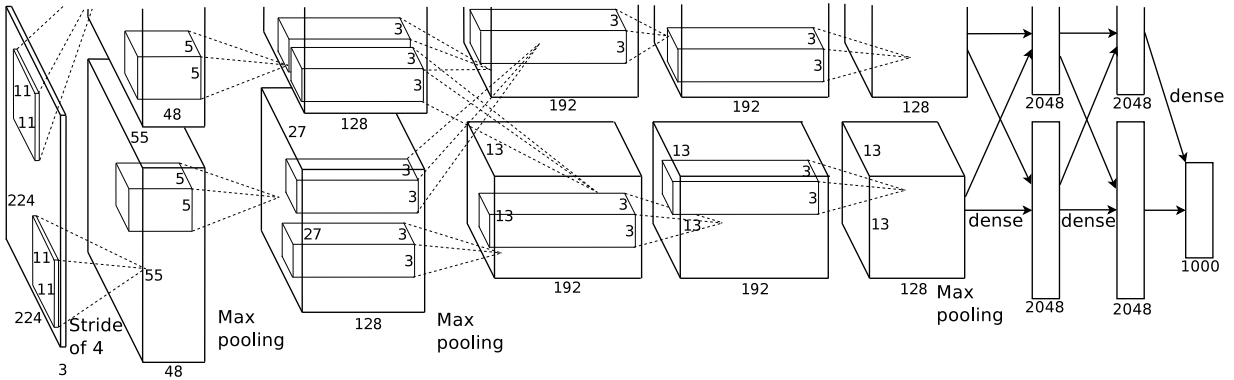
使用多个两个GPU是为了解决单个GPU内存限制了网络大小,将 原网络拆成两半,比如说第一层卷积应该输出55×55×96,现拆成两个55×55×48。这里GPU只 在某些层进行互相通信。
Local Response Normalization
论文中提出的LRN属于CROSS_CHANNEL的,作用是模拟生物神经 上的侧抑制( lateral inhibition,或者叫邻近抑制),使相邻神经元的激活值之间产生竞争。因为每个神经元的激活值需要除以相邻神经元的激活值的平方和,因此如果相邻神经元含有较大激活值的话,本身LRN后的激活值 就变小了。
Reducing Overfitting
论文介绍了两种防止过拟合的方法:
1.Data Augmentation
Data Augmentation是通过少量的计算从原始图片变换得到新的训练数据。第一种是随机裁剪,原图256×256,裁剪大小为224×224,由于随机,所以每个epoch中对同一张图片进行了不同的裁剪,理论上相当于扩大数据集32×32×2=2048倍!32是256-224;2是由于水平翻转。
在预测(deploy)阶段,不是随机裁剪,而是固定为图片四个边角,外加中心位置。翻转后进行同样操作,共产生10个patch。
2.Dropout
Dropout是借鉴了多个模型结合的想法,对于一个分类问题,如果有多个训练完备的不同的模型,同时对一个输入做出预测,然后少数服从多数,显然会减小错误率。实际的做法是:每个隐层神经元的输出有0.5的概率置为0,置为0的神经元就不 会参加前向传播和反向更新。这样做的好处是有效防止过拟合,但是缺点是网络收敛需要的迭代次数增加一倍。
Details of learning
batch size=128
momentum=0.9
weight decay=0.0005
initial learining rate=0.01 reduce three times(factor :10)
iter epoch=90- 1
- 2
- 3
- 4
- 5
The update rule for weight w was
<∂L∂W|wi>Di<∂L∂W|wi>Di为参数对应的梯度,ϵϵ为学习速率。