0.spark简介
Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。是一个用来实现快速而同用的集群计算的平台。Spark将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。其底层采用Scala这种函数式语言书写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口
执行器作用:
负责运行组成Spark应用的任务,并将结果返回给驱动器进程;
通过自身的块管理器(blockManager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在执行器进程内的,因此任务可以在运行时充分利用缓存数据加快运算。
驱动器的职责:
所有的Spark程序都遵循同样的结构:程序从输入数据创建一系列RDD,再使用转化操作派生成新的RDD,最后使用行动操作收集或存储结果RDD,Spark程序其实是隐式地创建出了一个由操作组成的逻辑上的有向无环图DAG。当驱动器程序执行时,它会把这个逻辑图转为物理执行计划。这样 Spark就把逻辑计划转为一系列步骤(stage),而每个步骤又由多个任务组成。这些任务会被打包送到集群中。
1、RDD是什么
RDD:Spark的核心概念是RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。
分区是RDD内部并行计算的一个计算单元,RDD的数据集在逻辑上被划分为多个分片,每一个分片称为分区,分区的格式决定了并行计算的粒度,而每个分区的数值计算都是在一个任务中进行的,因此任务的个数,也是由RDD(准确来说是作业最后一个RDD)的分区数决定。
RDD分区的一个分区原则:尽可能是得分区的个数等于集群核心数目
Spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在集群的不同节点上。创建RDD的方法有两种:一种是读取一个外部数据集;一种是在群东程序里分发驱动器程序中的对象集合,不如刚才的示例,读取文本文件作为一个字符串的RDD的示例。
创建出来后,RDD支持两种类型的操作:转化操作和行动操作
转化操作会由一个RDD生成一个新的RDD。
行动操作会对RDD计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(比如HDFS)中。
RDD计算方式

下面对RDD的五个特性进行解释:
1、有一个分片列表。就是能被切分,和hadoop一样的,能够切分的数据才能并行计算。
2、有一个函数计算每一个分片,这里指的是下面会提到的compute函数。
3、对其他的RDD的依赖列表,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。
4、可选:key-value型的RDD是根据哈希来分区的,类似于mapreduce当中的Paritioner接口,控制key分到哪个reduce。
5、可选:每一个分片的优先计算位置(preferred locations),比如HDFS的block的所在位置应该是优先计算的位置。(存储的是一个表,可以将处理的分区“本地化”)
为什么会产生RDD?
(1)传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作。RDD正是解决这一缺点的抽象方法
(2)RDD的具体描述RDD(弹性分布式数据集)是Spark提供的最重要的抽象的概念,它是一种有容错机制的特殊集合,可以分布在集群的节点上,以函数式编程操作集合的方式,进行各种并行操作。可以将RDD理解为一个具有容错机制的特殊集合,它提供了一种只读、只能由已存在的RDD变换而来的共享内存,然后将所有数据都加载到内存中,方便进行多次重用。
a.它是分布式的,可以分布在多台机器上,进行计算。
b.它是弹性的,计算过程中内存不够时它会和磁盘进行数据交换(缓存管理)。
c.这些限制可以极大的降低自动容错开销
d.实质是一种更为通用的迭代并行计算框架,用户可以显示地控制计算的中间结果,然后将其自由运用于之后的计算。
(3)RDD的容错机制实现分布式数据集容错方法有两种:数据检查点和记录更新,RDD采用记录更新的方式:记录所有更新点的成本很高。所以,RDD只支持粗颗粒变换,即只记录单个块(分区)上执行的单个操作,然后创建某个RDD的变换序列(血统 lineage)存储下来;变换序列指,每个RDD都包含了它是如何由其他RDD变换过来的以及如何重建某一块数据的信息。因此RDD的容错机制又称“血统”容错。 要实现这种“血统”容错机制,最大的难题就是如何表达父RDD和子RDD之间的依赖关系。实际上依赖关系可以分两种,窄依赖和宽依赖。窄依赖:子RDD中的每个数据块只依赖于父RDD中对应的有限个固定的数据块;宽依赖:子RDD中的一个数据块可以依赖于父RDD中的所有数据块。例如:map变换,子RDD中的数据块只依赖于父RDD中对应的一个数据块;groupByKey变换,子RDD中的数据块会依赖于多块父RDD中的数据块,因为一个key可能分布于父RDD的任何一个数据块中, 将依赖关系分类的两个特性:第一,窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据计算得到子RDD对应的某块数据;宽依赖则要等到父RDD所有数据都计算完成之后,并且父RDD的计算结果进行hash并传到对应节点上之后才能计算子RDD。第二,数据丢失时,对于窄依赖只需要重新计算丢失的那一块数据来恢复;对于宽依赖则要将祖先RDD中的所有数据块全部重新计算来恢复。所以在“血统”链特别是有宽依赖的时候,需要在适当的时机设置数据检查点。也是这两个特性要求对于不同依赖关系要采取不同的任务调度机制和容错恢复机制。
(4)RDD内部的设计每个RDD都需要包含以下四个部分:
a.源数据分割后的数据块,源代码中的splits变量
b.关于“血统”的信息,源码中的dependencies变量
c.一个计算函数(该RDD如何通过父RDD计算得到),源码中的iterator(split)和compute函数d.一些关于如何分块和数据存放位置的元信息,如源码中的partitioner和preferredLocations例如:a.一个从分布式文件系统中的文件得到的RDD具有的数据块通过切分各个文件得到的,它是没有父RDD的,它的计算函数知识读取文件的每一行并作为一个元素返回给RDD;b.对与一个通过map函数得到的RDD,它会具有和父RDD相同的数据块,它的计算函数式对每个父RDD中的元素所执行的一个函数
2、RDD在Spark中的地位及作用
(1)为什么会有Spark?因为传统的并行计算模型无法有效的解决迭代计算(iterative)和交互式计算(interactive);而Spark的使命便是解决这两个问题,这也是他存在的价值和理由。
(2)Spark如何解决迭代计算?其主要实现思想就是RDD,把所有计算的数据保存在分布式的内存中。迭代计算通常情况下都是对同一个数据集做反复的迭代计算,数据在内存中将大大提升IO操作。这也是Spark涉及的核心:内存计算。
(3)Spark如何实现交互式计算?因为Spark是用scala语言实现的,Spark和scala能够紧密的集成,所以Spark可以完美的运用scala的解释器,使得其中的scala可以向操作本地集合对象一样轻松操作分布式数据集。
(4)Spark和RDD的关系?可以理解为:RDD是一种具有容错性基于内存的集群计算抽象方法,Spark则是这个抽象方法的实现。
3、RDD底层实现原理
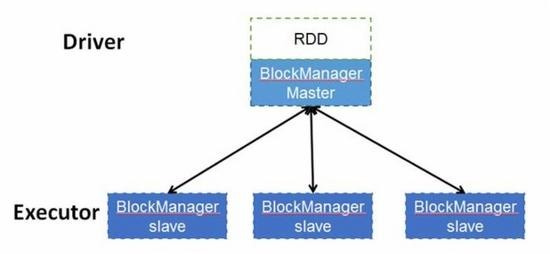
RDD是一个分布式数据集,顾名思义,其数据应该分部存储于多台机器上。事实上,每个RDD的数据都以Block的形式存储于多台机器上,下图是Spark的RDD存储架构图,其中每个Executor会启动一个BlockManagerSlave,并管理一部分Block;而Block的元数据由Driver节点的BlockManagerMaster保存。BlockManagerSlave生成Block后向BlockManagerMaster注册该Block,BlockManagerMaster管理RDD与Block的关系,当RDD不再需要存储的时候,将向BlockManagerSlave发送指令删除相应的Block。
4、RDD cache的原理
RDD的转换过程中,并不是每个RDD都会存储,如果某个RDD会被重复使用,或者计算其代价很高,那么可以通过显示调用RDD提供的cache()方法,把该RDD存储下来。那RDD的cache是如何实现的呢?
RDD中提供的cache()方法只是简单的把该RDD放到cache列表中。当RDD的iterator被调用时,通过CacheManager把RDD计算出来,并存储到BlockManager中,下次获取该RDD的数据时便可直接通过CacheManager从BlockManager读出。
What is Data Locality - RDD的位置可见性(location preference)
这个问题就不重复造轮子了,直接引用Quora上的一个问答了:
RDD is a dataset which is distributed, that is, it is divided into “partitions”. Each of these partitions can be present in the memory or disk of different machines. If you want Spark to process the RDD, then Spark needs to launch one task per partition of the RDD. It’s best that each task be sent to the machine have the partition that task is supposed to process. In that case, the task will be able to read the data of the partition from the local machine. Otherwise, the task would have to pull the partition data over the network from a different machine, which is less efficient. This scheduling of tasks (that is, allocation of tasks to machines) such that the tasks can read data “locally” is known as “locality aware scheduling”.
5、如何操作RDD?
RDD的所有转换操作都是lazy模式,即Spark不会立刻计算结果,而只是简单的记住所有对数据集的转换操作。这些转换只有遇到action操作的时候才会开始计算
(1)如何获取RDDa.从共享的文件系统获取,(如:HDFS)b.通过已存在的RDD转换c.将已存在scala集合(只要是Seq对象)并行化 ,通过调用SparkContext的parallelize方法实现d.改变现有RDD的之久性;RDD是懒散,短暂的。(RDD的固化:cache缓存至内存; save保存到分布式文件系统)
(2)操作RDD的两个动作a.Actions:对数据集计算后返回一个数值value给驱动程序;例如:Reduce将数据集的所有元素用某个函数聚合后,将最终结果返回给程序。b.Transformation:根据数据集创建一个新的数据集,计算后返回一个新RDD;例如:Map将数据的每个元素经过某个函数计算后,返回一个新的分布式数据集。
在spark新版中,也许会有更多的action和transformation,可以参照spark的主页
6. RDD工作原理
RDD(Resilient DistributedDatasets)[1] ,弹性分布式数据集,是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD ,不同的分片、数据之间的依赖、key-value类型的map数据都可以看做RDD。
主要分为三部分:创建RDD对象,DAG调度器创建执行计划,Task调度器分配任务并调度Worker开始运行。
SparkContext(RDD相关操作)→通过(提交作业)→(遍历RDD拆分stage→生成作业)DAGScheduler→通过(提交任务集)→任务调度管理(TaskScheduler)→通过(按照资源获取任务)→任务调度管理(TaskSetManager)
Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的。
Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中
转换(Transformations)(如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
操作(Actions)(如:count, collect, save等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
它们本质区别是:Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的。Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中。关于这两个动作,在Spark开发指南中会有就进一步的详细介绍,它们是基于Spark开发的核心。
7.RDD的宽窄依赖
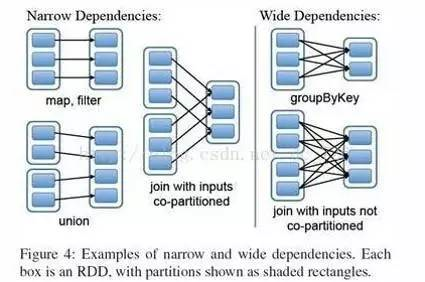
窄依赖 (narrowdependencies) 和宽依赖 (widedependencies) 。窄依赖是指 父 RDD 的每个分区都只被子 RDD 的一个分区所使用 。相应的,那么宽依赖就是指父 RDD 的分区被多个子 RDD 的分区所依赖。例如, map 就是一种窄依赖,而 join 则会导致宽依赖
这种划分有两个用处。首先,窄依赖支持在一个结点上管道化执行。例如基于一对一的关系,可以在 filter 之后执行 map 。其次,窄依赖支持更高效的故障还原。因为对于窄依赖,只有丢失的父 RDD 的分区需要重新计算。而对于宽依赖,一个结点的故障可能导致来自所有父 RDD 的分区丢失,因此就需要完全重新执行。因此对于宽依赖,Spark 会在持有各个父分区的结点上,将中间数据持久化来简化故障还原,就像 MapReduce 会持久化 map 的输出一样。
Spark数据分区
Spark的特性是对数据集在节点间的分区进行控制。在分布式系统中,通讯的代价是巨大的,控制数据分布以获得最少的网络传输可以极大地提升整体性能。Spark程序可以通过控制RDD分区方式来减少通讯的开销。
Spark中所有的键值对RDD都可以进行分区。确保同一组的键出现在同一个节点上。比如,使用哈希分区将一个RDD分成了100个分区,此时键的哈希值对100取模的结果相同的记录会被放在一个节点上。
(可使用partitionBy(newHashPartitioner(100)).persist()来构造100个分区)
Spark中的许多操作都引入了将数据根据键跨界点进行混洗的过程。(比如:join(),leftOuterJoin(),groupByKey(),reducebyKey()等)对于像reduceByKey()这样只作用于单个RDD的操作,运行在未分区的RDD上的时候会导致每个键的所有对应值都在每台机器上进行本地计算。
SparkSQL的shuffle过程

Spark SQL的核心是把已有的RDD,带上Schema信息,然后注册成类似sql里的”Table”,对其进行sql查询。这里面主要分两部分,一是生成SchemaRD,二是执行查询。
如果是spark-hive项目,那么读取metadata信息作为Schema、读取hdfs上数据的过程交给Hive完成,然后根据这俩部分生成SchemaRDD,在HiveContext下进行hql()查询。