前言
致力于滤波器的剪枝,论文的方法不改变原始网络的结构。论文的方法是基于下一层的统计信息来进行剪枝,这是区别已有方法的。
VGG-16上可以减少3.31FLOPs和16.63倍的压缩,top-5的准确率只下降0.52%。在ResNet-50上可以降低超过一半的参数量和FLOPs,top-5的准确率只降低1%。
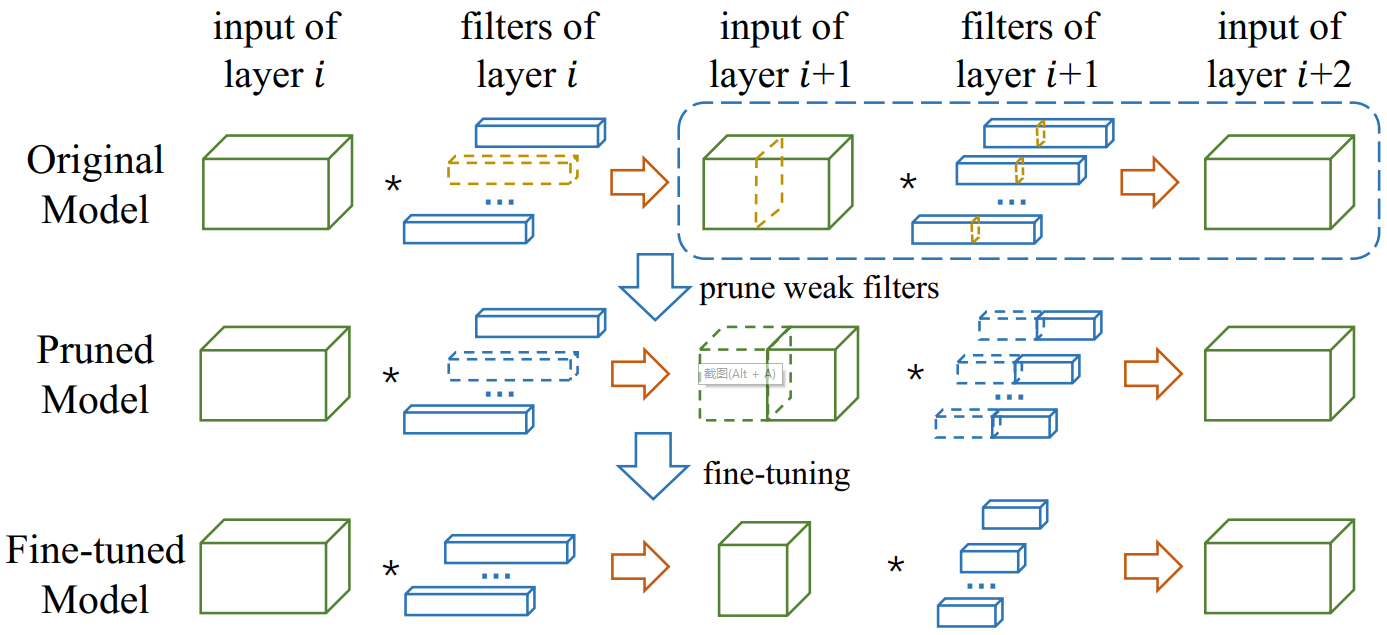
如上图所示,在虚线框中找到那些弱通道(weak channels)和他们对应的滤波器(黄色高亮部分),这些通道和对应的滤波器对整体性能贡献较小,因此可以丢弃,这样就得到一个剪枝后的模型,然后通过微调(fine-tune)恢复模型的准确率。
ThiNet框架
(1)滤滤波器选择
不同于已有的方法(使用layer(i)层的统计数据对layer(i)滤波器进行剪枝),论文对layer(i+1)的统计信息来对layer(i)层进行剪枝。思路如下:如果可以使用layer(i+1)的子集通道(subset channels)的输入来逼近layer(i+1)的输出,那么其它的通道就可以从layer(i+1)的输入移除,而layer(i+1)的输入是由layer(i)的滤波器产生的。
(2)剪枝
在layer(i+1)的弱通道和其对应的layer(i)层的滤波器将被去除,模型将变得更小。剪枝后的网络的结构不变,但拥有较少的滤波器和通道数。
(3)微调
通过大量数据的训练来恢复网络性能
数据驱动的通道选择
使用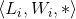 来表示layer(i)的卷积过程,其中
来表示layer(i)的卷积过程,其中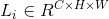 表示输入的张量(tensor),
表示输入的张量(tensor), 是一组KxK的核大小的滤波器,使用D个channels生成新的张量。
是一组KxK的核大小的滤波器,使用D个channels生成新的张量。
我们的目标是移除 中不重要的滤波器。可以看出,如果
中不重要的滤波器。可以看出,如果 中的一个滤波器被移除了,在
中的一个滤波器被移除了,在 和
和 中相应的通道也会被移除。这样的操作下,layer(i+1)的滤波器的数目和他输出张量的大小保持不变,因此
中相应的通道也会被移除。这样的操作下,layer(i+1)的滤波器的数目和他输出张量的大小保持不变,因此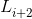 也保持不变。
也保持不变。
收集训练样本
通道选择——贪心算法
最小化重构误差