在Java5.0中加入的ConcurrentHashMap,属于并发容器的一种,旨在提供并发环境下高效的安全性和性能。相比于HashTable的全局锁,ConcurrentHashMap使用分段锁减少竞争。经过几个大版本的更新,实现细节发生了很大变化,下面主要说说JDK1.7和JDK1.8中的实现。
JDK1.7细节
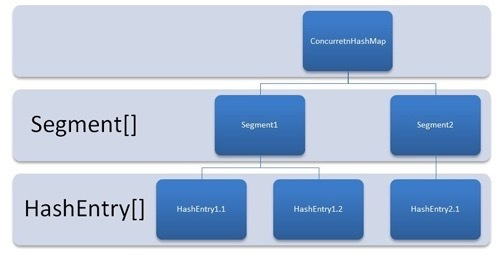
分段锁Segment,内部保存了HashEntry[]。同时也继承了ReentrantLock。访问每个Segment需要先获取锁,理论上支持Segment.size的并发量
HashEntry,存放真正的数据,比较特殊的是其value和下一个节点指针使用volatile修饰,保证了可见性。
1. put方法
首先定位到某个Segment,然后尝试加锁,加锁失败转而自旋获取锁,自旋一定次数后线程阻塞。
获取锁后,通过key的hashCode定位到HashEntry,为空则新建一个节点,并判断是否需要扩容。不为空则遍历HashEntry链表找到相等的key覆盖旧的value,若没有则插入到尾部,最后释放锁。
2. get方法
先定位到Segment然后找到hashEntry,整个过程不需要加锁。并且每次获取的都是最新值(volatile属性)
3. size方法
先通过两次不加锁计算分段总大小,如果两次计算过程中的modCount相等,则返回结果,否则锁住所有分段计算总大小
JDK1.8细节
优化了JDK1.7版本的遍历链表效率问题
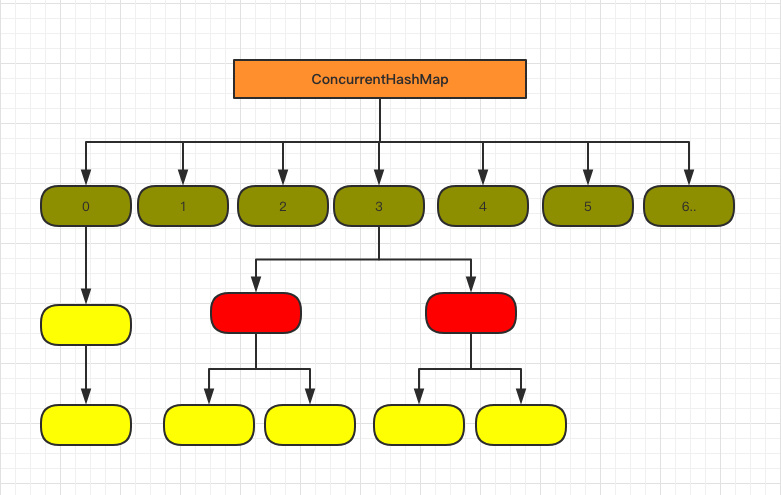
抛弃了Segment设计,直接使用Node[]存储元素,Node跟HashEntry两种结构并无差别。采用CAS和synchronized保证并发,抛弃了modCount概念。
先介绍下内部重要的属性
sizeCtl:这个值阐述了集合的状态,-1表示正在初始化,小于-1代表正在扩容,-N代表有N-1个线程正在协助扩容(见参考4)。非负代表了初始化容量或者下次扩容的阈值。
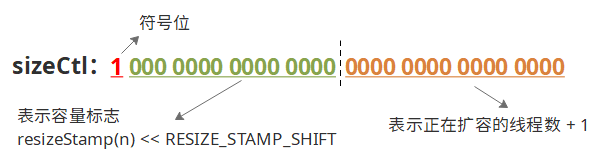
(图引用:https://www.cnblogs.com/sanzao/p/10792546.html)
1. put方法
1. 根据key得到hashCode
2. 如果第一次插入需要初始化Node[]
3. 根据hashCode找出对应Node(桶),若为空,尝试CAS写入数据,失败则进入下一个循环在此尝试。否则继续
4. 如果当前的哈希值=MOVED(-1),当前线程协助数据转移。否则继续
5. 到了这说明当前位子不为空,也没有在扩容,则锁住头节点。如果头节点hash值大于等于0,说明是链表。遍历链表找到相等的key覆盖value,否则将新值放在最末尾,同时记下链表总长
6. 5的分支,如果头节点哈希值小于零,说明是红黑树(红黑树的哈希值为-2),调用红黑树的方法插入节点
7. 如果总链表长大于等于阈值(8),尝试进行红黑树转化,需要判断数组长度大于64,则进行红黑树转化,否则只扩容数组。
8.更新size的统计信息,addCount方法
2. 初始化数组(initTable方法)
应对并发场景,首先通过sizeCtl标识检查是否小于0(正在初始化或者扩容),有则让出CPU时间。
否则CAS将sizeCtl设置为-1,表示正在进行初始化。初始化一个数组,默认大小为16,并设置sizeCtl大小为下次扩容的阈值(16*0.75)
3. 尝试红黑树转化(treeifyBin方法)
如果数组长度小于64,扩容数组。否则锁住头节点,遍历链表生成红黑树,并设置到原先位置。
4. 数据迁移(transfer方法)
扩容操作的一部分。两个入参,旧数组和新数组,将旧数组数据转移到新数组。
这个方法支持多线程一起执行,思想就是将整个数组迁移拆成一批批子任务,每批处理其中一部分数组。每个线程领取一个子任务,有一个全局属性transferIndex标记下一个子任务开始的位置
1. 首先会计算出一批任务的大小,也叫步长,最小值16。注意这里是倒序,也就是从数组最后往前领取。
2. 第一个执行的线程,新数组是null,需要先初始化,容量大小翻倍,新数组为nextTable
3. 初始化一个稻草人ForwardingNode,它的哈希值是MOVED,里面藏了指向新数组的指针。每迁移完一个桶,会用这个稻草人占位,其他节点想要在这个位子插入时会先协助迁移,见helpTransfer
4. 反向遍历扩容 for (int i = 0, bound = 0;;) 见附录1
4.1 判断需不需要向前推进进度,每次处理完一个桶会设置成true。需要则CAS推进transferIndex的进度,相当于申请了下一个批次。
4.2 判断是不是已经全部迁移完成了,若是
4.2.1 判断finshing是否为true,是则交换新旧数组,并将sizeCtl设置为下次扩容的阈值。注意这里只有最后一个退出的线程会执行哦
4.2.1 CAS将sizeCtl减1,代表扩容线程-1。然后线程会检查自己是不是最后一个线程,不是退出循环。是的话将finshing设置为true,还要进行一次循环
4.3 若当前节点为空,将稻草人插上,继续下个循环
4.4 执行迁移操作,锁住头节点
4.4.1 处理链表
将链表从lastRun处拆成两条。lastRun之前的链表,称为低位链表,在新表的索引和之前一样。lastRun之后的称为高位链表,在新表的索引有变化。
将低位链表拷贝一份插入到新表,注意是倒序的。将高位链表按照原来的顺序直接移到新表。
4.4.2 处理红黑树,注意是中序遍历
5. 扩容(tryPresize方法)
0. 外层有一个判断,必须sizeCtl>=0,也就是处在能扩容的状态,当第一个执行的线程开始扩容后,CAS将sizeCtrl置为一个负数
1. 如果当前数组为空,进行初始化,和2类似
2. 如果容量为达到扩容阈值(sizeCtl为正的情况)或者容量达到扩容上限,退出
3. 第一个线程开始扩容,通过CAS将sizeCtrl设置为负数,执行transfer(oldTable,null)方法
4. 当前执行的线程不是第一个线程,CAS将sizeCtl值加1,执行transfer(oldTable,nextTable)
6. 协助数据迁移(helpTransfer方法)
之前说到,检测到当前节点的哈希值=MOVED,说明正在扩容,当前线程会协助数据转移。
获取到新数组(这个数组已经由第一个扩容的线程创建好了),CAS将sizeCtl值加1,执行transfer(oldTable,nextTable)
7. get方法
根据key算到所在的桶,并查找。比较特殊是当前节点的哈希值小于0,可能当前节点是红黑树,可能是ForwardingNode。那么调用ForwardingNode#find方法或TreeBin#find方法,对于正在扩容的情况,会从新表中查找。因为Node节点及其子类的value属性都是volatile修饰的,所以不需要加锁也能保证可见性。注意Node数组的volatile属性是为了扩容新数组的可见性。
8.size方法和mappingCount方法
size方法是Map接口定义的,返回类型是int,有大小的限制,因此concurrentHashMap又定义了mappingCount方法,返回值是long。内部都是调用的sumCount方法。
concurrentHashMap关于size的统计信息有两个:long baseCount和CounterCell[] counterCells。
当从未产生过并发冲突时只会用到baseCount,counterCells是空的,一旦产生冲突后,后续都只会更新counterCells。
在元素增加和删除时会更新这两个变量,比如put操作最后的addCount方法。如果counterCells为空,CAS将baseCount+1,如果失败了或者counterCells不为空,则CAS更新counterCells中的随机一个元素,将其value自增。如果这个操作也失败了,会有死循环重试机制确保成功。
所以获取大小时,会将baseCount和counterCells中所有元素保存的value叠加返回,这个操作是不需要加锁的,很快但是不准确(实时)。
附录
1. 处理桶迁移时的倒序遍历(JDK8)
transfer方法部分源码如下
1 boolean advance = true; 2 boolean finishing = false; // to ensure sweep before committing nextTab 3 for (int i = 0, bound = 0; ; ) { 4 Node<K, V> f; int fh; 5 while (advance) { //advance为true代表上一个for循环已经处理完手头的桶的迁移,需要进入这个判断是否再次分配下一个区间,用while循环是因为下面的CAS可能失败需要轮询 6 int nextIndex, nextBound; 7 if (--i >= bound || finishing) //正在处理还没有到达边界 或者是 二次检查准备替换新旧数组 8 advance = false; 9 else if ((nextIndex = transferIndex) <= 0) { //全部迁移完毕 10 i = -1; 11 advance = false; 12 } 13 else if (U.compareAndSwapInt //CAS将transferIndex向前推移,这个操作就是分配下一个区间给当前线程,失败while会负责重试 14 (this, TRANSFERINDEX, nextIndex, 15 nextBound = (nextIndex > stride ? nextIndex - stride : 0))){ 16 bound = nextBound; //设置新的区间的边界坐标 17 i = nextIndex - 1; //设置新的区间的起点坐标 18 advance = false; 19 } 20 } 21 //... 22 }
上面说到迁移的思想是将整个数组分成若干个小区间,每个线程领取一个区间来处理。 for (int i = 0, bound = 0;;) 这里的 i 代表区间的起点坐标,bound代表边界坐标。这个处理过程是倒序的。
transferIndex代表的分配的起点,初始是数组的总长,当transferIndex小于0时代表全部迁移完毕。假设初始大小20,步长取最小值16。
第一个线程开始处理,进入循环到行9,这里nextIndex赋值为transferIndex,继续到行13,这个CAS操作负责分配下一个新的处理区间,nextBound计算的就是下一个区间的边界,计算方法是用分配起点减去步长,这里计算得到20-16=4。
第一个线程申请区间完毕,分配新区间的起点为20-1=19,边界是4。这就是倒序的由来。当处理完一个桶后,再次进入行5,此时行7判断 --i >= bound (即18>4),代表还没处理完分配的区间,不会再次分配,继续处理这个区间的数据迁移。
2.为什么大小总是2的幂次方
1. 算出key的哈希值,需要跟数组大小取余运算,得到存放坐标,如果数组大小是2的幂次方,相当于跟数组大小-1做与运算。即 hash_code % table_len = hash_code & (table_len-1)。而位运算是很快的
2. 减少哈希碰撞,接着1,table_len-1的二进制最后一位是1,这样跟key的哈希值做与运算,结果可能是1也可能是0。如果最后一位是0,那么做与运算后只会等于0,相当于少了一半的存放空间。这也是数组大小最好是偶数的原因。
参考:
1. https://crossoverjie.top/2018/07/23/java-senior/ConcurrentHashMap/
2. 很好的源码讲解 https://blog.csdn.net/sihai12345/article/details/79383766
3. https://blog.csdn.net/u012403290/article/details/68485855
4. 纠正sizeCtl属性 https://blog.csdn.net/Unknownfuture/article/details/105350537
5. 很好的源码讲解 https://www.cnblogs.com/sanzao/p/10792546.html