如下是常见的一些node.js写的爬虫,适合会点js的同学使用。
1.爬取网页信息
let axios = require('axios')
let fs = require('fs')
let httpUrl = 'https://www.1905.com/vod/list/n_1_t_1/o3p1.html'
function req(link) {
return new Promise(function (resolve, reject) {
axios.get(link).then(function (res) {
resolve(res.data)
})
})
}
// 获取起始页面的所有分类地址
async function getClassUrl(link) {
let data = await req(link)
// 解析HTML内容
let reg = /<span class="search-index-L">类型(.*?)<div class="grid-12x">/gis
let result = reg.exec(data)[1]
// console.log(result);
let reg1 = /<a href="javascript:void(0);" onclick="location.href='(.*?)';return false;" .*?>(.*?)</a>/gis
let arr = []
while ((result2 = reg1.exec(result))) {
if (result2[2] != '全部') {
let obj = {
className: result2[2],
link: result2[1],
}
arr.push(obj)
await fs.mkdir('./movies/' + result2[2],function(error){
})
getMovie(result2[1], result2[2])
}
}
// console.log(arr);
}
// 获取分类里的电影连接
// 根据电影连接获取电影的详细信息
// 通过分类获取页面中的连接
async function getMovie(link, movieType) {
let data = await req(link)
let reg = /<a class="pic-pack-outer" target="\_blank" href="(.*?)" .*?>/gis
var res9
var arrList = []
while ((res9 = reg.exec(data))) {
arrList.push(res9[1])
parsePage(res9[1], movieType)
}
// console.log("分类:" + movieType);
// console.log(arrList);
}
async function parsePage(url, movieType) {
// console.log(url);
let data = await req(url)
let reg = /<h1 class="playerBox-info-name playerBox-info-cnName">(.*?)</h1>.*?id="playerBoxIntroCon">(.*?)<a .*?导演.*?data-hrefexp="fr=vodplay\_ypzl\_dy">(.*?)</a>/gis
let res3 = reg.exec(data)
console.log(res3[1])
let movie = {
name: res3[1],
brief: res3[2],
daoyan: res3[3],
movieUrl: url,
movieType,
}
let str = JSON.stringify(movie)
fs.writeFile('./movies/' + movieType + '/' + res3[1] + '.json', str,function(error){
})
}
getClassUrl(httpUrl)
生成效果
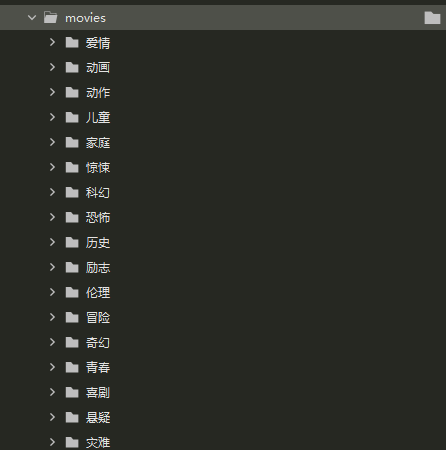
2.爬取音乐并下载
const axios = require('axios')
const fs = require('fs')
const path = require('path')
// 目标:下载音乐
// 1.获取音乐相关的信息,通过信息获取下载地址
// 2.通过获取音乐列表获取音乐信息
// 3.通过音乐的分类页获取音乐列表
async function getPage(num) {
let httpUrl = 'http://www.app-echo.com/api/recommend/sound-day?page=' + num
let res = await axios.get(httpUrl)
// console.log(res.data.list);
let list = res.data.list
list.forEach(function (item, i) {
let title = item.sound.name
let musicUrl = item.sound.source
let fileName = path.parse(musicUrl).name
let content = `${title},${musicUrl}.${fileName}
`
fs.writeFile('music.txt', content, { flag: 'a' }, function () {
// console.log('写入完成:'+ title);
})
// console.log(path.parse(musicUrl));
download(musicUrl, fileName)
})
}
async function download(link, fileName) {
let res = await axios.get(link, { responseType: 'stream' })
let ws = fs.createWriteStream('./music/' + fileName + '.mp3')
console.log(res.data)
res.data.pipe(ws)
res.data.on('close', function () {
ws.close()
})
}
// 爬一页意思一下就行了
getPage(1)
3.爬取表情包并下载
const cheerio = require('cheerio')
const axios = require('axios')
const fs = require('fs')
const url = require('url')
const path = require('path')
// 将延迟函数封装成promise对象(防止请求速度过快下载失败)
function wait(millSeconds) {
return new Promise(function (resolve, reject) {
setTimeout(() => {
resolve('成功执行延迟函数,延迟时间:' + millSeconds)
}, millSeconds)
})
}
// 获取HTML文档的内容
// 获取页面总数
async function pageNum(link) {
let res = await axios.get(link)
let $ = cheerio.load(res.data)
let btnLength = $('.pagination li').length
let allNum = $('.pagination li')
.eq(btnLength - 2)
.find('a')
.text()
return allNum
}
// 获取页面
async function getListPage(pageNum) {
let httpUrl = `https://www.doutula.com/article/list/?page=${pageNum}`
let res = await axios.get(httpUrl)
let $ = cheerio.load(res.data)
$('#home .col-sm-9>a').each((i, element) => {
let pageUrl = $(element).attr('href')
let title = $(element).find('.random_title').text()
let reg = /(.*?)d/gis
title = reg.exec(title)[1]
fs.mkdir('./img/' + title, function (err) {
if (err) {
console.log(err)
} else {
console.log('创建:' + './img/' + title)
}
})
parsePage(pageUrl, title)
})
}
// 进入表情包页面
async function parsePage(link, title) {
let res = await axios.get(link)
let $ = cheerio.load(res.data)
$('.pic-content img').each((i, element) => {
let imgUrl = $(element).attr('src')
let b = url.parse(imgUrl)
let name = path.parse(b.pathname)
// 创建路径名字
let filePath = `./img/${title}/${name.base}/`
// 创建写入流
let ws = fs.createWriteStream(filePath.trim())
axios.get(imgUrl, { responseType: 'stream' }).then(function (res) {
res.data.pipe(ws)
console.log('正在下载表情:' + filePath)
// 监听事件,关闭写入流
res.data.on('close', () => ws.close())
})
})
}
// 开始爬取所有页面
async function spider(link) {
let allPageNum = await pageNum(link)
for (let i = 1; i <= allPageNum; i++) {
await wait(4000 * i) // 每个页面延迟3秒
getListPage(i)
}
}
spider('https://www.doutula.com/article/list/?page=1')
生成表情效果
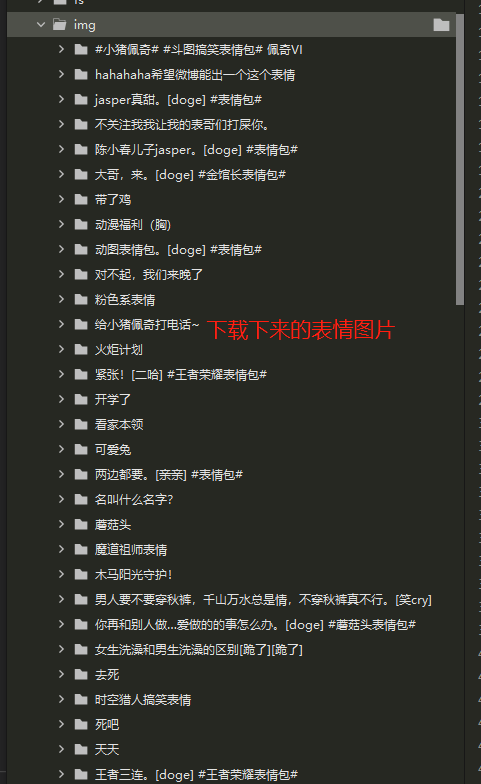
总结提示
编写爬虫主要是通过 axios 来进行发送请求,在这个过程中,我们要分析网页结构,和网站信息,来提取我们需要的信息,进行一个爬取。在这个过程中,大部分都是异步完成的,要记得加 await 。
在没有 cheerio 模块的时候,我们通过正则匹配来进行抓取,有了 cheerio 模块我们可以像使用 jquery 一样方便的来获取页面中的元素。
当然过程中也使用了 Node 的一些核心模块,包括 url 的解析,path 路径的解析,文件的读写,还有 stream 的操作等等,这次爬虫的小实战,也算是对前几天的学习的一个综合运用。
如需前端交流学习可加wx:844271163