一、kNN算法基础
# kNN:k-Nearest Neighboors
# 多用于解决分类问题
1)特点:
- 是机器学习中唯一一个不需要训练过程的算法,可以别认为是没有模型的算法,也可以认为训练数据集就是模型本身;
- 思想极度简单;
- 应用数学知识少(近乎为零);
- 效果少;
- 可以解释机械学习算法使用过程中的很多细节问题
- 更完整的刻画机械学习应用的流程;
2)思想:
- 根本思想:两个样本,如果它们的特征足够相似,它们就有更高的概率属于同一个类别;
- 问题:根据现有训练数据集,判断新的样本属于哪种类型;
- 方法/思路:
- 求新样本点在样本空间内与所有训练样本的欧拉距离;
- 对欧拉距离排序,找出最近的k个点;
- 对k个点分类统计,看哪种类型的点数量最多,此类型即为对新样本的预测类型;
3)代码实现过程:
- 示例代码:
import numpy as np import matplotlib.pyplot as plt raw_data_x = [[3.3935, 2.3312], [3.1101, 1.7815], [1.3438, 3.3684], [3.5823, 4.6792], [2.2804, 2.8670], [7.4234, 4.6965], [5.7451, 3.5340], [9.1722, 2.5111], [7.7928, 3.4241], [7.9398, 0.7916]] raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1] # 训练集样本的data x_train = np.array(raw_data_x) # 训练集样本的label y_train = np.array(raw_data_y) # 1)绘制训练集样本与新样本的散点图 # 根据样本类型(0、1两种类型),绘制所有样本的各特征点 plt.scatter(x_train[y_train == 0, 0], x_train[y_train == 0, 1], color = 'g') plt.scatter(x_train[y_train == 1, 0], x_train[y_train == 1, 1], color = 'r') # 新样本 x = np.array([8.0936, 3.3657]) # 将新样本的特征点绘制在训练集的样本空间 plt.scatter(x[0], x[1], color = 'b') plt.show() # 2)在特征空间中,计算训练集样本中的所有点与新样本的点的欧拉距离 from math import sqrt # math模块下的sqrt函数:对数值开平方sqrt(number) distances = [] for x_train in x_train: d = sqrt(np.sum((x - x_train) ** 2)) distances.append(d) # 也可以用list的生成表达式实现: # distances = [sqrt(np.sum((x - x_train) ** 2)) for x_train in x_train] # 3)找出距离新样本最近的k个点,并得到对新样本的预测类型 nearest = np.argsort(distances) k = 6 # 找出距离最近的k个点的类型 topK_y = [y_train[i] for i in nearest[:k]] # 根据类别对k个点的数量进行统计 from collections import Counter votes = Counter(topK_y) # 获取所需的预测类型:predict_y predict_y = votes.most_common(1)[0][0]
- 封装好的Python代码:
import numpy as np from math import sqrt from collections import Counter def kNN_classify(k, X_train, y_train, x): assert 1 <= k <= X_train.shape[0],"k must be valid" assert X_train.shape[0] == y_train.shape[0], "the size of X_train nust equal to the size of y_train" assert X-train.shape[1] == x.shape[0], "the feature number of x must be equal to X_train" distances = [sprt(np.sum((x_train - x) ** 2)) for x_train in X_train] nearest = np.argsort(distances) topK_y = [y_train[i] for i in nearest[:k]] vates = Counter(topK_y) return votes.most_common(1)[0][0]
# assert:表示声明;此处对4个参数进行限定;
- 代码中的其它Python知识:
-
math模块下的sprt()方法:对数开平方;
from math import sqrt print(sprt(9)) # 3
- collections模块下的Counter()方法:对列表中的数据进行分类统计,生产一个Counter对象;
from collections import Counter my_list = [0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3] print(Counter(my_list)) # 一个Counter对象:Counter({0: 2, 1: 3, 2: 4, 3: 5})
- Counter对象的most_common()方法:Counter.most_common(n),返回Counter对象中数量最多的n种数据,返回一个list,list的每个元素为一个tuple;
from collections import Counter my_list = [0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3] votes = Counter(my_list) print(votes.most_common(2)) # [(3, 5), (2, 4)]
二、总结
1)k近邻算法的作用
1、解决分类问题,而且天然可以解决多分类问题;
2、也可以解决回归问题,其中scikit-learn库中封装的KNeighborsRegressor,就是解决回归问题;
2)缺点
- 缺点1:效率低下
- 原因:如果训练集有m个样本,n个特征,预测每一个新样本,需要计算与m个样本的距离,每计算一个距离,要使用n个时间复杂度,则计算m个样本的距离,使用m * n个时间复杂度;
- 算法的时间复杂度:反映了程序执行时间随输入规模增长而增长的量级,在很大程度上能很好反映出算法的优劣与否。
- 算法的时间复杂度与空间复杂度,参考:算法的时间复杂度和空间复杂度
- 可以通过树结构对k近邻算法优化:KD-Tree、Ball-Tree,但即便进行优化,效率依然不高;
- 缺点2:高度数据相关
- 机器学习算法,就是通过喂给数据进行预测,理论上所有机器学习算法都是高度数据相关;
- k近邻算法对outlier更加敏感:比如三近邻算法,在特征空间中,如果在需要预测的样本周边,一旦有两个样本出现错误值,就足以使预测结果错误,哪怕在更高的范围里,在特征空间中有大量正确的样本;
- 缺点3:预测的结果不具有可解释性
- 按k近邻算法的逻辑:找到和预测样本比较近的样本,就得出预测样本和其最近的这个样本类型相同;
- 问题:为什么预测的样本类型就是离它最近的样本的类型?
- 很多情况下,只是拿到预测结果是不够的,还需要对此结果有解释性,进而通过解释推广使用,或者制作更多工具,或者以此为基础发现新的理论/规则,来改进生产活动中的其它方面——这些是kNN算法做不到的;
- 缺点4:维数灾难
- 维数灾难:随着维度的增加,“看似相近”的两个点之间的距离越来越大;
- 例:[0, 0, 0, ...0]和[1, 1, 1,...1],按欧拉定理计算,元素个数越多,两点距离越大;
- 方案:降维(PCA);
三、使用机器学习算法的流程
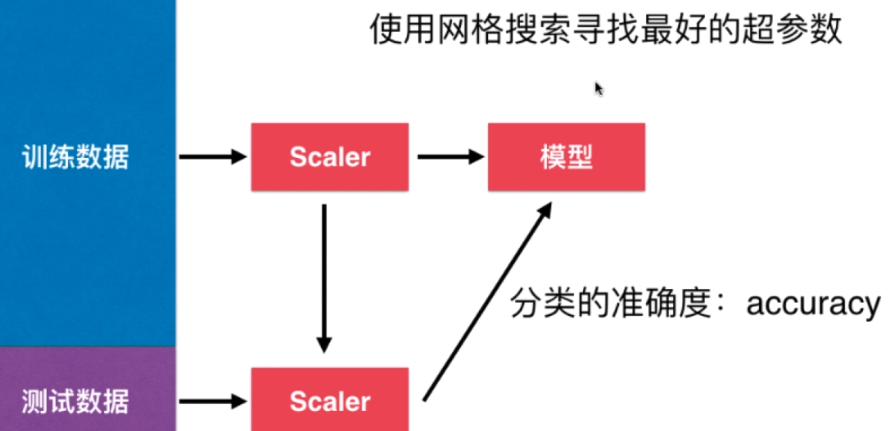
- 获取原始数据——数据分割——数据归一化——训练模型——预测
- 获取原始数据:一般可从scikit-learn库中调用——# 调用数据集的操作流程 机器学习:scikit-learn中算法的调用、封装并使用自己所写的算法
- 数据分割:一般按2 :8进行分割——# 分割数据的代码实现过程、通过scikit-learn库分割数据的操作流程 机器学习:训练数据集、测试数据集
- 数据归一化:参见 机器学习:数据归一化(Scaler)
- 训练模型、模型预测: 机器学习:scikit-learn中算法的调用、封装并使用自己所写的算法