前言
前面介绍的Queue都是通过Lock锁实现的阻塞队列,今天介绍一种非阻塞队列ConcurrentLinkedQueue,所谓非阻塞,其实就是通过CAS代替加锁来实现的高效的非阻塞队列。当许多线程共享对公共集合的访问时,ConcurrentLinkedQueue是一个合适的选择。与大多数其他并发集合实现一样,该类不允许使用空元素。
ConcurrentLinkedQueue是一个基于链表的无界线程安全的先进先出队列。虽然前面介绍的队列也有基于链表的实现,例如LinkedBlockingQueue以及SynchronousQueue的公平队列实现,但是ConcurrentLinkedQueue的链表实现与它们有本质的差别,LinkedBlockingQueue的链表实现存在总是指向第一个节点的虚拟head节点,以及始终指向队列最后一个节点的tail节点,但是ConcurrentLinkedQueue的head与tail则更加灵活多变,ConcurrentLinkedQueue有如下一些基本约束特性:
1.CAS入队的最后一个节点的next指向为null。
2.队列中的所有未删除节点是那些item不为null,并且都能从head节点访问到的节点,因为删除节点是通过CAS将其item引用置为null。迭代器会跳过那些item为null的节点。所以如果队列是空的,那么所有item当然都必须为空。
3.head并不总是指向队列的第一个元素,tail也并不总是指向队列的最后一个节点。
针对ConcurrentLinkedQueue的head与tail节点,有如下一些特性:
| 不变性 | 可变性 | |
| head |
1.所有未删除的节点都可以从head节点通过succ()方法访问到 2.head不会为null 3.head节点的next不会指向自身 |
1.head的item可能为null,也可能不为null 2.允许tail滞后于head,即允许从head通过succ()不能访问到tail。 |
| tail |
1.最后一个节点总是可以从tail通过succ()方法访问到 2.tail不会为null |
1.tail的item可能为null,也可能不为null 2.允许tail滞后于head,即允许从head通过succ()不能访问到tail。 3.tail节点的next可以指向自身,也可以不指向自身。 |
源码解析
进行源码解析之前,先看看ConcurrentLinkedQueue定义的内部节点类Node:


1 private static class Node<E> { 2 volatile E item; 3 volatile Node<E> next; 4 5 /** 6 * Constructs a new node. Uses relaxed write because item can 7 * only be seen after publication via casNext. 8 */ 9 Node(E item) { 10 UNSAFE.putObject(this, itemOffset, item); 11 } 12 13 boolean casItem(E cmp, E val) { 14 return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val); 15 } 16 17 void lazySetNext(Node<E> val) { 18 UNSAFE.putOrderedObject(this, nextOffset, val); 19 } 20 21 boolean casNext(Node<E> cmp, Node<E> val) { 22 return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); 23 } 24 25 // Unsafe mechanics 26 27 private static final sun.misc.Unsafe UNSAFE; 28 private static final long itemOffset; 29 private static final long nextOffset; 30 31 static { 32 try { 33 UNSAFE = sun.misc.Unsafe.getUnsafe(); 34 Class<?> k = Node.class; 35 itemOffset = UNSAFE.objectFieldOffset 36 (k.getDeclaredField("item")); 37 nextOffset = UNSAFE.objectFieldOffset 38 (k.getDeclaredField("next")); 39 } catch (Exception e) { 40 throw new Error(e); 41 } 42 } 43 }
Node节点内部类很简单,只包含节点数据item以及指向下一个节点的next引用,和其它一些辅助方法,这里不表,接下来看构造方法吧。
构造方法
1 private transient volatile Node<E> head; 2 3 private transient volatile Node<E> tail; 4 5 /** 6 * 构造一个空队列 7 */ 8 public ConcurrentLinkedQueue() { 9 head = tail = new Node<E>(null); 10 } 11 12 /** 13 * 构造一个包含给定集合元素的ConcurrentLinkedQueue实例 14 */ 15 public ConcurrentLinkedQueue(Collection<? extends E> c) { 16 Node<E> h = null, t = null; 17 for (E e : c) { //遍历 18 checkNotNull(e); 19 Node<E> newNode = new Node<E>(e); 20 if (h == null) 21 h = t = newNode; 22 else { 23 //这里使用延迟赋值是因为后面对head、tail的写是volatile写所以可以保证可见性 24 //延迟赋值采用putOrderedObject方法只关注不被重排序即可。 25 t.lazySetNext(newNode); 26 t = newNode; 27 } 28 } 29 if (h == null) 30 h = t = new Node<E>(null); 31 head = h; 32 tail = t; 33 }
构造方法也很简单,当构造空队列的实例时,其head于tail都指向同一个item为null的虚拟节点;当以给定集合构造实例时,head指向第一个元素,tail指向最后一个元素。
入队offer
ConcurrentLinkedQueue的入队操作add、offer都是通过offer方法实现的,它将指定的元素插入到队列的最后一个元素后面,下面看看其源码:
1 /** 2 * 将指定的元素插入到此队列的末尾。 3 * 因为队列是无界的,所以这个方法永远不会返回false。 4 * 5 * 如果指定的元素为null,抛出NullPointerException 6 */ 7 public boolean offer(E e) { 8 checkNotNull(e); 9 final Node<E> newNode = new Node<E>(e); 10 11 for (Node<E> t = tail, p = t;;) {//死循环,直到成功 12 Node<E> q = p.next; 13 //第一个if块 14 if (q == null) { //p是最后一个节点,尝试加入到队列最后一个元素后面 15 if (p.casNext(null, newNode)) { //CAS 尝试将新节点挂载到最后一个节点的next 16 // Successful CAS is the linearization point 17 // for e to become an element of this queue, 18 // and for newNode to become "live". 19 if (p != t) //最后一个节点距离tail大于1个节点时,更新tail指向最后一个节点 20 casTail(t, newNode); // Failure is OK. 为什么允许失败。因为tail可能被其它操作抢先设置好了 21 return true; 22 } //CAS失败,重新循环尝试。 23 // Lost CAS race to another thread; re-read next 24 }//第二个if块 25 else if (p == q) //到这里说明p节点已经被移除了。 26 // We have fallen off list. If tail is unchanged, it 27 // will also be off-list, in which case we need to 28 // jump to head, from which all live nodes are always 29 // reachable. Else the new tail is a better bet. 30 //tail节点已经被更新就取新的tail,否则取head,重新循环寻找最后一个节点尝试。 31 p = (t != (t = tail)) ? t : head; 32 else //第三个if块 33 //到这里说明tail并不是指向的队列中最后一个元素。 34 35 //这时候如果tail已经被其它操作更新了则取最新的tail,否则取p的next节点继续循环尝试。 36 // Check for tail updates after two hops. 37 p = (p != t && t != (t = tail)) ? t : q; 38 } 39 }
因为队列的无界的,所以操作在一个死循环中尝试,直到成功返回true。入队操作主要分三种情况(三个if块):
1. 找到了队列的最后一个元素(其next指向null),尝试将新节点加到其next,成功返回失败继续循环尝试。
2. 当前节点被移除了,需要重新定位起点进行循环找到最后一个元素,定位到哪儿取决于操作期间tail是否改变,tail改变则从新tail开始,否则只能从head开始。
3. 当前节点不是最后一个元素也没有被移除,这时候如果tail改变了则从新tail开始,否则直接从当前节点的next节点开始继续循环查找最后一个元素。
值得注意的是,在将新元素节点插入到最后一个节点之后,如果当前tail指向的节点距离队列最后一个节点超过一个节点时需要更新tail使其指向队列最后一个节点,否则不对tail做更新。由此可见,tail要么指向队列最后一个节点,要么指向队列的倒数第二个节点。如果发现有节点next指向自身则会认为是被移除的节点,从而摒弃它重新定位起点寻找最后一个节点。
下面以入队操作的图例来说明这个队列的变化过程,首先假设队列最开始是一个空队列,那么其head、tail都指向一个item为null的虚拟节点,如下所示:
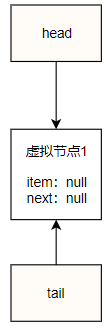
offer("A")
按照入队的逻辑分析过程为:tail指向的虚拟节点p的next为null,即q==p.next==null,所以直接执行第一个if块:p.casNext(null, newNode)将新节点挂载到虚拟节点p的next,成功之后由于tail指向的虚拟节点p==t,所以不会执行casTail(t, newNode)来更新tail指向刚才入队的节点,结束返回true,这时候队列的状态如下:
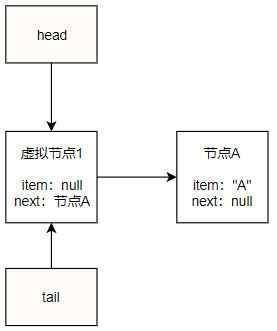
如上图所示,在入队第一个元素之后,head和tail亦然指向的当初的虚拟节点,虚拟节点指向刚才入队的节点A,这时候节点A就是队列的最后一个节点,tail并没有指向它。
offer("B")
接着我们再入队一个元素B,按照入队逻辑分析过程为:tail指向的虚拟节点p的next为A不为空,所以第一个if块不成立,并且q=p.next=A !=p,所以第二个if块也不成立,进入第三个if块执行p = (p != t && t != (t = tail)) ? t : q,假设此时tail并没有被其它线程更新,所以三目运算的条件不成立,p=q即p==A,进入第二轮循环。第二轮循环此时p指向节点A,其next为null,所以第一个if块成立,将新节点B插入A节点的next,这时候因为p指向节点A,t即tail依然指向虚拟节点1.所以p != t 执行casTail(t, newNode)将更新tail执行新入队的节点B,结束返回true,这时候队列的状态如下:
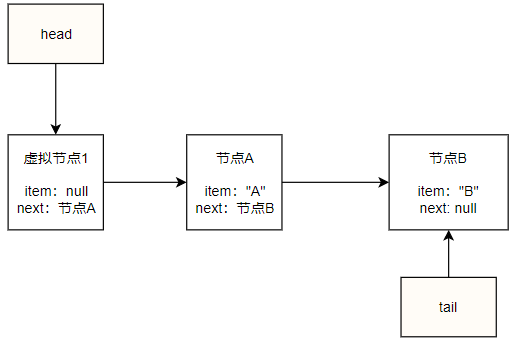
如上图所示,在节点B入队之后,head依然指向当初的虚拟节点,但tail节点被更新指向到了最后一个节点,所以ConcurrentLinkedQueue会保证tail节点与队列最后一个节点直接的距离不超过一个节点,当超过时会更新tail指向最后一个节点,依次类推,加入我们再执行offer("C"),那么队列将变成这样:
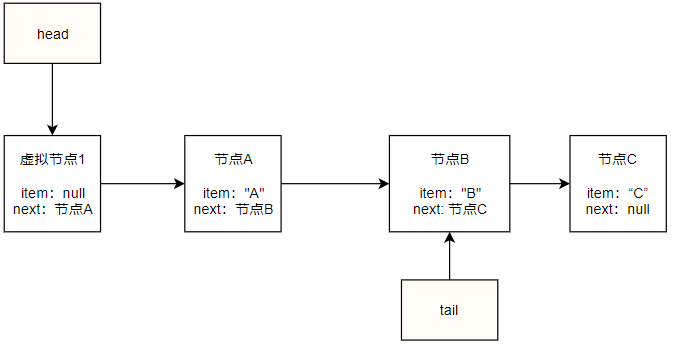
tail的这种并不是每次都需要更新的策略可以提高程序的并发度,尽量减少不必要的CAS操作,但是程序的复杂度不言而喻变得更复杂难懂。
出队poll()
1 public E poll() { 2 restartFromHead: 3 for (;;) { 4 for (Node<E> h = head, p = h, q;;) { 5 E item = p.item; 6 7 //第一个if块,p.item 不为null,则将item 设置为null 8 if (item != null && p.casItem(item, null)) { 9 //出队的p节点不是head,如果p后面还有节点更新head指向p.next,否则指向p,原head指向自身 10 if (p != h) // hop two nodes at a time 11 updateHead(h, ((q = p.next) != null) ? q : p); 12 return item; 13 }//第二个if块,到这里说明p节点item为null或者已经被其它线程抢先拿走(casItem失败), 14 // p.next == null 说明被其它线程抢先拿走的p是队列中最后一个有效节点,现在队列已经空了 15 else if ((q = p.next) == null) { 16 updateHead(h, p); //更新head指向p,将原来的head的next指向自身 17 return null; 18 }//第三个if块,到这里说明p已经被其它线程抢先拿走了,需要重新开始循环 19 else if (p == q) 20 continue restartFromHead; 21 else//第四个if块,到这里说明p是一个虚拟节点,并且队列不为空,继续看它的下一个节点q 22 p = q; 23 } 24 } 25 }
入队逻辑主要在tail节点处做处理,而出队当然是从头部出队,所以在head节点处做处理,出队的逻辑也是由包含4个if块的死循环构成:
1. 从head处出发发现第一个item不为空的节点,则CAS更新item为null,如果出队的节点不是指向head就需要将head指向新的节点(队列不为空指向下一个节点,为空指向出队的节点),原head的next指向自身。
2. 发现队列为空了,更新head指向最后一个无效节点(item,next都为null),原head的next指向自身。
3. 节点抢先被其它线程拿走了,则重新从head处开始寻找第一个有效节点(item不为空)
4. 如果当前节点是一个虚拟节点(比如第一次)并且队列不为空,那么指向下一个节点继续尝试。
由于队列实际是以一个节点实例包装实际数据存储在队列中的,出队时只需要拿到实际的节点数据而不关心其依附的节点,所以出队时其依附的节点并不一定会被移除,而仅仅是将其item置空了,下面以实际的操作来观察队列的变化。
第一次poll()
以上面包含A,B,C三个节点的队列为例,执行第一次poll操作:由于head指向的是一个虚拟节点,其item为null所以第一个if块不成立,队列不为空第二个if也不成立,虚拟节点的next为节点A不为空第三个if块也不成立,所以进入第四个if块p指向虚拟节点的next即节点A,进入下一次循环,节点A的item不为空,执行第一个if块的p.casItem(item, null),假设成功,此时head指向虚拟节点,而p指向的节点A,并且A节点的next为节点B不为空,所以执行updateHead(h, 节点B),所以head会指向节点B,原来的head即虚拟节点1会指向自身,而节点A除了其item被置为null没有任何变化,最终队列如下:
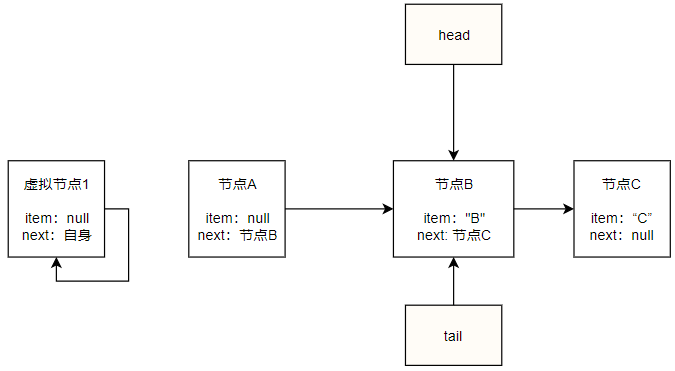
由上图看出,poll拿走A之后,节点A并没有被移除而仅仅是其item被置空,而是原head指向的虚拟节点1把next指向了自身从而脱离了队列,新的head指向了节点B.
第二次poll()
如果再次poll:此时head指向节点B,其item不为空,第一个if块成立,执行第一个if块的p.casItem(item, null),假设成功,此时head指向节点B,所以p != h不成立直接返回B,此时队列状态如下:
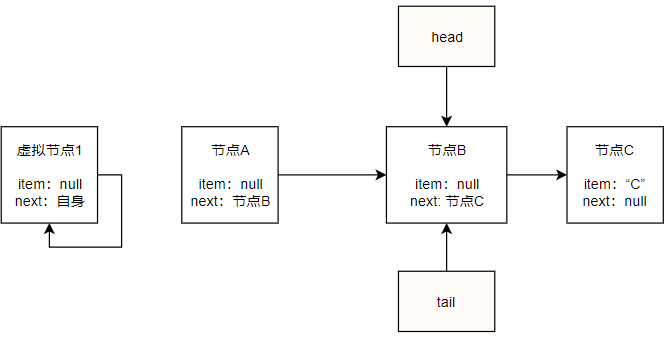
此时由于head指向的节点B即是被出队的节点数据,所以head并不会被更新,head这种类似tail一样并不是每次都更新的策略也一样能够减少CAS的次数提高并发度。
第三次poll()
此时head指向item为null的节点B,所以同第一次poll一样,前三个if块都不成立,第四个if块将p定位到下一个节点C,第二次循环开始,第一个if块满足,执行p.casItem(item, null)将节点C的item置为null,由于此时p指向节点C,head指向节点B,所以p !=h成立,并且节点C的next为null,所以执行updateHead(h, 节点C);最终head指向节点C,节点B指向自身,队列状态如下:

上图证明了ConcurrentLinkedQueue允许tail滞后于head,即允许从head通过succ()不能访问到tail这一特性,以及tail节点的next可以指向自身的特性。
offer("D")
在三次poll之后,队列其实已经空了,并且根据上图head指向C,tail指向的B,如果这时候我们入队元素D,会怎么样?此时tail指向节点C,节点C的next为null,满足第一个if块,执行p.casNext(null, newNode)将节点D挂载到节点C之后,并且因为tail指向的节点B,所以p!=t执行casTail(t, newNode)将tail指向了节点D.此时队列的状态如下:

此时head指向节点C,tail指向节点D.左边的链表部分已经脱离了队列变得无意义。
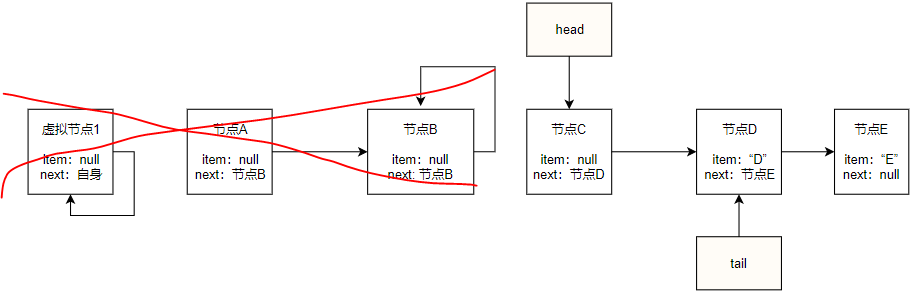
offer("E")
如果再次入队一个元素E,此时tail指向节点D,节点D的next为null,所以满足第一个if块,执行p.casNext(null, newNode)将新节点E插入到节点D后面,并且p即节点D == t即tail,所以不会更新tail,直接返回true,最后队列如下:
其它辅助方法
获取但不移除peek()
1 public E peek() { 2 restartFromHead: 3 for (;;) { 4 for (Node<E> h = head, p = h, q;;) { 5 E item = p.item; 6 //item不为空,或者队列为空 7 if (item != null || (q = p.next) == null) { 8 updateHead(h, p); //更新head指向p,原head指向自身 9 return item; //返回 10 }//到这里说明当前节点item为空并且队列不为空,如果当前节点p已经被移除,重新循环 11 else if (p == q) 12 continue restartFromHead; 13 else //到这里说明当前节点是一个item为空的节点,并且队列不为空那么循环其下一个节点 14 p = q; 15 } 16 } 17 }
peek虽然仅仅是获取但不移除节点,但是也会在返回去更新head,以上面offer("A")之后的队列为例,此时执行peek:head指向虚拟节点1,其item为null,其next指向节点A不为null,第一个if条件不成立,假设此时没有其它线程将虚拟节点移除,自然第二个if块也不成立,到第三个if块使p指向节点A,继续下一轮循环,此时p指向的节点A其item不为null,第一个if条件成立,执行updateHead(h, p),将head指向节点A,原来的head指向自身,最后返回“A”,最终队列的状态如下:

此时从head不可访问tail,如果此时继续执行peek,那么head指向节点A,其item不为null,第一个if条件成立,执行updateHead(h, p);由于updateHead里面存在 if (h != p && casHead(h, p))这样的判断,此时h == p所以并不会执行更新head的操作。当队列为空时,peek将返回null。
Node<E> first()
另一个first方法和peek方法其实逻辑完全一样,不同的是first返回的是包装数据的节点,而peek返回的是节点包装的数据,这里就不做分析了。
final Node<E> succ(Node<E> p)
如果p节点的next指向自身则返回head,否则返回p.next。
public int size()
返回此队列中的元素数量,如果超过了Integer.MAX_VALUE,返回Integer.MAX_VALUE,由于队列的异步性,此方法返回结果并不一定正确,或者说仅仅是一个舜态值。
public boolean contains(Object o)
如果此队列包含指定的元素,则返回true。更正式地说,当且仅当此队列包含至少一个元素e,使得o.equals(e)时返回true。注意比较的是真正的数据而不是节点哦。
public boolean remove(Object o)
从队列中移除一个与指定元素数据相等的实例,即使队列中存在多个相等的也仅仅只移除一个,注意比较的是节点数据。remove方法会使对应节点的item被置为null,并且使该节点的前一个节点的next指向被移除节点的下一个节点,即修改next跳过了这个被置空了item的节点。
public boolean addAll(Collection<? extends E> c)
将指定集合中的所有元素按照指定集合的迭代器返回的顺序追加到此队列的末尾。试图将队列添加到自身会导致IllegalArgumentException即c == this。该方法先把指定集合C中的元素构造成一个链表,最后再把这个链表的head链接到当前ConcurrentLinkedQueue队列的尾部,然后更新tail指向新的尾节点。
public Object[] toArray()
按适当的顺序返回包含此队列中所有非空元素(item不为null)的数组。该方法会分配一个新数组存储队列中每个节点的item引用,所以调用者可以随意修改返回的数组并不会对原队列产生任何影响。此方法充当数组和集合之间的桥梁API。
public <T> T[] toArray(T[] a)
与toArray()方法不同在于它会尝试将队列中的item数据的类型转换成指定的类型并存储在指定的数组中,如果类型匹配并且指定的数组容量足够的话。否则将按照指定数组的运行时类型和该队列的大小分配一个新数组用于存储队列中item不为null的元素。数组中紧跟在队列末尾的元素将会被设置成null,因此调用者可以通过判断数组中出现的第一个null来判断队列元素已经结束。这种方法允许对输出数组的运行时类型进行精确控制,在某些情况下,还可以用来节省分配成本。toArray(new Object[0])在形式上与toArray()是完全相同的。
该类不能保证批量操作addAll、removeAll、retainAll、containsAll、equals和toArray的原子性。例如,与addAll操作并发操作的迭代器可能只会看到一部分添加的元素。
内存一致性影响:
与其他并发集合一样, 一个线程先将一个对象放入ConcurrentLinkedQueue的动作 happen-before 后来的线程从ConcurrentLinkedQueue中执行访问或者删除该元素的操作。
迭代器
ConcurrentLinkedQueue的迭代器在创建实例的时候就已经拿到了第一个节点以及节点item数据,每一次执行next的时候又准备好下一次迭代的返回对象,同ArrayBlockingQueue一样,它也有一个lastRet变量用来暂时存储当前迭代的节点,用于在it.next调用完成之后,调用it.remove()时避免删除不应该删除的元素。
1 public Iterator<E> iterator() { 2 return new Itr(); 3 } 4 5 private class Itr implements Iterator<E> { 6 7 /** 8 * 下一次调用next时对应的节点 9 */ 10 private Node<E> nextNode; 11 12 /** 13 * nextItem引用item对象,因为一旦我们声明hasNext()中存在一个元素,我们必须在下一个next()调用中返回它,即使它在hasNext()过程中被删除。 14 */ 15 private E nextItem; 16 17 /** 18 * 上一次next返回的item对应的节点,用于remove() 19 */ 20 private Node<E> lastRet; 21 22 Itr() { 23 advance(); 24 } 25 26 /** 27 * 移动到下一个有效节点并返回调用next()时的返回值,如果没有,则返回null。 28 */ 29 private E advance() { 30 lastRet = nextNode; 31 E x = nextItem; 32 33 Node<E> pred, p; 34 if (nextNode == null) { 35 p = first(); 36 pred = null; 37 } else { 38 pred = nextNode; 39 p = succ(nextNode); 40 } 41 42 for (;;) { 43 if (p == null) { 44 nextNode = null; 45 nextItem = null; 46 return x; 47 } 48 E item = p.item; 49 if (item != null) { 50 nextNode = p; 51 nextItem = item; 52 return x; 53 } else { 54 // 跳过item为null的节点 55 Node<E> next = succ(p); 56 if (pred != null && next != null) 57 pred.casNext(p, next);//辅助断开无效节点 58 p = next; 59 } 60 } 61 }
在创建迭代器实例的时候执行了一次advance()方法,准备好了第一个有效节点nextNode,以及其item引用,hasNext直接判断nextNode不为空即可,保证了迭代器的弱一致性,一旦hasNext返回true,那么调用next一定会得到相对应的item,即使在者之间该节点item已经被置为空了。
1 public boolean hasNext() { 2 return nextNode != null; //检测的nextNode节点 3 } 4 5 public E next() { 6 if (nextNode == null) throw new NoSuchElementException(); 7 return advance(); //还是调用的advance(); 8 } 9 10 public void remove() { 11 Node<E> l = lastRet; 12 if (l == null) throw new IllegalStateException(); 13 // rely on a future traversal to relink. 14 l.item = null; //将item置为null 15 lastRet = null; 16 }
next方法还是调用的advance()方法,remove方法借助了lastRet来将item置为null,由于直接操作的队列中的节点,所以迭代器的remove会真正的将队列中的节点item置为空,从而影响ConcurrentLinkedQueue队列本身。
可拆分迭代器Spliterator
ConcurrentLinkedQueue实现了自己的可拆分迭代器CLQSpliterator,从spliterator方法就可以看到:
public Spliterator<E> spliterator() { return new CLQSpliterator<E>(this); }
可拆分迭代器的 tryAdvance、forEachRemaining、trySplit方法都是非阻塞的,tryAdvance获取第一个item不为空的节点数据做指定的操作,forEachRemaining循环遍历当前迭代器中所有没有被移除的节点数据(item不为空)做指定的操作源码都很简单,就不贴代码了,至于它的拆分方法trySplit,其实和LinkedBlockingQueue的拆分方式是一样的,代码都几乎一致,它不是像ArrayBlockingQueue那样每次分一半,而是第一次只拆一个元素,第二次拆2个,第三次拆三个,依次内推,拆分的次数越多,拆分出的新迭代器分的得元素越多,直到一个很大的数MAX_BATCH(33554432) ,后面的迭代器每次都分到这么多的元素,拆分的实现逻辑很简单,每一次拆分结束都记录下拆分到哪个元素,下一次拆分从上次结束的位置继续往下拆分,直到没有元素可拆分了返回null。
总结
ConcurrentLinkedQueue很多时候都是与LinkedBlockingQueue相对应的,ConcurrentLinkedQueue使用CAS实现了非阻塞的队列操作,而不是像LinkedBlockingQueue那样的双锁实现,ConcurrentLinkedQueue虽然也有head、tail节点的概念,但是不同于LinkedBlockingQueue,ConcurrentLinkedQueue的head并不是总是指向第一个节点,tail也不一定总是指向最后一个节点,只有当当前指针距离第一个/最后一个节点有两个或更多步时,才将更新head/tail,这种减少CAS次数的设计是一种优化,总的来说它比起LinkedBlockingQueue来说,ConcurrentLinkedQueue更多的使用与多线程共享访问同一个集合这种场景。