


运行效果如下:
详细代码分析过程如下:
(1)导入需要用到的python包或函数




(4)将dataset数据进行归一化处理,使用kmeans函数进行聚类,输入第一个参数是数据,第二个参数为聚类个数2,k-means最后输出的结果其实是两维的,第一维是聚类中心,第二维是损失distortion,新建一个celltype变量,用来保存最后处理的图片,所以它对应dataset数据集来说,只有1列,有一张图片所有像素总和(面积)那么多行。对dataset归一化处理后得到对应的数据集whitened进行enumerate(这个函数返回数组元素值的同时,也返回这个值所对应的数组下标)。在上面执行了:centroids,distortion=kmeans(whitened,2),意义在于:把whitened所有的数据分成两类(两部分),并且这两类(两部分)数据都又分别对应着有一个中心(或者称它为质点)centroids。把whitened里的每一个元素和这两个质点进行求解它的欧几里得距离(也就是点和点之间的距离),如果距离0类比较近:d1>d2那么对应的图片celltype的位置的数值就赋值0。否则对应的图片celltype的位置的数值就赋值1。经过这个for循环之后,就会得到最后那张图片的每个像素的特征(或者可以说成是这个像素它是0类会是1类:最后那张图片哪里需要着色,哪里不需要着色),celltype其实就是记录了最后那张图片的每个像素的特征,所以也可以把它称为最后我们感兴趣那张图片的特征向量。

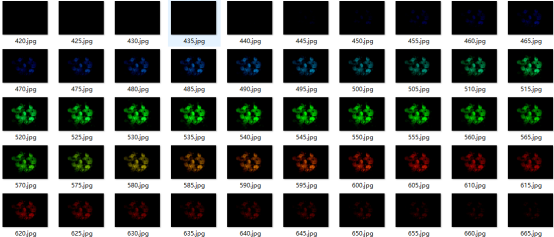
(5)读出dataset图片,并且获取它的第1通道值和求出这个通道值的最大方差,保存并显示大于这个方差值的图片。
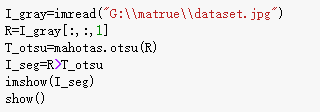

(6)读取样本的550.jpg图片的第1通道值,并且只选择大于80的值保存在变量II中,保存并显示II图片。

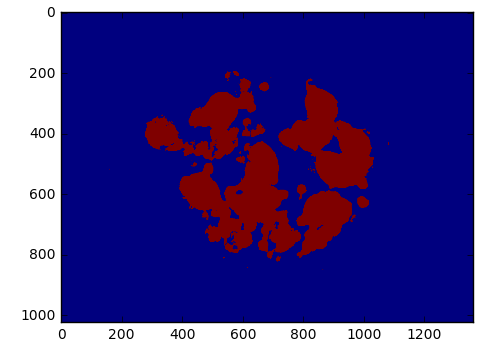
(7)将II的里面的数值类型变为浮点型,定义一个pix_num变量,作为celltype图片特征矩阵(向量)的下标,用来每次对图片I_seg_float涂色后换行用的。I_seg_float和I_seg一样也是一个二维数组,使用enumerate依次迭代出它里面的元素的值,并且同时将这个值的下标也返回了。如果图片I_seg_float数组里面的元素不是0那么就代表着是我们需要着色的一个像素点(也就是我们感兴趣的地方),这个像素的位置就是I_seg_float[j,k],而它被涂上的颜色值是:这个像素的特征值celltype[pix_num]乘以100后再加100。涂完色就换行pix_num+=1.再将I_seg_float图片类型转化成uint8类型。输出并保存I_seg_result图片。


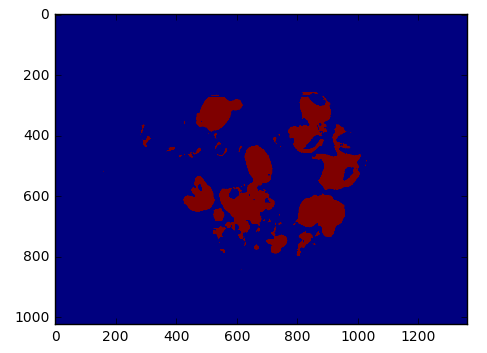
(8)读取上面I_seg_result.jpg图片,并取得它第1通道大于50的值保存在III中,保存并显示这个图片变量。

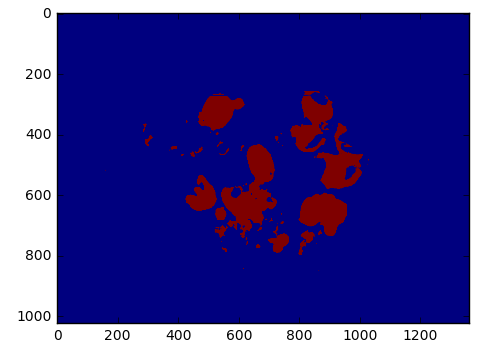
(9)读取上面第(6)、(8)保存的两张图片,并且都获取它们第0通道的值,并且其中第(8)保存的那张图片获取里面大于100的值。显示如下:


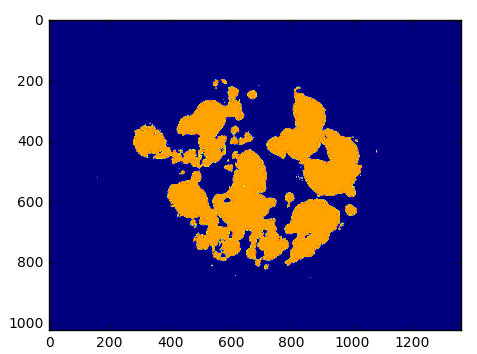
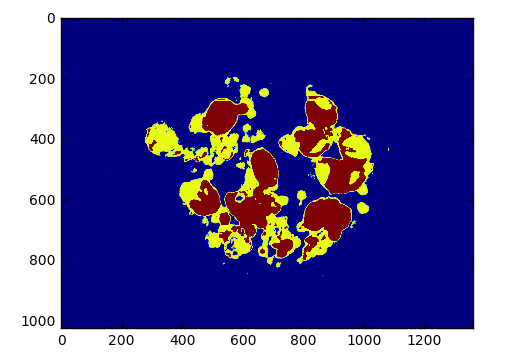
(10)上面的第三幅图是根据筛选处理后需要保留的红色区域,下面的两个for循环就是把第三幅图绘制到第二幅图里面,这样就可以看到很清晰的细胞与非细胞的对比效果了。如下图所示:



实验总结 第一种图片处理方法使用的k-means算法。这个算法的理论比较完善,并且实现起来也不是很麻烦,但是它需要进行大量较为复杂的簇的分类计算。关于开始质点选择如果不好直接导致算法的复杂度增加甚至失败(得到错误的分类结果)。从上面的三张最后图片中,通过相互比较可以看到,k-means算法得到的结果将一些细胞漏掉了。这很可能就是分类的结果不好造成的。 第二种图片处理方法是求和生存法。这个处理方法相对于上面的k-means算法,明显大大减低了运算复制度,并且实现起来也明显要比k均值算法要简单许多。它是通过直接获取图片所有全部信息的叠加(分类)结果,再取得一个合适显示的值得到需要显示的图片特征,然后根据这个特征来进行绘图就可以了。通过比较三张最后效果图片,可以发现这个种方法的处理得到的效果是最好的。这个方法的缺点是数学等学科理论依据不强,所以没有推广适用的普遍性,但它是上面处理得到的结果最好的,所以这种处理方法还有很大的成长完善的空间。 第三种图片处理方法是点方差聚类法。这个处理方法其实是我想对第二种完善,虽比k-means算法得到的结果好一点,但还是比不上简洁的第二种求和生存法。很容易看到这种方法的运算量和k-means的差不多,过程也相对要复杂了一点。它先是读取了所有图片,然后把所有图片变灰色,再获取每张灰色图片的特征分类值,最后累加到数据集dataset中。这种直接就利用数值分类方法要比k-means的好上许多,但它是对灰色图片获得的特征再累加,不是原图,分类的结果和k-means差不多,但比不上第二种的处理结果。 第四种图片处理方法是累加点方差聚类-K-means算法。它的处理结果要比上面的都要好些,但就是计算量比k-means的要复杂些。这种处理方法是先将初步处理的所有样本图片都累加保存到一个数组变量dataset中,然后使用k-means算法对这个变量进行聚类成两类,但k-means的缺点如上面第一种处理方法所说的,有可能会导致失败。但这种处理方法可以在一定程度上客服k-means这样的缺点,但运算量要增加些。使用k-means后,继续对图片进行分割、比较,所以在很大程度上,这样的处理方法会得到一个相对很好的处理结果。 通过这次的作业,我掌握了如何读取地图数据、获取地图坐标点的信息以及按特点格式输出地图坐标点等相关知识。通过使用三种不同的方法处理图片,我对图片的本质、图片的读取、图片的保存、图片着色、过滤、特征提取等方面技能都有很大的提高,对整体与部分、系统与统一等辩证思维方法和python代码的编写能力、分析能力等也有了进步一的提高。但在完成任务的过程中,发现还有许多的数学、python包的使用等方面的知识和技能存在不足,还需要继续坚持努力学习补充相关的知识和技能,才能够应对未来更多困难与挫折的挑战。 最后很感谢老师的指导和他的支持......