在学习王爽汇编第六章的时候,接触到在源程序中不同段的设置,如数据段、栈段、代码段的分别设置。
如下格式:
assume cs:code,ds:data,ss:stack data segment ... data ends stack segment ... stack ends code segment start: ... code ends end start
那么对于data段定义的数据来说,定义后CPU给这段数据的空间大小是如何确定的呢?通过第六章的实验题目,可以知道:数据段空间大小为定义数据所需的16字节的最小整数倍。比如定义了1个字节,系统就给数据段分配16个字节;定义了17个字节,系统就分配32个字节。
用一个简单的示例程序加载,查看:
assume cs:code,ds:data data segment db 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,10h,11h data ends code segment start: mov bx,1 mov ax,4c00h int 21h code ends end start
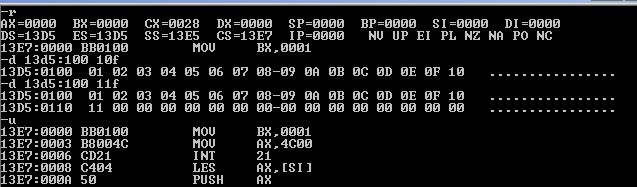
debug加载执行文件后,观察(ds)=13d5h,则13d5:0~13d5:ff为PSP区域,则13d5:100为源程序入口地址。
则通过-d 13d5:100 10f查看入口开始后16个字节,发现16个字节与数据段定义的前16个数据一致。
继续-d 13d5:100 11f查看入口开始的32个字节,发现17个字节与数据段定义的17个数据一致,并且后15个字节均为0.
那么我们可以得出一个结论:数据定义时候的17个字节被正确放入了内存,可是现在还不能验证数据段占据的空间是32个字节。
因为紧跟在数据段后面的就是代码段。
那么我们先用u命令查看代码对应的机器指令,可以观察到:代码段的入口地址为13e7:0000;也就是说从加载时候的入口到代码段入口之前的区域为data段区域,这段区域范围为:13d5:100~13e6:f,即13e50~13e6f.通过(13e6f-13e50+1)计算出这段区域大小为20H,即32个字节。
接下来还有一个疑问,如果定义时候数据段如下定义,那它在内存中如何排布和分配空间呢?
assume cs:code,ds:data data segment db 1,2,3 db 4,5 data ends code segment start: mov bx,1 mov ax,4c00h int 21h code ends end start
通过两次db定义,对上例来说,是分别分配两个16字节的空间分别存放两个db定义的数据,还是作为一个整体考虑呢?
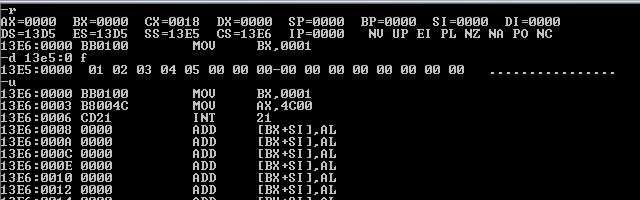
通过debug加载后查看内存,可以观察到定义时候虽然分成了两个db去定义,但内存中这5个数据是连续的,作为一个整体考虑。
ds在加载初始为13d5,即源程序入口地址为:13d50+100=13e50h;通过u命令,代码入口地址为13e60h;两者相减得到数据段空间为16个字节。
这里仍然要说明的一点是:
当程序加载到内存中的时候,DS寄存器存放的是整个程序包含其与系统的通讯信息(PSP)所占区域的段地址。即ds:0为整个程序和信息区的起始地址,PSP区占据开始的256个字节,即ds:0~ff为PSP区域。从ds:100开始才真正为源程序指令的入口地址。如本文上例,ds:100就为data段的段地址。并且,data标识符就注明了这一段地址,我们知道同一内存地址的段地址可以有多种设置,对这里而言,data标识符匹配的段地址是:“当偏移地址为0"时的段地址,所以data从数值上等于(ds+10h).而程序开头的assume只是伪指令,是提供给编译器的说明信息,并不会被转化为机器指令执行。所以当我们需要使用data段的数据时候,需要通过如下的指令设置:
... mov ax,data mov ds,ax ...
同样的,code标识符匹配的也为偏移地址为0情况下的段地址,因为cs直接就设置为该段地址,所以这里不需要通过代码特殊设置。