本文仅作经验分享,不做商业用途,如涉及权利问题,请通知删除。
scrapy+selenium爬取淘宝商品信息
建立scrapy项目
scrapy和selenium是爬虫常用的手段,现在我们开始新建个scrapy项目。
scrapy startproject taobao_s
cd taobao_s
scrapy genspider taobao s.taobao.com
建立一个taobao_s项目,在生成个spider taobao
生成项目结构如下
对目标网站进行分析
淘宝网反爬机制做的很全面,所以要爬取它要有一定条件。
首先淘宝网有个链接http://s.taobao.com/search?q=,这个链接能够不需要登录进行查询内容,但是我们爬虫时可能会被识别出来,所以我们应该尝试模拟登录淘宝保存cookie然后进行查询,这里我们模拟登录利用的是最近的办法,利用微博账号进行登录。接下来我们就进行selenium模拟登录。
selenium模拟登录
淘宝登陆页面https://login.taobao.com/member/login.jhtml
现在模拟登录常用的方法有支付宝账号登录(偶有滑块验证)、扫码登陆(最麻瓜的)、微博账号登陆(偶有验证码)本文利用的是微博账号进行登陆。
打开浏览器,进入页面,定位密码登陆,定位微博登陆,然后进行模拟登陆,值得一提的是同一账号登陆多次就会有验证码生成,建议多准备一些账号或者是加入输入验证码逻辑(穷学生用不起打码平台)登陆完成后利用get_cookies()来获取cookie保存下来,以下是登陆的代码
def loginTaobao():
url = 'https://login.taobao.com/member/login.jhtml'
options = webdriver.ChromeOptions()
# 不加载图片,加快访问速度
# options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
# 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# options.add_argument('--headless')
browser = webdriver.Chrome(executable_path="G:chromedriver_win32chromedriver.exe", options=options)
wait = WebDriverWait(browser, 10) # 超时时长为10s
# 打开网页
browser.get(url)
# 自适应等待,点击密码登录选项
browser.implicitly_wait(30) # 智能等待,直到网页加载完毕,最长等待时间为30s
browser.find_element_by_xpath('//*[@class="forget-pwd J_Quick2Static"]').click()
browser.find_element_by_xpath('//*[@class="weibo-login"]').click()
browser.find_element_by_name('username').send_keys('微博账号')
browser.find_element_by_name('password').send_keys('微博密码')
browser.find_element_by_xpath('//*[@class="btn_tip"]/a/span').click()
# 直到获取到淘宝会员昵称才能确定是登录成功
taobao_name = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,
'.site-nav-bd > ul.site-nav-bd-l > li#J_SiteNavLogin > div.site-nav-menu-hd > div.site-nav-user > a.site-nav-login-info-nick ')))
# 输出淘宝昵称
print(taobao_name.text)
cookies = browser.get_cookies()
browser.close() # 获取cookies便可以关闭浏览器
# 然后的关键就是保存cookies,之后请求从文件中读取cookies就可以省去每次都要登录一次的
jsonCookies = json.dumps(cookies) # 通过json将cookies写入文件
with open('taobaoCookies.json', 'w') as f:
f.write(jsonCookies)
print(cookies)
发起请求
一般建立scrapy项目会利用start_urls来发起请求,但是我们自己做的话还是利用start_requests来做居多。注释掉start_urls,编写start_requests的逻辑。
https://s.taobao.com/search?q=%s&sort=sale-desc&s=%s
这里用%s代表了一个搜索的内容;一个代表商品个数,淘宝的信息是以44个商品一页的,也就是换成45的话就是第二页了。这里我们可以用range构造一下后面这个参数。
在settings中定义三个参数
KEY_WORDS = “拖鞋 男” #搜索词
PAGE_NUM = 10 #页数
ONE_PAGE_COUNT = 44 #每页个数
def start_requests(self):
if not Path('taobaoCookies.json').exists():
__class__.loginTaobao() # 先执行login,保存cookies之后便可以免登录操作
# 从文件中获取保存的cookies
with open('taobaoCookies.json', 'r', encoding='utf-8') as f:
listcookies = json.loads(f.read()) # 获取cookies
# 把获取的cookies处理成dict类型
cookies_dict = dict()
for cookie in listcookies:
# 在保存成dict时,我们其实只要cookies中的name和value,而domain等其他都可以不要
cookies_dict[cookie['name']] = cookie['value']
key_words = self.settings['KEY_WORDS']
key_words = parse.quote(key_words).replace(' ', '+')
print(key_words)
page_num = self.settings['PAGE_NUM']
one_page_num = self.settings['ONE_PAGE_COUNT']
for i in range(page_num):
url = self.base_url % (key_words, i*one_page_num)
yield scrapy.Request(url, cookies=cookies_dict, callback=self.parse, headers=__class__.headers)
获取数据
一般来说我们都是在parse来获取response里的各种数据的,也有可能会爬取多次,再跳转到详情页内抓取评论parseNext(之后打算继续做),在用parse之前我们要先准备item
class TaobaoSItem(scrapy.Item):
# define the fields for your item here like:
price = scrapy.Field()
sales = scrapy.Field()
title = scrapy.Field()
nick = scrapy.Field()
loc = scrapy.Field()
detail_url = scrapy.Field()
nid = scrapy.Field()
sellerid = scrapy.Field()
定义好item后就写传值逻辑了,我们抓取可以利用xpath定位来拿,也可以用re来定位,而我这里是利用re从js里拿数据
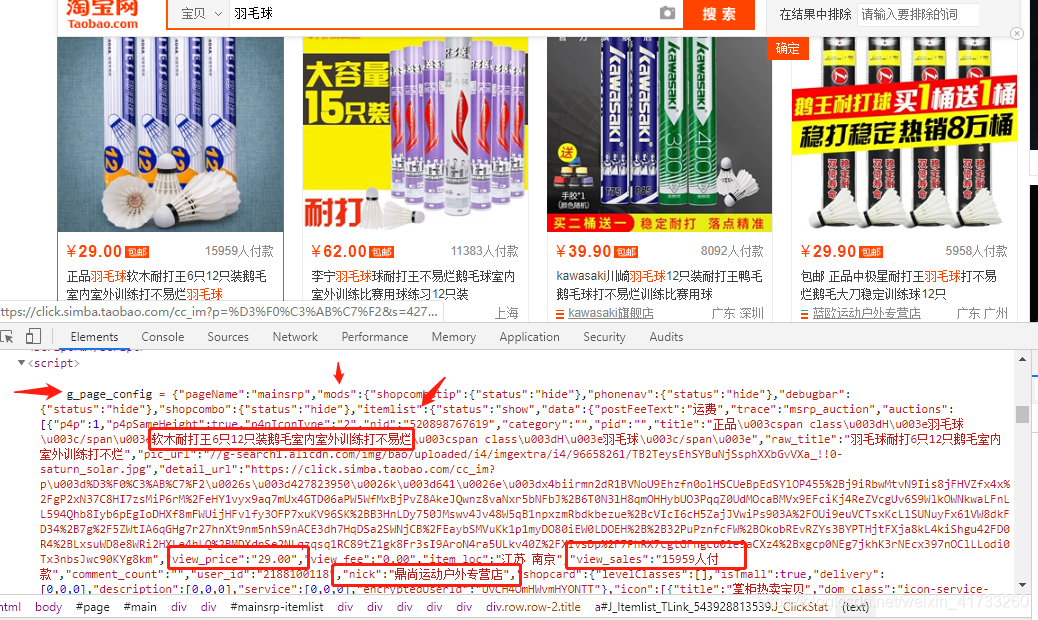
def parse(self, response):
p = 'g_page_config = ({.*?});'
g_page_config = response.selector.re(p)[0]
g_page_config = json.loads(g_page_config)
auctions = g_page_config['mods']['itemlist']['data']['auctions']
url1 = 'https://rate.tmall.com/list_detail_rate.htm?itemId=%s&sellerId=%s&order=3¤tPage=%s'
# 从文件中获取保存的cookies
with open('taobaoCookies.json', 'r', encoding='utf-8') as f:
listcookies = json.loads(f.read()) # 获取cookies
# 把获取的cookies处理成dict类型
cookies_dict = dict()
for cookie in listcookies:
# 在保存成dict时,我们其实只要cookies中的name和value,而domain等其他都可以不要
cookies_dict[cookie['name']] = cookie['value']
for auction in auctions:
item = TaobaoSItem()
item['price'] = auction['view_price']
item['sales'] = auction['view_sales']
item['title'] = auction['raw_title']
item['nick'] = auction['nick']
item['loc'] = auction['item_loc']
item['detail_url'] = auction['detail_url']
item['nid'] = auction['nid']
item['sellerid'] = auction['user_id']
yield item
保存数据
这个凭借个人喜好吧,可以存json、csv或者存入数据库mongodb、redis之类的。但是最好把保存数据的逻辑放在管道Pipelines里,当然我之前那个登陆其实放在中间件里更好
这里我是保存到mongoDB
import pymongo
class TaobaoSPipeline(object):
def open_spider(self,spider):
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
db = client['taobao']
self.q = db['product']
def process_item(self, item, spider):
self.q.update({'nid': item['nid']}, {'$set': dict(item)}, True)
return item
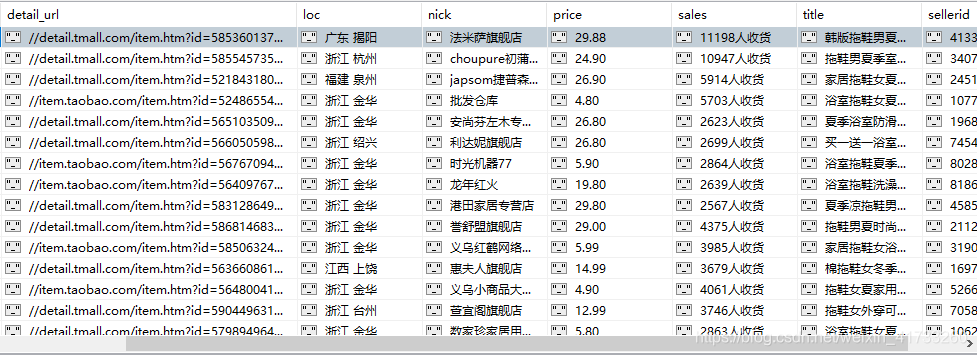
跑一下就可以拿到数据了
项目源码
以上也是我初次用scrapy爬取,以往request+selenium就行了,如果有问题,可以与我交流。