一.归一化的概念
1.概念
特点: 通过对原始数据的变换映射到默认为[0,1]之间
目的:是的某一特征值不会对结果造成更大的影响===》几个特征值对结果影响权重相等的二十号要进行归一化
缺点:异常点(在最大最小值之外)
对异常点的处理不好,鲁棒性较差,只适合传统的小数据场景

2.使用


实例:
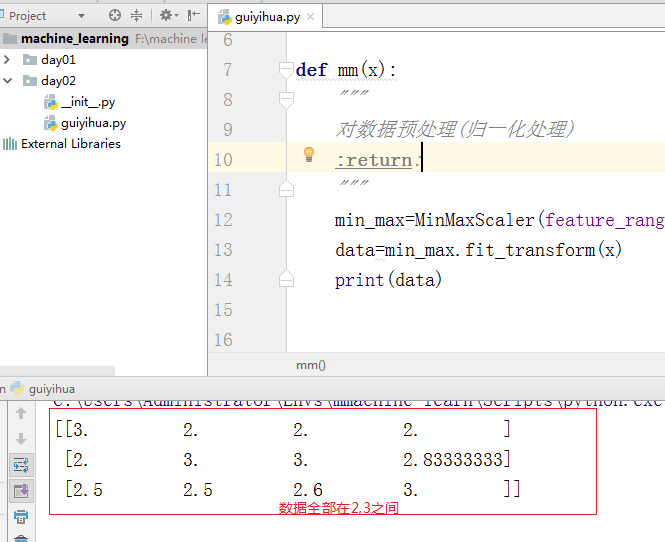
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom #导入归一化处理的包 from sklearn.preprocessing import MinMaxScaler def mm(x): """ 对数据预处理(归一化处理) :return: """ min_max=MinMaxScaler() data=min_max.fit_transform(x) print(data) if __name__ == '__main__': l=[ [90,2,10,40], [60,4,15,45], [75,3,13,46]] mm(l)
结果:

改变归一化范围:
二.标准化
1.标准化的相关知识
特点:方差越小数据越集中,方差越大越分散
在样本足够多的时候稳定,适合现代嘈杂的大数据场景




实例:
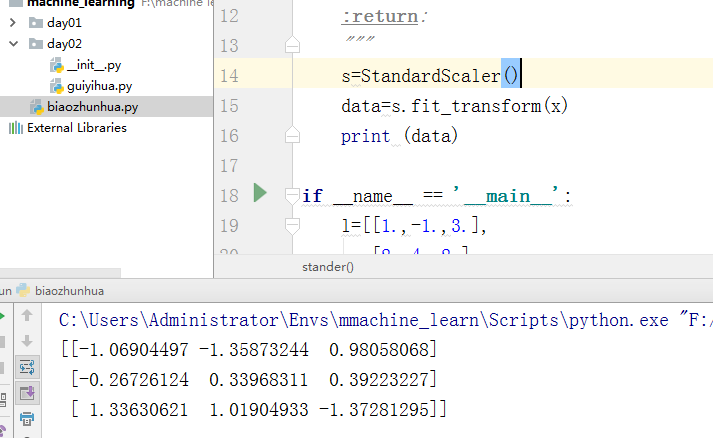
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.preprocessing import StandardScaler def stander(x): """ 标准化缩放 :param x: :return: """ s=StandardScaler() data=s.fit_transform(x) print (data) if __name__ == '__main__': l=[[1.,-1.,3.], [2.,4.,2.], [4.,6.,-1,] ] stander(l)
结果:
3.缺失值处理




实例:
#!/usr/bin/env python # -*- coding: utf-8 -*- #author tom from sklearn.preprocessing import Imputer import numpy as np def im(l): """ 缺失值的处理 :return: """ #NAN nan都可以 用平均值替换 im=Imputer(missing_values='NaN',strategy='mean',axis=0) data=im.fit_transform(l) print(data) if __name__ == '__main__': l=[[1,3], [np.nan,2], [4,6]] im(l)
结果:

注意:缺失值的形式一定是np.nan