VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发的卷积神经网络。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复的使用3x3的小型卷积核和2x2的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络
VGG
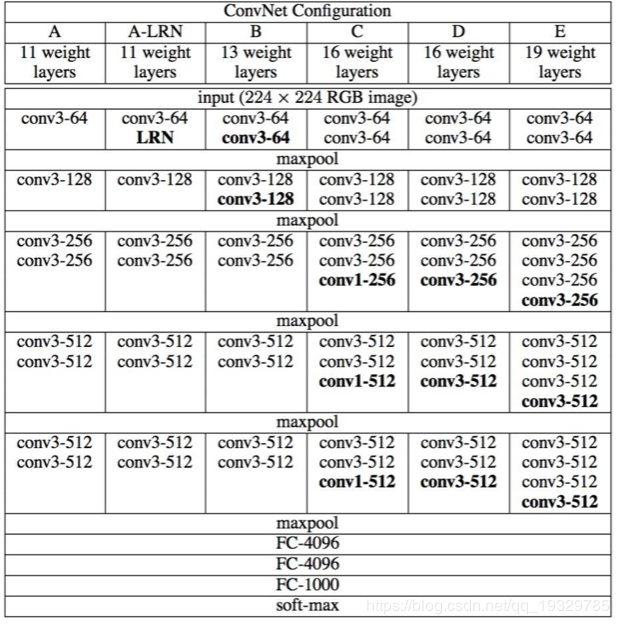
VGG16

VGG19
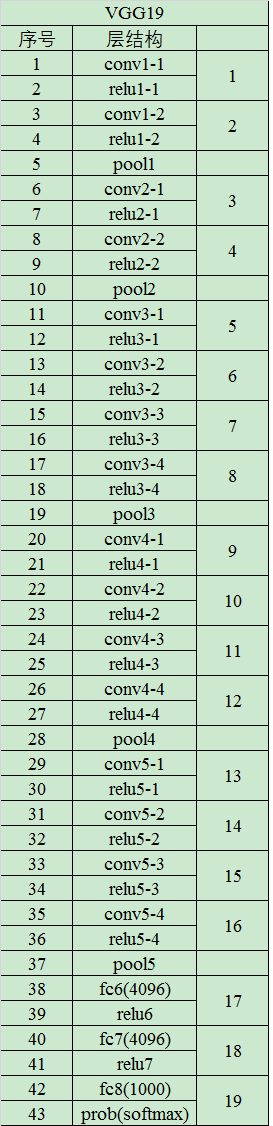
含义:
1.conv表示卷积层
2.FC表示全连接层
3.conv3表示卷积层使用3x3 filters
4.conv3-64表示 64:卷积核的数量
5.maxpool表示最大池化
VGG16包含了16个隐藏层(13个卷积层和3个全连接层),如上图D列所示
VGG19包含了19个隐藏层(16个卷积层和3个全连接层),如上图E列所示
最早的卷积神经网络都是通过比较大的卷积核进行卷积来提取特征的(例如AlexNet,LeNet),虽然卷积核的尺寸越大,越能够总结空间信息。但是同样也增加了参数的数量,提高了计算量。
而VGG网络通过每个block中多个3x3 的卷积核来代替之前的大尺寸卷积核,可以说是非常的nice!
举个例子,用3个3x3的卷积核来卷积得到像素对应的感受野大小与一个7x7卷积核得到的感受野大小是一样的。但是,参数量却是差了近一倍(3x3x3=27,7x7=49)。
、VGG-16网络框架介绍



总结:
-
VGG-16网络中的16代表的含义为:含有参数的有16个层,共包含参数约为1.38亿。
-
VGG-16网络结构很规整,没有那么多的超参数,专注于构建简单的网络,都是几个卷积层后面跟一个可以压缩图像大小的池化层。即:全部使用33的小型卷积核和22的最大池化层。
卷积层:CONV=3*3 filters, s = 1, padding = same convolution。
池化层:MAX_POOL = 2*2 , s = 2。
-
优点:简化了卷积神经网络的结构;缺点:训练的特征数量非常大。
-
随着网络加深,图像的宽度和高度都在以一定的规律不断减小,每次池化后刚好缩小一半,信道数目不断增加一倍。
各模块的讲解
感受野
其实就是指一个像素点和之前的多少个像素有关联。例如下面图示中的3x3卷积操作,Convolved Feature的一个像素点对应的感受野大小就是3x3=9
卷积操作
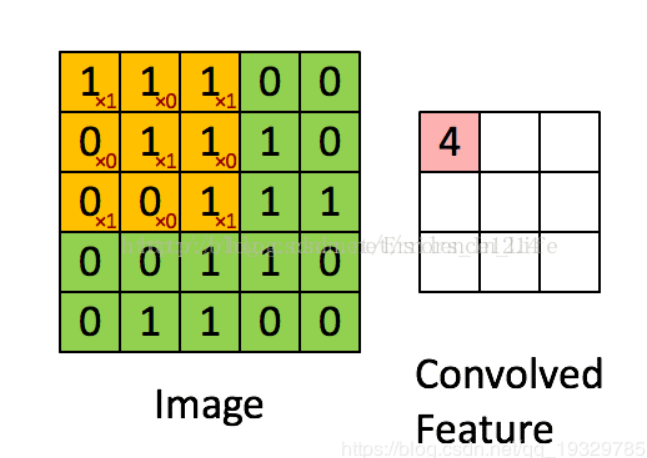
图中用一个简单的动态图很好的表述了3x3卷积的过程。这里主要包含卷积核的尺寸参数,以及卷积核的个数也就是通道数channels【默认strides=1,padding=‘SAME‘】。
这里以VGG16的block1举例,其中包含了两个conv3-64。这里的3代表的就是3x3的卷积核尺寸,而64就代表卷积核的个数,也就是得到的feature map的通道数。
这里也顺便总结一下卷积的好处和一些trick。
参数共享:也就是说一个卷积核对图像进行卷积时,里边的参数是不变的。直观点理解,就是尺度不变性,这就使得网络的容忍能力加强。就好比一个杯子它横放和竖放人都能够将它辨别出来一样。
low/high-level feature map:即低阶/高阶特征。这是随着卷积网络的加深对不同深度的feature map的取名。低阶特征可以理解为颜色、边缘等特征,就好比是一个图片中车的轮廓。
高阶特征可以理解为是更加抽象的特征,相当于更加细化的,比如说车中车轮,以及车轮中的车胎等。而通过卷积网络深度的增加,提取到的最后的高阶特征就是组成元素的基本组成单位:
比如点、线、弧等。而最后的全连接层的目的其实就是进行这些高阶特征的特征组合。
ReLu和BN:即为激活函数层和归一化层。激活函数层的目的就是为了非线性化,得到结果的非线性表达。
而归一化BN层,它能够防止梯度爆炸和梯度弥散,而且对网络的收敛也有好处。Conv+BN+relu基本上都会一起使用。
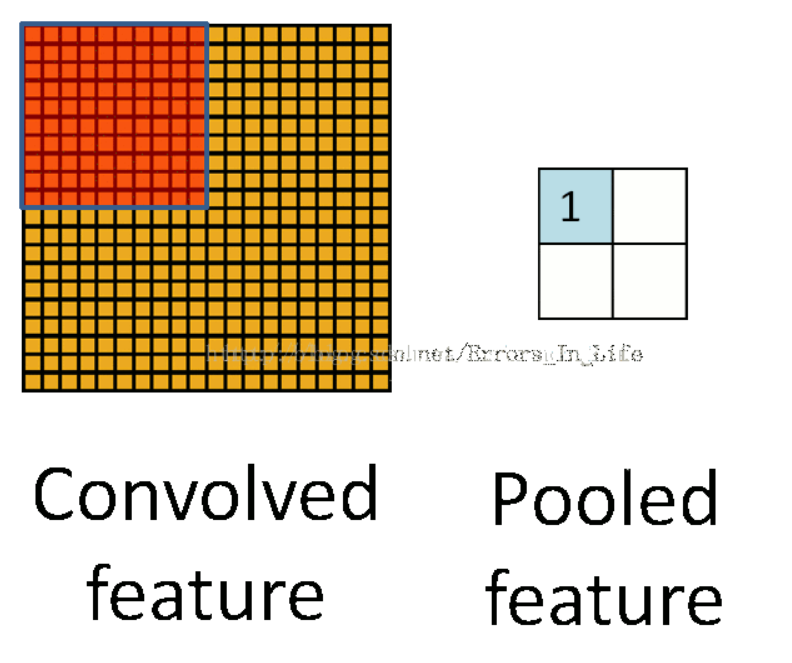
池化操作主要包含最大池化和平均池化:
最大池化:其实就是降低维度,提取图像的主要特征。
平均池化:取一个区域的平均值,用来保留图像的背景信息。
VGGNet的好处真是太多了
1. 图片具有天然的空间结构信息,而卷积操作恰恰就是很好的利用了这种空间结构信息。而且每个block中通过多个Conv的操作,即减少了参数量还保留了同样的感受野。
2. 通过网络结构的加深,网络能够提取更加抽象的高阶特征,这也就是为什么最后提取了512通道的feature map。
3. 说明了随着网络的加深对精度的提升有很大的帮助
4. 缺点:它的参数量太大,耗费了很多的计算资源,这主要是因为最后的三个全连接层。而后也提出了Inception v1、v2、v3版本以及FCN等网络
感受野
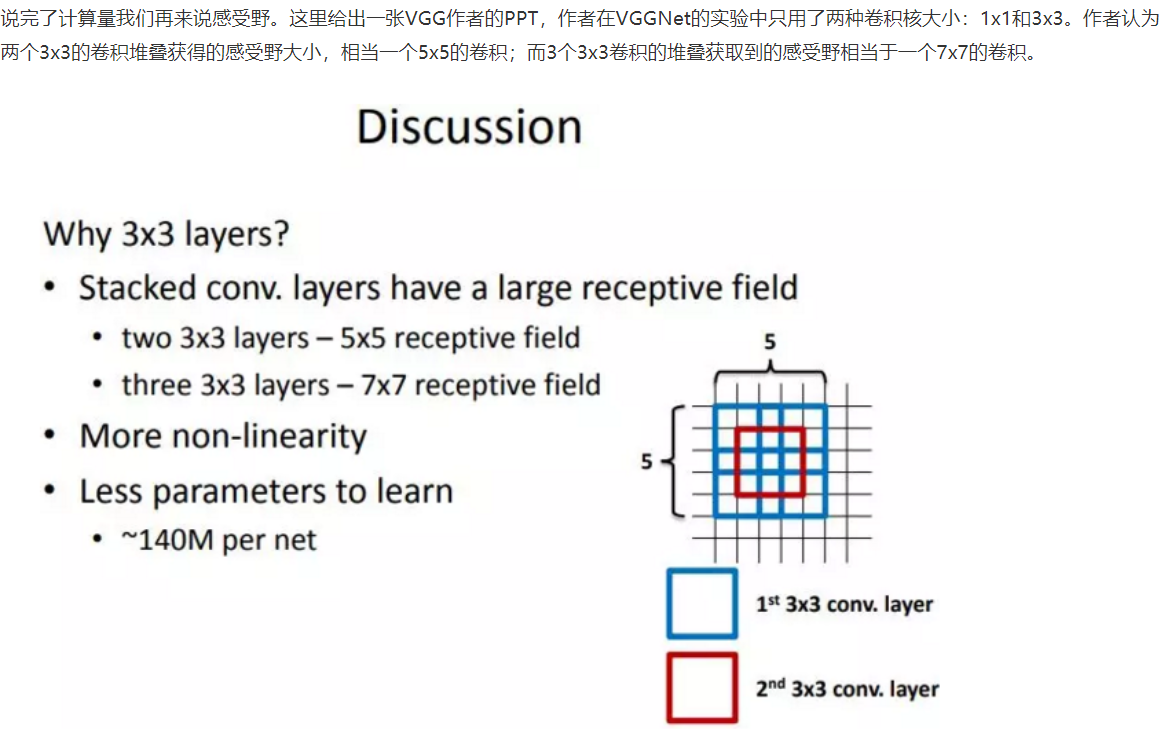
见下图,输入的8个元素可以视为feature map的宽或者高,当输入为8个神经元经过三层conv3x3的卷积得到2个神经元。三个网络分别对应stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷积核在3层、1层、1层时的结果。因为这三个网络的输入都是8,也可看出2个3x3的卷积堆叠获得的感受野大小,相当1层5x5的卷积;而3层的3x3卷积堆叠获取到的感受野相当于一个7x7的卷积。
- input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
- input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果。
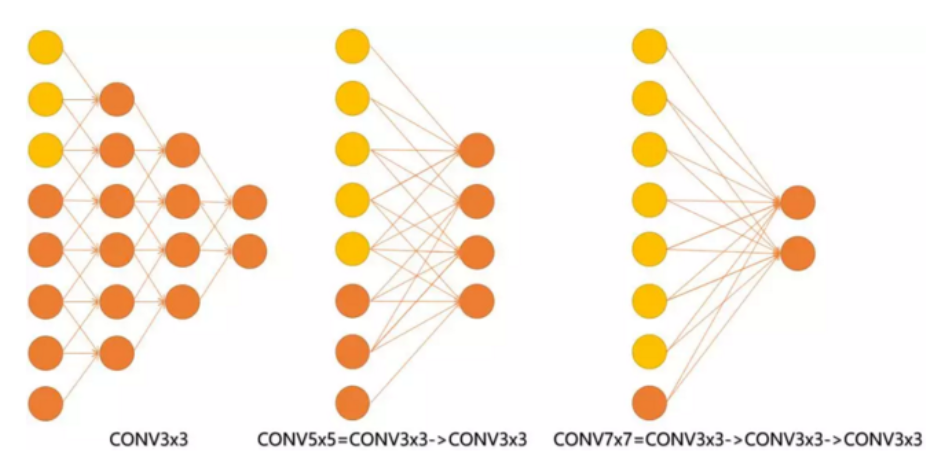
或者我们也可以说,三层的conv3x3的网络,最后两个输出中的一个神经元,可以看到的感受野相当于上一层是3,上上一层是5,上上上一层(也就是输入)是7。
此外,倒着看网络,也就是backprop的过程,每个神经元相对于前一层甚至输入层的感受野大小也就意味着参数更新会影响到的神经元数目。
在分割问题中卷积核的大小对结果有一定的影响,在上图三层的conv3x3中,最后一个神经元的计算是基于第一层输入的7个神经元,
换句话说,反向传播时,该层会影响到第一层conv3x3的前7个参数。从输出层往回forward同样的层数时,大卷积影响(做参数更新时)到的前面的输入神经元越多
优点
既然说到了VGG清一色用小卷积核,这里整理出小卷积核比用大卷积核的三点优势:
-
更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,更多的卷积核的使用可使决策函数更加具有辨别能力,此外就卷积本身的作用而言,3x3比7x7就足以捕获特征的变化:3x3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化。主要在于3个堆叠起来后,三个3x3近似一个7x7,网络深了两层且多出了两个非线性ReLU函数,(特征多样性和参数参数量的增大)使得网络容量更大(关于model capacity,AlexNet的作者认为可以用模型的深度和宽度来控制capacity),对于不同类别的区分能力更强(此外,从模型压缩角度也是要摒弃7x7,用更少的参数获得更深更宽的网络,也一定程度代表着模型容量,后人也认为更深更宽比矮胖的网络好);
-
卷积层的参数减少。相比5x5、7x7和11x11的大卷积核,3x3明显地减少了参数量,这点可以回过头去看上面的表格。比方input channel数和output channel数均为C,那么3层conv3x3卷积所需要的卷积层参数是:3x(Cx3x3xC)=27C^2,而一层conv7x7卷积所需要的卷积层参数是:Cx7x7xC=49C^2。conv7x7的卷积核参数比conv3x3多了(49-27)/27x100% ≈ 81%;
- 小卷积核代替大卷积核的正则作用带来性能提升。作者用三个conv3x3代替一个conv7x7,认为可以进一步分解(decomposition)原本用7x7大卷积核提到的特征,这里的分解是相对于同样大小的感受野来说的。关于正则的理解我觉得还需要进一步分析。
其实最重要的还是多个小卷积堆叠在分类精度上比单个大卷积要好。
卷积层参数个数
- 卷积核的个数=最终的featuremap的个数
- 卷积核的大小=开始进行卷积的通道数×每个通道上进行卷积的二维卷积核的尺寸
-
参数的个数=卷积核个数×(卷积核大小+1)