一、背景:
HashMap到底是怎么实现的?
一对一对的存放,通过key找value;map的键不能重复;自己怎么实现呢?
代码:
Wife.java 辅助类


package com.cy.collection; public class Wife { String name; public Wife(String name){ this.name = name; } @Override public String toString() { return "Wife [name=" + name + "]"; } }
Map.java:
package com.cy.collection; /** * 自定义实现Map */ public class Map { private Entry[] arr = new Entry[1000]; //这里暂时不考虑扩容 private int size; //这里都是private的,不暴露size属性 /** * 1.键不能重复,如果含有这个键,就替换value * @param key * @param value */ public void put(Object key, Object value){ for(int i=0; i<size; i++){ if(arr[i].key.equals(key)){ arr[i].value = value; return; } } arr[size++] = new Entry(key, value); } //根据key获取 public Object get(Object key){ for(int i=0; i<size; i++){ if(arr[i].key.equals(key)){ return arr[i].value; } } return null; } //根据key删除 public boolean remove(Object key){ boolean success = false; for(int i=0;i<size;i++){ if(arr[i].key.equals(key)){ success = true; remove(i); } } return success; } private void remove(int i){ int numMoved = size - i - 1; if(numMoved>0){ System.arraycopy(arr, i+1, arr, i, numMoved); } arr[--size] = null; //Let gc do its work } //containsKey public boolean containsKey(Object key){ for(int i=0; i<size; i++){ if(arr[i].key.equals(key)){ return true; } } return false; } //containsValue 同containsKey //size public int size(){ return size; } } /** * 用来存放键值对的条目 */ class Entry{ Object key; Object value; public Entry(Object key, Object value) { super(); this.key = key; this.value = value; } }
Test.java测试代码:
package com.cy.collection; public class Test { public static void main(String[] args) { Map map = new Map(); map.put("张三", new Wife("abc")); map.put("李四", new Wife("def")); map.put("王五", new Wife("ghi")); System.out.println(map.get("张三")); map.remove("李四"); System.out.println(map.size()); map.put("张三", new Wife("aaa")); System.out.println(map.get("张三")); System.out.println(map.containsKey("张三")); } } 输出: Wife [name=abc] 2 Wife [name=aaa] true
虽然说实现了,但是上面Map不完美的地方:
1.每次get(key)都要遍历数组一次,效率很低;
有没有什么办法可以让查询的效率高起来?
二、map改进,哈希算法实现,使用数组和链表
能不能通过什么方法来提高查询效率?避免像上面的map一样循环遍历?能不能有好的办法一下子就命中目标。
思路:
1)假如arr数组是无穷大的,现在要将一个key放进数组,先计算key.hashCode(),将hashCode值就放在arr数组的这个对应下标的位置,
即arr[key.hashCode]这个位置,这个位置就存放Entry(key,value)。下次再要查找get(key)的时候,计算key的hashCode值,然后从数组中
找到arr[key.hashCode]不就快速定位,拿出来了吗?
2)但是,数组不是无穷大的,现在能不能将key的hashCode进行转化,转化成一个合理的数,比如arr[1000],数组的下标就是0~1000,能不能将hashCode
转化为0~1000的一个数,这样就可以放到对应下标值的位置上啦。
3)怎么转换?hashCode%1000,来取余数,余数的范围就是0-999,要放的键值对就放在arr[余数];
但是余数极大可能会重复,怎么办?
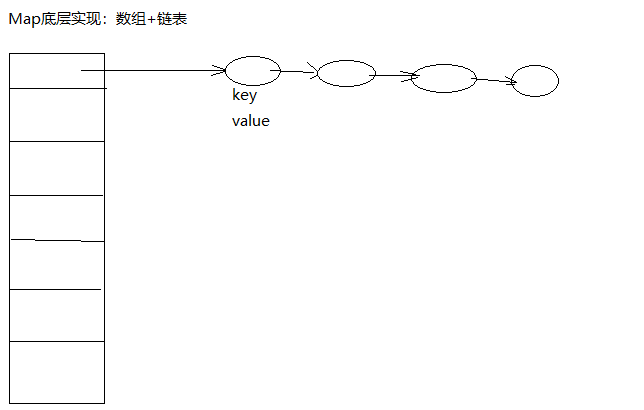
4)Map的底层实现是数组+链表,现在数组里面不存放Entry对象,而是存放链表,如果余数相同,就在链表的后面继续添加;
get(key)的时候,就在这个数组的位置arr(key.hashCode)上,查找这个链表,在遍历;
图示:
代码:
Map.java:
package com.cy.collection; import java.util.LinkedList; /** * 自定义实现Map升级版 * 1.提高查询的效率 */ public class Map { private LinkedList[] arr = new LinkedList[1000]; //Map的底层结构就是:数组+链表 private int size; /** * 1.键不能重复,如果含有这个键,就替换value */ public void put(Object key, Object value){ Entry e = new Entry(key, value);
int hash = key.hashCode();
hash = hash<0?-hash:hash;
int a = hash % arr.length; if(arr[a]==null){ LinkedList list = new LinkedList(); arr[a] = list; list.add(e); }else{ LinkedList list = arr[a]; for(int i=0; i<list.size(); i++){ Entry en = (Entry) list.get(i); if(en.key.equals(key)){ en.value = value; //键值重复,覆盖value return; } } list.add(e); } size++; } //根据key获取值 public Object get(Object key){ int a = key.hashCode() % arr.length; if(arr[a]!=null){ LinkedList list = arr[a]; for(int i=0; i<list.size(); i++){ Entry e = (Entry) list.get(i); if(e.key.equals(key)){ return e.value; } } } return null; } //size public int size(){ return size; } } /** * 用来存放键值对的条目 */ class Entry{ Object key; Object value; public Entry(Object key, Object value) { super(); this.key = key; this.value = value; } }
Test.java
package com.cy.collection; public class Test { public static void main(String[] args) { Map map = new Map(); map.put("张三", new Wife("abc")); map.put("李四", new Wife("def")); map.put("张三", new Wife("ghi")); System.out.println(map.get("张三")); System.out.println(map.size()); } } 输出: Wife [name=ghi] 2
三、小结
1.哈希算法的本质:通过这个算法,可以快速的定位元素在数组中的存储位置;
2.从上面代码可以看到,如果两个obj互相equals了,那么他们的hashCode必然相等。
3.Object类的hashCode方法为:public native int hashCode();没有实现,native表示本地的,调用本地的一些资源,和操作系统相关的,hashCode默认的实现是根据内存地址进行计算的,native,跟操作系统相关的一种本地方法;