概念
-
监督学习(Supervised Learning)
- 从给定标注的训练数据集中学习出一个函数,根据这个函数为新函数进行标注
-
无监督学习(Unsupervised Learning)
- 从给定无标注的训练数据中学习出一个函数,根据这个函数为所有数据标注
-
分类(Classification)
分类算法通过对已知类别训练数据集的分析,从中发现分类规则,以此预测新数据的类别,分类算法属于监督学习
KNN(K Nearest Neighbors)
K近邻分类算法:KNN算法从训练集中找到和新数据最接近的K条记录,然后根据他们的主要分类来决定新数据的类别
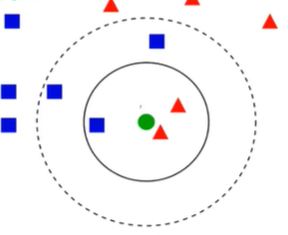
交叉验证法(Cross Validation)
训练集(Train Set):用来训练模型或确定模型的数据
测试集(Test Set):用来验证模型的准确性的数据

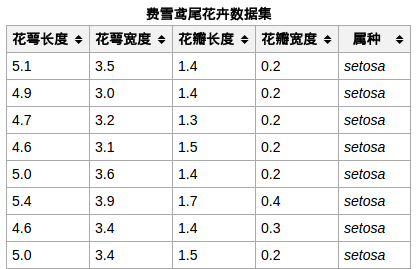
iris数据集
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label)。
--------------------- 来自 善战骁勇 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/java1573/article/details/78865495?utm_source=copy
步骤
1、导入iris数据集
numpy、sklearn中的datasets类
导入iris数据集可以通过sklearn自带的方法导入iris数据集,前面有iris数据集的相关介绍
import numpy from sklearn import datasets #导入iris数据集 iris=datasets.load_iris() iris #查看数据的规模 iris.data.shape #查看训练目标的总类 numpy.unique(iris.target)#去重数组
train_test_split是交叉验证中常用的函数,功能是从从样本中随机按比例选取train data和test data,形式为:data_train,data_test,target_train,target_test=train_test_split(iris.data,iris.taget,test_size=0.3,random_state=0)
- iris.data为特征数据;
- iris.target为目标数据;
- test_size为测试的占比,一般使用三七分,训练集占0.7;
- random_state:是随机数的种子
1 from sklearn.model_selection import train_test_split 2 3 data_train, data_test, target_train, target_test=train_test_split( 4 iris.data, #特征数据 5 iris.target, #目标数据 6 test_size=0.3 #测试的占比,一般使用三七分,训练集占0.7 7 ) 8 9 10 data_train.shape 11 data_test.shape 12 target_train.shape 13 target_test.shape
2、使用KNN的建模类neighbors.KNeighborsClassifier()
1 from sklearn import neighbors 2 3 knnModel=neighbors.KNeighborsClassifier(n_neighbors=3) #分类的个数,可以从数据集中获取 4 5 knnModel.fit(data_train,target_train) 6 7 knnModel.score(data_test,target_test)
3、使用cross_val_score类、预测
1 from sklearn.model_selection import cross_val_score 2 3 cross_val_score( 4 knnModel, 5 iris.data,iris.target,cv=5 #cv为k折交叉验证的K值 6 ) #返回五次验证 7 8 #使用模型进行预测 9 knnModel.predict([[0.1,0.2,0.3,0.4]])
KNeighborsClassifier在sklearn.neighbors包之中。
KNeighborsClassifier使用很简单,
1)创建KNeighborsClassifier对象;
2)调用fit函数;
3)调用predict函数进行预测。以下代码说明了用法。