把数据存取逻辑、业务逻辑和表现逻辑组合在一起的概念有时被称为软件架构的 Model-View-Controller (MVC)模式。在这个模式中, Model 代表数据存取层,View 代表的是系统中选择显示什么和怎么显示的部分,Controller 指的是系统中根据用户输入并视需要访问模型,以决定使用哪个视图的那部分。
由于 C 由框架自行处理,而 Django 里更关注的是模型(Model)、模板(Template)和视图(Views),Django 也被称为 MTV 框架 。在 MTV 开发模式中:
M 代表模型(Model),即数据存取层。该层处理与数据相关的所有事务:如何存取、如何确认有效性、包含哪些行为以及数据之间的关系等。
T 代表模板(Template),即表现层。该层处理与表现相关的决定:如何在页面或其他类型文档中进行显示。
V代表View,业务逻辑层。这一层包含访问模型的逻辑和按照模板显示。你可以认为它是模型和模板的桥梁。
数据库配置
修改配置文件 settings.py
DATABASE_ENGINE = '' DATABASE_NAME = '' DATABASE_USER = '' DATABASE_PASSWORD = '' DATABASE_HOST = '' DATABASE_PORT = ''
mysql多实例可以指定用户
DATABASE_HOST = '/data/3306/mysql.sock'
高版本的Django连接数据库配置有所不同,参考原版文档:
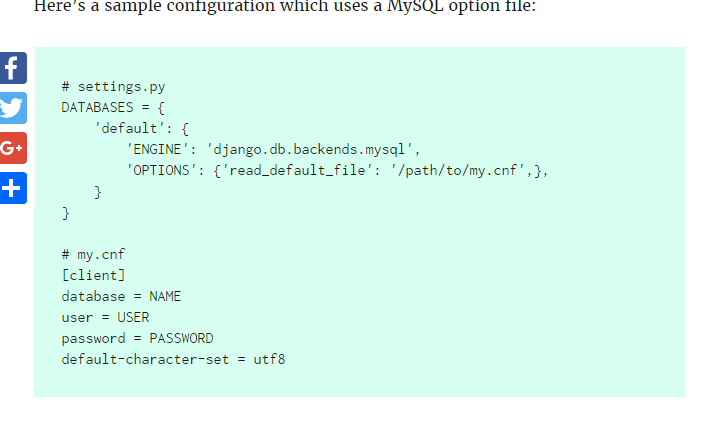
如果你只是建造一个简单的web站点,那么可能你只需要一个app就可以了。如果是复杂的象 电子商务之类的Web站点,你可能需要把这些功能划分成不同的app,以便以后重用。
系统对app有一个约定:如果你使用了Django的数据库层(模型),你 必须创建一个django app。模型必须在这个app中存在。因此,为了开始建造 我们的模型,我们必须创建一个新的app。
转到 mysite 项目目录,执行下面的命令来创建一个新app叫做books:
python manage.py startapp books
在 mysite 目录下创建了一个 books 的文件夹
books/
__init__.py
models.py
views.py
创建你的第一个模型
在Django中使用该数据库布局的第一步是将其表述为Python代码。在通过“startapp”命令创建的“models.py”文件中,输入如下代码:
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
class Author(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=40)
email = models.EmailField()
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
每个模型相当于单个数据库表,每个属性也是这个表中的一个字段。 属性名就是字段名,它的类型(例如 CharField )相当于数据库的字段类型 (例如 varchar )。例如, Publisher 模块等同于下面这张表(用PostgreSQL的 CREATE TABLE 语法描述):
CREATE TABLE "books_publisher" ( "id" serial NOT NULL PRIMARY KEY, "name" varchar(30) NOT NULL, "address" varchar(50) NOT NULL, "city" varchar(60) NOT NULL, "state_province" varchar(30) NOT NULL, "country" varchar(50) NOT NULL, "website" varchar(200) NOT NULL );
其中:
SERIAL是BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE的一个别名。
在整数列定义中,SERIAL DEFAULT VALUE是NOT NULL AUTO_INCREMENT UNIQUE的一个别名。
注:上面NOT NULL是不可为空,AUTO_INCREMENT是递增,指定起始值为1用AUTO_INCREMENT=1语句,不指定默认也为1。
UNIQE是不可重复的意思,取值不能与已经存在的数据重复。
“每个数据库表对应一个类”这条规则的例外情况是多对多关系。 在我们的范例模型中, Book 有一个 多对多字段 叫做 authors 。 该字段表明一本书籍有一个或多个作者,但 Book 数据库表却并没有 authors 字段。 相反,Django创建了一个额外的表(多对多连接表)来处理书籍和作者之间的映射关系。
模型安装
完成这些代码之后,现在让我们来在数据库中创建这些表。要完成该项工作,第一步是在 Django 项目中 激活 这些模型。将 books app 添加到配置文件的已 installed apps 列表中即可完成此步骤。
再次编辑 settings.py 文件, 找到 INSTALLED_APPS 设置。 INSTALLED_APPS 告诉 Django 项目哪些 app 处于激活状态。缺省情况下如下所示:
MIDDLEWARE_CLASSES = (
# 'django.middleware.common.CommonMiddleware',
# 'django.contrib.sessions.middleware.SessionMiddleware',
# 'django.contrib.auth.middleware.AuthenticationMiddleware',
# 'django.middleware.doc.XViewMiddleware',
)
TEMPLATE_CONTEXT_PROCESSORS = ()
#...
INSTALLED_APPS = (
#'django.contrib.auth',
#'django.contrib.contenttypes',
#'django.contrib.sessions',
#'django.contrib.sites',
'mysite.books',
)
现在我们可以创建数据库表了。首先,用下面的命令对校验模型的有效性:
python manage.py validate
检查试会报错:
TypeError: __init__() got an unexpected keyword argument ‘maxlength’
应该是以前的版本是应该用maxlength,但是新版本里面使用max_length
在vim中替换 :%s/maxlength/max_length/g
然后再次报错:
Error: One or more models did not validate:
books.author: "headshot": To use ImageFields, you need to install the Python Imaging Library. Get it at http://www.pythonware.com/products/pil/ .
那就开始安装这个库:
pip install PIL
DEPRECATION: Python 2.6 is no longer supported by the Python core team, please upgrade your Python. A future version of pip will drop support for Python 2.6
Collecting PIL
Could not find a version that satisfies the requirement PIL (from versions: )
No matching distribution found for PIL
只能升级python了
升级到了2.7版本,还是报错,干脆升级到3.X看看情况:使用souhu的源还是比较快
wget http://mirrors.sohu.com/python/3.3.3/Python-3.3.3.tar.bz2
在编译前先在/usr/local建一个文件夹python3.3 .3(作为Python的安装路径,以免覆盖老的版本)
mkdir -p /usr/local/python-3.3.3
在解压缩后的目录下编译安装
./configure --prefix=/usr/local/python-3.3.3
make && make install
将原来/usr/bin/python链接改为别的名字
mv /usr/bin/python /usr/bin/python_old
再建立新版本python的链接
ln -s /usr/local/python3.3.3/bin/python3 /usr/bin/python
安装好之后,需要重新安装setuptools , pip ,MySQLdb, Django
但是经历了好多,发现对这些的支持都有问题,索性,换一个方法来做:
还是用系统自带的python2.6.6 , 其他的插件,不用pip来安装,直接下载先来自己安装
Imaging-1.1.7
python setup.py install 然后就搞定了
继续问题前的操作
python manage.py validate
看到 0 errors found 消息,一切正常。继续:
运行下面的命令来生成 CREATE TABLE 语句:
python manage.py sqlall books
BEGIN; CREATE TABLE `books_publisher` ( `id` integer AUTO_INCREMENT NOT NULL PRIMARY KEY, `name` varchar(30) NOT NULL, `address` varchar(50) NOT NULL, `city` varchar(60) NOT NULL, `state_province` varchar(30) NOT NULL, `country` varchar(50) NOT NULL, `website` varchar(200) NOT NULL ) ; CREATE TABLE `books_author` ( `id` integer AUTO_INCREMENT NOT NULL PRIMARY KEY, `salutation` varchar(10) NOT NULL, `first_name` varchar(30) NOT NULL, `last_name` varchar(40) NOT NULL, `email` varchar(75) NOT NULL, `headshot` varchar(100) NOT NULL ) ; CREATE TABLE `books_book` ( `id` integer AUTO_INCREMENT NOT NULL PRIMARY KEY, `title` varchar(100) NOT NULL, `publisher_id` integer NOT NULL, `publication_date` date NOT NULL ) ; ALTER TABLE `books_book` ADD CONSTRAINT `publisher_id_refs_id_4cdc253fc5b274bb` FOREIGN KEY (`publisher_id`) REFERENCES `books_publisher` (`id`); CREATE TABLE `books_book_authors` ( `id` integer AUTO_INCREMENT NOT NULL PRIMARY KEY, `book_id` integer NOT NULL, `author_id` integer NOT NULL, UNIQUE (`book_id`, `author_id`) ) ; ALTER TABLE `books_book_authors` ADD CONSTRAINT `book_id_refs_id_5565ddfcfbcf262` FOREIGN KEY (`book_id`) REFERENCES `books_book` (`id`); ALTER TABLE `books_book_authors` ADD CONSTRAINT `author_id_refs_id_1f0e145e09e7e386` FOREIGN KEY (`author_id`) REFERENCES `books_author` (`id`); CREATE INDEX `books_book_publisher_id` ON `books_book` (`publisher_id`); COMMIT;
sqlall 命令并没有在数据库中真正创建数据表,只是把SQL语句段打印出来。运行 syncdb 命令
python manage.py syncdb
Creating table books_publisher Creating table books_book Creating table books_author Installing index for books.Book model
成功创建了表
基本数据访问
添加一个方法 __unicode__() 到 Publisher 对象。 __unicode__() 方法告诉Python要怎样把对象unicode的方式显示出来.
普通的python字符串是经过编码的,意思就是它们使用了某种编码方式(如ASCII,ISO-8859-1或者UTF-8)来编码。
但是Unicode对象并没有编码。它们使用Unicode,一个一致的,通用的字符编码集。 当你在Python中处理Unicode对象的时候,你可以直接将它们混合使用和互相匹配而不必去考虑编码细节。
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
**def __unicode__(self):**
**return self.name**
class Author(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=40)
email = models.EmailField()
**def __unicode__(self):**
**return u'%s %s' % (self.first_name, self.last_name)**
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
**def __unicode__(self):**
**return self.title**
>>> from books.models import Publisher >>> p1 = Publisher(name='Addison-Wesley', address='75 Arlington Street', ... city='Boston', state_province='MA', country='U.S.A.', ... website='http://www.apress.com/') >>> p1.save() >>> p2 = Publisher(name="O'Reilly", address='10 Fawcett St.', ... city='Cambridge', state_province='MA', country='U.S.A.', ... website='http://www.oreilly.com/') >>> p2.save() >>> publisher_list = Publisher.objects.all() >>> publisher_list
[<Publisher: Addison-Wesley>, <Publisher: O'Reilly>]
所有的数据库查找都遵循一个通用模式:调用模型的管理器来查找数据。
数据过滤
如果想要获得数据的一个子集,我们可以使用 filter() 方法:SQL缺省的 = 操作符是精确匹配的
Publisher.objects.filter(country="U.S.A.", state_province="CA")
这个 __contains 部分会被Django转换成 LIKE SQL语句
Publisher.objects.filter(name__contains="press")
等同于:
SELECT id, name, address, city, state_province, country, website FROM book_publisher WHERE name LIKE '%press%';
获取单个对象
使用 get() 方法:
Publisher.objects.get(name="Apress Publishing")
数据排序
用 order_by() 来 排列返回的数据:
Publisher.objects.order_by("name")
还可以指定逆向排序,在前面加一个减号 - 前缀:
Publisher.objects.order_by("-name")
每次都要用 order_by() 显得有点啰嗦。 大多数时间你通常只会对某些 字段进行排序。在这种情况下,Django让你可以指定模型的缺省排序方式:
class Publisher(models.Model): name = models.CharField(maxlength=30) address = models.CharField(maxlength=50) city = models.CharField(maxlength=60) state_province = models.CharField(maxlength=30) country = models.CharField(maxlength=50) website = models.URLField() def __str__(self): return self.name class Meta: ordering = ["name"]
这个 ordering = ["name"] 告诉Django如果没有显示提供 order_by() , 就缺省按名称排序。
可以同时做这 过滤和排序
Publisher.objects.filter(country="U.S.A.").order_by("-name")
限制返回的数据
只想显示第一个
Publisher.objects.all()[0]
删除对象
调用对象的 delete() 方法:
p = Publisher.objects.get(name="Addison-Wesley") p.delete()
后边的数据库操作比较繁琐,就等用的时候再学习更新吧
一个project包含很多个Django app以及对它们的配置。
技术上,project的作用是提供配置文件,比方说哪里定义数据库连接信息, 安装的app列表, TEMPLATE_DIRS,等等。
一个app是一套Django功能的集合,通常包括模型和视图,按Python的包结构的方式存在。
例如,Django本身内建有一些app,例如注释系统和自动管理界面。 app的一个关键点是它们是很容易移植到其他project和被多个project复用。