前言
1、目的
- 了解javaSPI实现原理;
- 了解Spring-boot实现原理;
- 会使用两者;
2、搜索关键词
- JDK和Spring中SPI的实现原理和区别
- JDK和Spring中SPI的实现原理和区别
一、javaSPI
1.1简介
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的API,它可以用来启用框架扩展和替换组件。
底层通过反射实现。
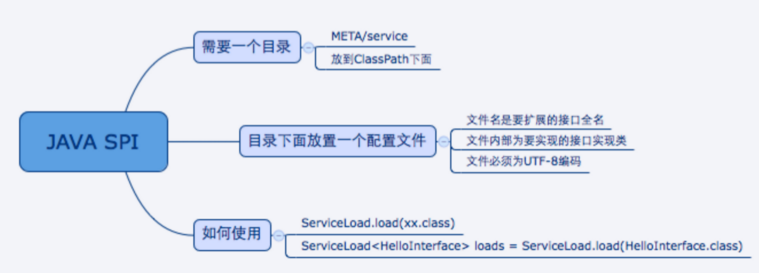
1.2实现原理
我们使用的时候都是使用的ServiceLoader加载服务,下面来看下ServiceLoader是具体怎么实现的
ServiceLoader是JDK提供的一个util,在java.uyil包下
我们可以看到他的介绍A simple service-provider loading facility.用来加载服务的
public final class ServiceLoader<S> implements Iterable<S>
我们可以看到他是一个final类型的,不可以被继承修改,同时实现了Iterable接口,方便我们使用迭代器取出所有的实现类
接下来我们可以看到一个熟悉的常量,这个就是我们在前面定义实现类的路径
private static final String PREFIX = "META-INF/services/";
下面便是load方法的具体实现
public static <S> ServiceLoader<S> load(Class<S> service) { ClassLoader cl = Thread.currentThread().getContextClassLoader(); return ServiceLoader.load(service, cl); } public static <S> ServiceLoader<S> load(Class<S> service, ClassLoader loader) { return new ServiceLoader<>(service, loader); } private ServiceLoader(Class<S> svc, ClassLoader cl) { service = Objects.requireNonNull(svc, "Service interface cannot be null"); loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl; acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null; reload(); } public void reload() { providers.clear(); lookupIterator = new LazyIterator(service, loader); }
上面的代码我是根据调用顺序贴出来的,方便阅读
通过跟踪代码发现,在reload方法中具体是通过一个内部类LazyIterator实现的。接下来我们去看LazyIterator的构造方法传入 Class 和ClassLoader。
下面是ServiceLoader的iterator方法实现,这边会去new一个Iterator,首先在ServiceLoader中有一个provider的缓存,每次操作的时候都会先去缓存中查找,否则采取LazyIterator中去查找。
public Iterator<S> iterator() { return new Iterator<S>() { Iterator<Map.Entry<String,S>> knownProviders = providers.entrySet().iterator(); public boolean hasNext() { if (knownProviders.hasNext()) return true; return lookupIterator.hasNext(); } public S next() { if (knownProviders.hasNext()) return knownProviders.next().getValue(); return lookupIterator.next(); } public void remove() { throw new UnsupportedOperationException(); } }; }
下面是LazyIterator的具体处理
public boolean hasNext() { if (acc == null) { return hasNextService(); } else { PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() { public Boolean run() { return hasNextService(); } }; return AccessController.doPrivileged(action, acc); } } private boolean hasNextService() { if (nextName != null) { return true; } if (configs == null) { try { //通过PREFIX(META-INF/services/)和类名 获取对应的配置文件,得到具体的实现类 String fullName = PREFIX + service.getName(); if (loader == null) configs = ClassLoader.getSystemResources(fullName); else configs = loader.getResources(fullName); } catch (IOException x) { fail(service, "Error locating configuration files", x); } } while ((pending == null) || !pending.hasNext()) { if (!configs.hasMoreElements()) { return false; } pending = parse(service, configs.nextElement()); } nextName = pending.next(); return true; } public S next() { if (acc == null) { return nextService(); } else { PrivilegedAction<S> action = new PrivilegedAction<S>() { public S run() { return nextService(); } }; return AccessController.doPrivileged(action, acc); } } private S nextService() { if (!hasNextService()) throw new NoSuchElementException(); String cn = nextName; nextName = null; Class<?> c = null; try { c = Class.forName(cn, false, loader); } catch (ClassNotFoundException x) { fail(service, "Provider " + cn + " not found"); } if (!service.isAssignableFrom(c)) { fail(service, "Provider " + cn + " not a subtype"); } try { S p = service.cast(c.newInstance()); providers.put(cn, p); return p; } catch (Throwable x) { fail(service, "Provider " + cn + " could not be instantiated", x); } throw new Error(); // This cannot happen }
1.3总结
通过上面的代码学习,发现其实它根本还是通过反射的方式获取具体的实现类的实例,我们只是通过SPI定义的方式,将要暴露对外使用的具体实现在META-INF/services/文件下声明而已。所以对于反射的掌握还是很重要的,无论是spring还是其他的一些框架中经常可以看到反射的使用
1.4在现有框架中的使用
其实了解SPI机制是因为最近看SpringBoot代码的时候发现的,我们知道在SprngBoot中好多的配置和实现都有默认的实现,我们只需要修改部分配置,比如数据库配置,我们只要在配置文件中写上对应的url,username,password就可以使用了。其实他这边用的就是SPI的方式实现的
不过Spring使用的只是和JDK中的原理相同而已。
- JDK使用的工具类是ServiceLoader
- Spring中使用的类是SpringFactoriesLoader,在org.springframework.core.io.support包中
区别:
- 文件路径不同 spring配置放在 META-INF/spring.factories中
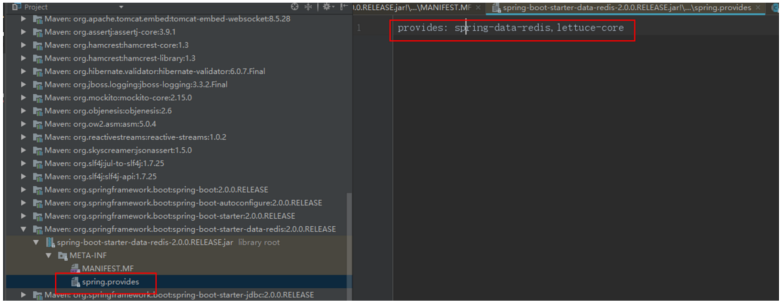
- 具体的实现步骤不一样,不过原理相同,都是使用的反射机制
Spring中实现
public static <T> List<T> loadFactories(Class<T> factoryClass, @Nullable ClassLoader classLoader) { Assert.notNull(factoryClass, "'factoryClass' must not be null"); ClassLoader classLoaderToUse = classLoader; if (classLoaderToUse == null) { classLoaderToUse = SpringFactoriesLoader.class.getClassLoader(); } List<String> factoryNames = loadFactoryNames(factoryClass, classLoaderToUse); if (logger.isTraceEnabled()) { logger.trace("Loaded [" + factoryClass.getName() + "] names: " + factoryNames); } List<T> result = new ArrayList<>(factoryNames.size()); for (String factoryName : factoryNames) { result.add(instantiateFactory(factoryName, factoryClass, classLoaderToUse)); } AnnotationAwareOrderComparator.sort(result); return result; }
1.5java类加载机制相关
类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个这个类的Java.lang.Class对象,用来封装类在方法区类的对象。java中的类加载器负载加载来自文件系统、网络或者其他来源的类文件。jvm的类加载器默认使用的是双亲委派模式。三种默认的类加载器Bootstrap ClassLoader、Extension ClassLoader和System ClassLoader(Application ClassLoader)每一个中类加载器都确定了从哪一些位置加载文件。于此同时我们也可以通过继承java.lang.classloader实现自己的类加载器。
Bootstrap ClassLoader:负责加载JDK自带的rt.jar包中的类文件,是所有类加载的父类。
Extension ClassLoader:负责加载java的扩展类库从jre/lib/ect目录或者java.ext.dirs系统属性指定的目录下加载类,是System ClassLoader的父类加载器。
System ClassLoader(APP ClassLoader):负责从classpath环境变量中加载类文件。
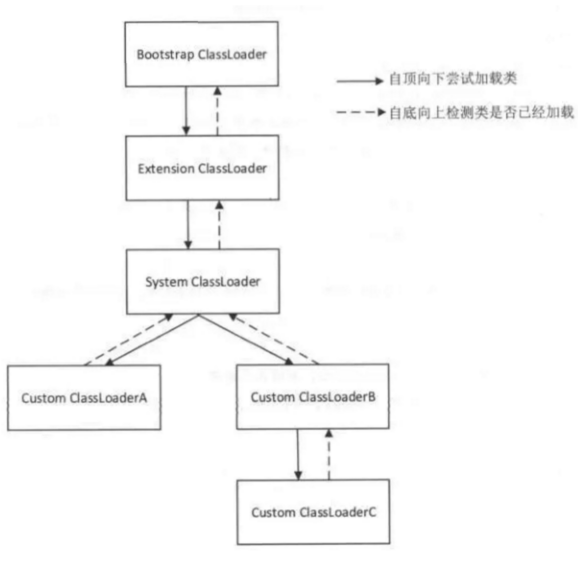
1、双亲委派模型
原理:当一个类加载器收到类加载任务时,会先交给自己的父加载器去完成,因此最终加载任务都会传递到最顶层的BootstrapClassLoader,只有当父加载器无法完成加载任务时,才会尝试自己来加载。
具体:根据双亲委派模式,在加载类文件的时候,子类加载器首先将加载请求委托给它的父加载器,父加载器会检测自己是否已经加载过类,如果已经加载则加载过程结束,如果没有加载的话则请求继续向上传递直Bootstrap ClassLoader。如果请求向上委托过程中,如果始终没有检测到该类已经加载,则Bootstrap ClassLoader开始尝试从其对应路劲中加载该类文件,如果失败则由子类加载器继续尝试加载,直至发起加载请求的子加载器为止。每个类加载器只能加载其对应的目录中的class文件。
采用双亲委派模式可以保证类型加载的安全性,不管是哪个加载器加载这个类,最终都是委托给顶层的BootstrapClassLoader来加载的,只有父类无法加载自己猜尝试加载,这样就可以保证任何的类加载器最终得到的都是同样一个Object对象。


protected Class<?> loadClass(String name, boolean resolve) { synchronized (getClassLoadingLock(name)) { // 首先,检查该类是否已经被加载,如果从JVM缓存中找到该类,则直接返回 Class<?> c = findLoadedClass(name); if (c == null) { try { // 遵循双亲委派的模型,首先会通过递归从父加载器开始找, // 直到父类加载器是BootstrapClassLoader为止 if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) {} if (c == null) { // 如果还找不到,尝试通过findClass方法去寻找 // findClass是留给开发者自己实现的,也就是说 // 自定义类加载器时,重写此方法即可 c = findClass(name); } } if (resolve) { resolveClass(c); } return c; } }
2.双亲委派模型缺陷
在双亲委派模型中,子类加载器可以使用父类加载器已经加载的类,而父类加载器无法使用子类加载器已经加载的。这就导致了双亲委派模型并不能解决所有的类加载器问题。
案例:Java 提供了很多服务提供者接口(Service Provider Interface,SPI),允许第三方为这些接口提供实现。常见的 SPI 有 JDBC、JNDI、JAXP 等,这些SPI的接口由核心类库提供,却由第三方实现,这样就存在一个问题:SPI 的接口是 Java 核心库的一部分,是由BootstrapClassLoader加载的;SPI实现的Java类一般是由AppClassLoader来加载的。BootstrapClassLoader是无法找到 SPI 的实现类的,因为它只加载Java的核心库。它也不能代理给AppClassLoader,因为它是最顶层的类加载器。也就是说,双亲委派模型并不能解决这个问题。
3.使用线程上下文类加载器(ContextClassLoader)加载
如果不做任何的设置,Java应用的线程的上下文类加载器默认就是AppClassLoader。在核心类库使用SPI接口时,传递的类加载器使用线程上下文类加载器,就可以成功的加载到SPI实现的类。线程上下文类加载器在很多SPI的实现中都会用到。
通常我们可以通过Thread.currentThread().getClassLoader()和Thread.currentThread().getContextClassLoader()获取线程上下文类加载器。
4、使用类加载器加载资源文件,比如jar包。
类加载器除了加载class外,还有一个非常重要功能,就是加载资源,它可以从jar包中读取任何资源文件,比如,ClassLoader.getResources(String name)方法就是用于读取jar包中的资源文件。
//获取资源的方法 public Enumeration<URL> getResources(String name) throws IOException { Enumeration<URL>[] tmp = (Enumeration<URL>[]) new Enumeration<?>[2]; if (parent != null) { tmp[0] = parent.getResources(name); } else { tmp[0] = getBootstrapResources(name); } tmp[1] = findResources(name); return new CompoundEnumeration<>(tmp); }
二、spring-boot-SPI
1.SPI机制
(1)SPI思想
SPI的全名为Service Provider Interface.这个是针对厂商或者插件的。
SPI的思想:系统里抽象的各个模块,往往有很多不同的实现方案,比如日志模块的方案,xml解析模块、jdbc模块的方案等。面向的对象的设计里,我们一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。java spi就是提供这样的一个机制:为某个接口寻找服务实现的机制
(2)SPI约定
当服务的提供者,提供了服务接口的一种实现之后,在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。通过这个约定,就不需要把服务放在代码中了,通过模块被装配的时候就可以发现服务类了。
2、SPI使用案例
common-logging apache最早提供的日志的门面接口。只有接口,没有实现。具体方案由各提供商实现, 发现日志提供商是通过扫描 META-INF/services/org.apache.commons.logging.LogFactory配置文件,通过读取该文件的内容找到日志提工商实现类。只要我们的日志实现里包含了这个文件,并在文件里制定 LogFactory工厂接口的实现类即可。
3、springboot中的类SPI扩展机制
在springboot的自动装配过程中,最终会加载META-INF/spring.factories文件,而加载的过程是由SpringFactoriesLoader加载的。从CLASSPATH下的每个Jar包中搜寻所有META-INF/spring.factories配置文件,然后将解析properties文件,找到指定名称的配置后返回。需要注意的是,其实这里不仅仅是会去ClassPath路径下查找,会扫描所有路径下的Jar包,只不过这个文件只会在Classpath下的jar包中。
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories"; // spring.factories文件的格式为:key=value1,value2,value3 // 从所有的jar包中找到META-INF/spring.factories文件 // 然后从文件中解析出key=factoryClass类名称的所有value值 public static List<String> loadFactoryNames(Class<?> factoryClass, ClassLoader classLoader) { String factoryClassName = factoryClass.getName(); // 取得资源文件的URL Enumeration<URL> urls = (classLoader != null ? classLoader.getResources(FACTORIES_RESOURCE_LOCATION) : ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION)); List<String> result = new ArrayList<String>(); // 遍历所有的URL while (urls.hasMoreElements()) { URL url = urls.nextElement(); // 根据资源文件URL解析properties文件,得到对应的一组@Configuration类 Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url)); String factoryClassNames = properties.getProperty(factoryClassName); // 组装数据,并返回 result.addAll(Arrays.asList(StringUtils.commaDelimitedListToStringArray(factoryClassNames))); } return result; }
总结:SPI的好处是避免写死,调用者可以根据自己的需求调用不同的实现类 。其中SpringBoot start组件也是SPI实现的一种,原理其实是类加载相关的知识点。其中SpringBoot组件中的SPI主要是配置项这一块,具体可以看下AutoConfigurationImportSelector这个实现类下面的源码,源码如下所示:SpringBoot的加载主要使用的是SpringFactoriesLoader这个加载器。在SpringBoot中,AutoConfigurationImportSelector这个类很重要。
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) { String factoryTypeName = factoryType.getName(); // 返回的是一个一个的配置文件,such as (org.springframework.boot.autoconfigure.data.elasticsearch.ElasticsearchAutoConfiguration) return loadSpringFactories(classLoader).getOrDefault(factoryTypeName, Collections.emptyList()); } private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) { // 先从缓存里面取数据 MultiValueMap<String, String> result = cache.get(classLoader); if (result != null) { return result; } try { Enumeration<URL> urls = (classLoader != null ? classLoader.getResources(FACTORIES_RESOURCE_LOCATION) : ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION)); result = new LinkedMultiValueMap<>(); while (urls.hasMoreElements()) { URL url = urls.nextElement(); UrlResource resource = new UrlResource(url); // 根据资源路径获取properties配置文件 Properties properties = PropertiesLoaderUtils.loadProperties(resource); for (Map.Entry<?, ?> entry : properties.entrySet()) { String factoryTypeName = ((String) entry.getKey()).trim(); for (String factoryImplementationName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) { result.add(factoryTypeName, factoryImplementationName.trim()); } } } // 放到缓存里面,防止重复加载 cache.put(classLoader, result); return result; } catch (IOException ex) { throw new IllegalArgumentException("Unable to load factories from location [" + FACTORIES_RESOURCE_LOCATION + "]", ex); } }
下面的代码就是把一个一个的配置类进行实例化成对象,其中也是使用了反射的原理。代码如下所示:
@SuppressWarnings("unchecked")
private static <T> T instantiateFactory(String factoryImplementationName, Class<T> factoryType, ClassLoader classLoader) {
try {
Class<?> factoryImplementationClass = ClassUtils.forName(factoryImplementationName, classLoader);
if (!factoryType.isAssignableFrom(factoryImplementationClass)) {
throw new IllegalArgumentException(
"Class [" + factoryImplementationName + "] is not assignable to factory type [" + factoryType.getName() + "]");
}
return (T) ReflectionUtils.accessibleConstructor(factoryImplementationClass).newInstance();
}
catch (Throwable ex) {
throw new IllegalArgumentException(
"Unable to instantiate factory class [" + factoryImplementationName + "] for factory type [" + factoryType.getName() + "]",
ex);
}
}
三、使用场景
概括地说,适用于:调用者根据实际使用需要,启用、扩展、或者替换框架的实现策略。
比较常见的例子:
- 数据库驱动加载接口实现类的加载:JDBC加载不同类型数据库的驱动
- 日志门面接口实现类加载:SLF4J加载不同提供商的日志实现类
- Spring:Spring中大量使用了SPI,比如:对servlet3.0规范对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等
- Dubbo:Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,允许用户扩展实现Filter接口
四、使用说明
4.1 java-SPI
1、要使用Java SPI,需要遵循如下约定:
当服务提供者提供了接口的一种具体实现后,在jar包的META-INF/services目录下创建一个以“接口全限定名”为命名的文件,内容为实现类的全限定名;
接口实现类所在的jar包放在主程序的classpath中;
主程序通过java.util.ServiceLoder动态装载实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM;
SPI的实现类必须携带一个不带参数的构造方法;
2、实现方式:
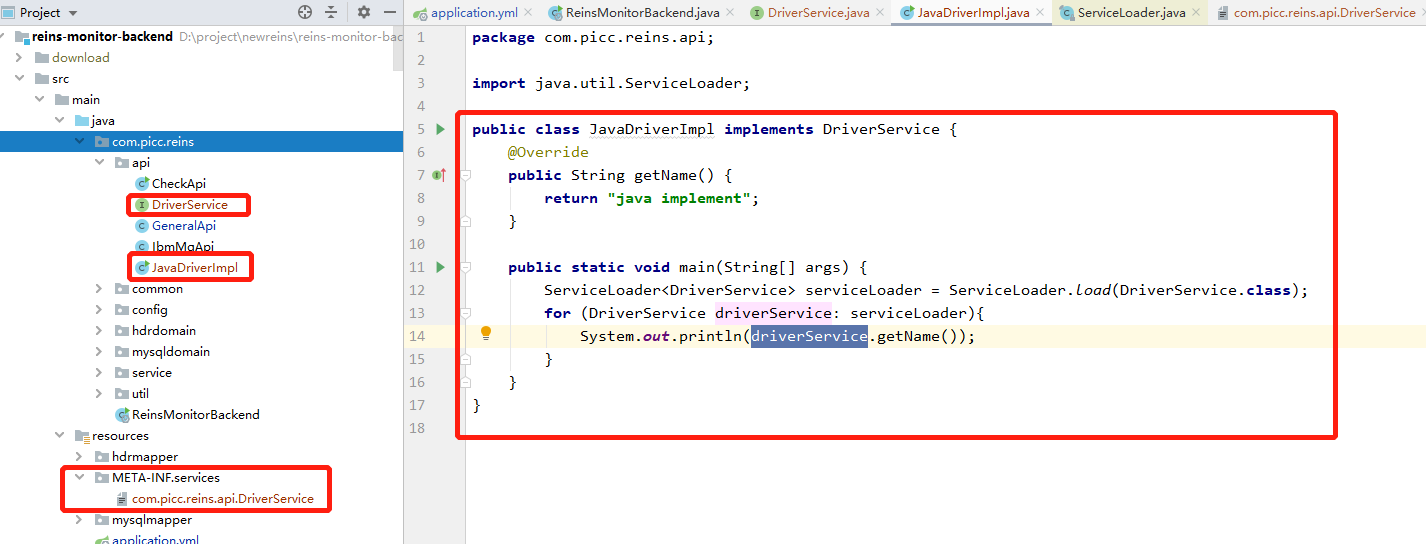
- 写service 具体对外提供的接口
public interface DriverService {
String getName();
}
- 具体的实现,继承对应的接口
public class JavaDriverImpl implements DriverService {
@Override
public String getName() {
return "java implement";
}
}
- 编写META-INF/service 具体的实现类 包名+类名

com.chengjue.spi.JavaDriverImpl
- 编译jar包对外提供服务
使用方:
- 引用相关依赖 jar包
- 使用ServiceLoader加载使用
public static void main(String[] args) {
ServiceLoader<DriverService> serviceLoader = ServiceLoader.load(DriverService.class);
for (DriverService driverService: serviceLoader){
System.out.println(driverService.getName());
}
}3、自己测试:
4.2Springboot实例运用
Springboot相信很多人都用过,在spring-boot和spring-boot-autoconfigure这两个jar包的META-INF/spring.factories路径下,保存的就是springboot使用SPI机制配置的属性,里面有sprignboot运行时需要读取的类,包括EnableAutoConfiguration等自动配置类,其部分关键配置如下:
# PropertySource Loaders org.springframework.boot.env.PropertySourceLoader= org.springframework.boot.env.PropertiesPropertySourceLoader, org.springframework.boot.env.YamlPropertySourceLoader # Application Listeners org.springframework.context.ApplicationListener= org.springframework.boot.ClearCachesApplicationListener, org.springframework.boot.builder.ParentContextCloserApplicationListener, org.springframework.boot.context.FileEncodingApplicationListener, org.springframework.boot.context.config.AnsiOutputApplicationListener, org.springframework.boot.context.config.ConfigFileApplicationListener,
在这里面配置了PropertySourceLoader和ApplicationListener等接口的具体实现类,然后通过SpringFactoriesLoader这个类去加载这个文件,并获得具体的类路径。
SpringFactoriesLoader其部分关键源码如下:
public final class SpringFactoriesLoader { // 加载器所需要加载的路径 public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories"; private static Map<String, List<String>> loadSpringFactories( @Nullable ClassLoader classLoader) { MultiValueMap<String, String> result = cache.get(classLoader); if (result != null) { return result; } try { // 根据路径去录取各个包下的文件 Enumeration<URL> urls = (classLoader != null ? classLoader.getResources(FACTORIES_RESOURCE_LOCATION) : ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION)); result = new LinkedMultiValueMap<>(); // 获取后进行循环遍历,因为不止一个包有spring.factories文件 while (urls.hasMoreElements()) { URL url = urls.nextElement(); UrlResource resource = new UrlResource(url); Properties properties = PropertiesLoaderUtils .loadProperties(resource); // 获取到了key和value对应关系 for (Map.Entry<?, ?> entry : properties.entrySet()) { String factoryClassName = ((String) entry.getKey()).trim(); // 循环获取配置文件的value,并放进result集合中 for (String factoryName : StringUtils .commaDelimitedListToStringArray( (String) entry.getValue())) { result.add(factoryClassName, factoryName.trim()); } } } // 并缓存起来,以便后续直接获取 cache.put(classLoader, result); return result; } catch (IOException ex) { ... } } }
当开发者获取到这些key-value后,便可以直接使用Class.forName()方法获取Class对象,接着使用Class实例化便可以完成基于接口的编程+策略模式+配置文件这种搭配模式了。
五、总结
优点
使用Java SPI机制的优势是实现解耦,使得第三方服务模块的装配控制的逻辑与调用者的业务代码分离,而不是耦合在一起。应用程序可以根据实际业务情况启用框架扩展或替换框架组件。
缺点
虽然ServiceLoader也算是使用的延迟加载,但是基本只能通过遍历全部获取,也就是接口的实现类全部加载并实例化一遍。如果你并不想用某些实现类,它也被加载并实例化了,这就造成了浪费。获取某个实现类的方式不够灵活,只能通过Iterator形式获取,不能根据某个参数来获取对应的实现类。
多个并发多线程使用ServiceLoader类的实例是不安全的。
参看链接:
https://my.oschina.net/kipeng/blog/1789849
https://blog.csdn.net/Peelarmy/article/details/106872570
https://www.cnblogs.com/jelly12345/p/13080647.html