1. 安装tensorflow
pycharm-file-settings-project interpreter-最右侧绿色添加按钮-搜索tensorflow-install packages
注意tensorflow只支持64位
2. 简介
TensorFlow 是一个使用数据流图进行数值计算的开源软件库。图中的节点代表数学运算, 而图中的边则代表在这些节点之间传递的多维数组(张量)。
节点被称为op(opration)
图必须在会话(session)中启动
3. 构建图
默认图现在有三个节点, 两个 constant() op, 和一个matmul() op.
import tensorflow as tf matrix1 = tf.constant([[3,3]]) matrix2 = tf.constant([[2], [2]]) product = tf.matmul(matrix1, matrix2)
4. 启动图
方法一:
sess = tf.Session() result = sess.run(product) print(result) sess.close()
方法二:
with tf.Session() as sess: result2 = sess.run(product) print(result2)
5. 数据结构 tensor
tensor 可以看作是一个 n 维的数组或列表.
6. 变量 variable
通常会将一个统计模型中的参数表示为一组变量. 例如, 你可以将一个神经网络的权重作为某个变量存储在一个 tensor 中. 在训练过程中, 通过重复运行训练图, 更新这个 tensor.
import tensorflow as tf state = tf.Variable(0, name='counter') one = tf.constant(1) new_value = tf.add(state, one) update = tf.assign(state, new_value) init = tf.initialize_all_variables() with tf.Session() as sess: sess.run(init) print(sess.run(state)) # 0 for _ in range(3): sess.run(update) print(sess.run(state)) # 1 2 3
7. 占位符 placeholder
在运行时在使用feed_dict输入值
import tensorflow as tf input1 = tf.placeholder(tf.float32) input2 = tf.placeholder(tf.float32) output = tf.multiply(input1, input2) with tf.Session() as sess: print(sess.run(output, feed_dict={input1:[7], input2:[2]}))
8. 激活函数 activation function
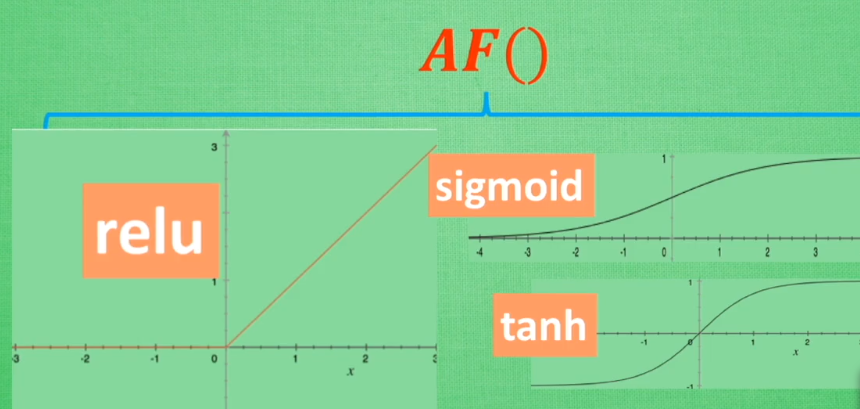
只有两三层的神经网络,隐藏层可以使用任意激活函数。卷积神经网络推荐relu,循环神经网络推荐relu或tanh。
多层神经网络需要谨慎选择激活函数。
9. 添加神经层
def add_layer(inputs, in_size, out_size, activation_function=None): Weight = tf.Variable(tf.random_normal([in_size, out_size])) # 初始权重随机 biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) # biases推荐不为0,所以需要加上0.1 Wx_plus_b = tf.matmul(inputs, Weight) + biases # 激活前 if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs
示例:
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt def add_layer(inputs, in_size, out_size, activation_function=None): Weight = tf.Variable(tf.random_normal([in_size, out_size])) # 初始权重随机 biases = tf.Variable(tf.zeros([1, out_size]) + 0.1) # biases推荐不为0,所以需要加上0.1 Wx_plus_b = tf.matmul(inputs, Weight) + biases # 激活前 if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b) return outputs # 数据准备 x_data = np.linspace(-1, 1, 300)[:, np.newaxis] # 生成[-1,1]之间的300个数,组成300行的一个数组 noise = np.random.normal(0, 0.05, x_data.shape) # mean = 0;std = 0.05; 格式:x_data y_data = np.square(x_data) - 0.5 + noise # y = x^2 - 0.5 # 搭建神经网络 # 由于输入一维,输出一维,所以我们定义的神经网络为输入层一个神经元,输出层一个神经元,中间隐藏层10个神经元 xs = tf.placeholder(tf.float32, [None, 1]) # None表示sample数量任意 ys = tf.placeholder(tf.float32, [None, 1]) l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu) # 隐藏层 prediction = add_layer(l1, 10, 1, activation_function=None) # 输出层 # 计算损失函数 loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) # 距离平方求和求平均,reduction_indices表示数据处理的维度 # 训练 train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) # learning rate = 0.1 # 初始化 init = tf.initialize_all_variables() # 初始化所有变量 sess = tf.Session() sess.run(init) fig = plt.figure() ax = fig.add_subplot(1, 1, 1) ax.scatter(x_data, y_data) plt.ion() # 保证连续输出 # 可视化输出 for i in range(1000): sess.run(train_step, feed_dict={xs: x_data, ys: y_data}) if i % 50 == 0: # 每50个数据输出一次 try: # 为了避免第一次remove时报错 ax.lines.remove(lines[0]) except Exception: pass prediction_value = sess.run(prediction, feed_dict={xs: x_data}) lines = ax.plot(x_data, prediction_value, 'r-', lw=5) plt.pause(0.1) # 暂停0.1秒