1.HTML的基本结构
- <html>内容</html>:HTML文档是由<html></html>包裹,这是HTML文档的文档标记,也称为HTML开始标记。这对标记分别位于网页的最前端和最后端,<html>在最前端表示网页的开始,</html>在最后端表示网页的结束。
- <head>内容</head>:HTML文件头标记,也称为HTML头信息开始标记。用来包含文件的基本信息,比如网页的标题、关键字,在<head></head>内可以放<tittle></title>、<meta></meta>、<style></style>等标记。注意:在<head></head>标记内的内容不会在浏览器中显示。
- <title>内容</title>:HTML文件标题标记。网页的“主题”,显示在浏览器的窗口的左上边。
- <body>内容</body>:<body>...<body>是网页的主体部分,在此标记之间可以包含如<p></p>、<hl></hl>、<br>、<hr>等等标记,正是这些内容组成我们所看见的网页。
- <meta>内容<meta>:页面的元信息。提供有关页面的元信息,比如针对搜索引擎和更新频度的描述和关键词。注意:meta标记必须放在head元素里面
2.文档设置标记
文档设置标记分为格式标记和文本标记。
以下是文档:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Python爬虫开发与项目实践</title>
</head>
<body>
Python爬虫学习第一天.<br>
<p>今天是2019-6-13,周四。是学习爬虫的第一天,当然是有一点懵的一天啦,毕竟是第一次学这个。</p>
<p>以前完全没想到,爬虫这么有趣,可以自己编辑网页。哈哈哈哈</p>
<hr>
<center>居中标记</center>
<center>居中标记2</center>
<hr>
<pre>
[00:00](music)
[00:28]你我皆凡人,生在人世间;
[00:35]终日奔波苦,一刻不得闲;
[00:43]既然不是仙,难免有杂念;
</pre>
<hr>
<p>
[00:00](music)
[00:28]你我皆凡人,生在人世间;
[00:35]终日奔波苦,一刻不得闲;
[00:43]既然不是仙,难免有杂念;
</p>
<hr>
<br>
<ul>
<li>Coffee</li>
<li>Milk</li>
</ul>
<ol type="A">
<li>Coffee</li>
<li>Milk</li>
</ol>
<dl>
<dt>计算机</dt>
<dd>用来计算的仪器... ...</dd>
<dt>显示器<dt>
<dd>以视觉方式显示信息的装置... ...</dd>
</dl>
<div>
<h3>这是标题</h3>
<p>这是段落</p>
</div>
</body>
</html>
以下是文档在浏览器中打开后的显示:
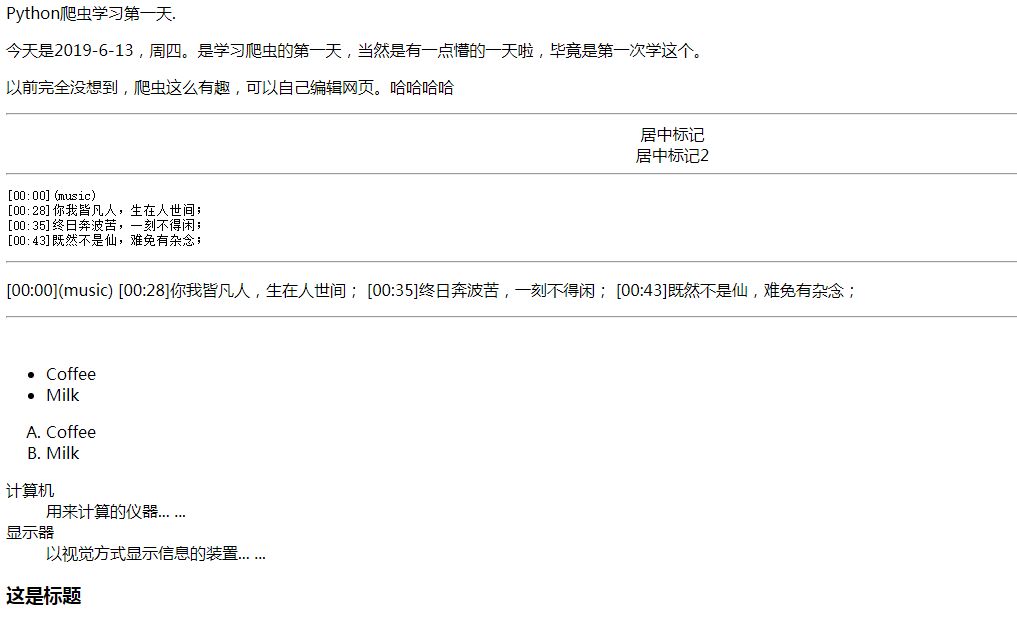
<p></p>之间的内容呈现的是一个段落(无论多少个段落都将显示成一个段落)。
<hr>呈现的是一条横线
<center></center>之间的内容呈现的形式是居中显示。
<pre>(一个段落)(一个段落)(一个段落)(一个段落)</pre>之间的每个段落以段落形式显示
<dt>内容</dt>:之间的内容显示方式为左对齐
<dd>内容</dd>:之间的内容显示方式为缩进两个字符
####<br>:强制换行标记。让后面的文字、图片、表格等等,显示在下一行
####<p>:换段落标记。
####<center>:居中对齐标记。
####<pre>:预格式化标记。保留预先编排好的格式,常用来定义计算机源代码。
####<li>:列表项目标记。每一个列表使用一个<li>标记,可用在有序列表<ol>和无序列表<ul>中
####<ol>:有序列表标记,可以显示特定的一些顺序,有序列表的type属性值“1”代表阿拉伯数字1.2.3等等......"a"...."A"...
####<dl><dt><dd>:定义型列表
####<div>:分区显示标记,也称为层标记
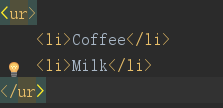 显示结果为:
显示结果为: 
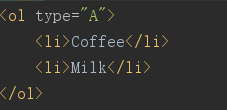 显示结果为:
显示结果为: 