前言
在机器学习的算法训练数据前,一般要进行数据归一化,统一量纲。

以上图为例,样本间的距离被发现时间所主导,肿瘤大小就被忽略了。
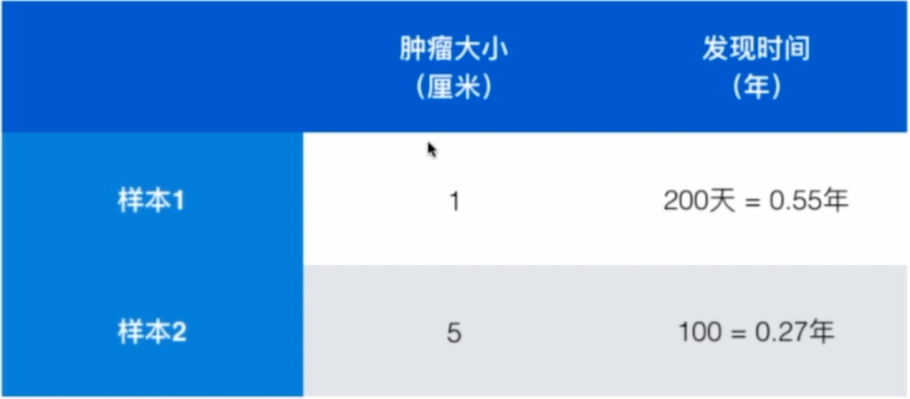
将天换算成年之后,样本间的距离又被肿瘤大小所主导,发现时间被忽略了。
解决方法就是将所有数据映射到同一尺度。
最值归一化
将数据映射到0-1之间,适用于数据有明显边界的情况,如学生成绩,图片像素点等。
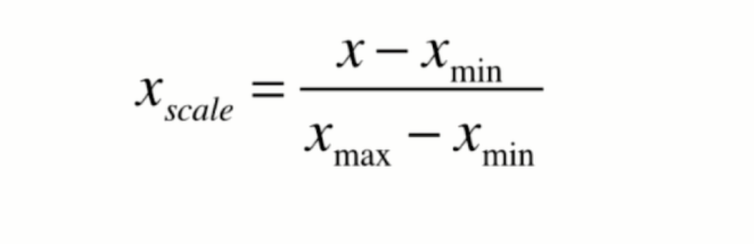
代码实现
import numpy as np
x = np.random.randint(0, 10, 10)
print(x)
print((x - np.min(x)) / (np.max(x) - np.min(x)))
输出结果为
[6 5 7 6 3 3 8 5 1 0]
[0.75 0.625 0.875 0.75 0.375 0.375 1. 0.625 0.125 0. ]
都在0-1之间
0均值归一化
将数据映射到均值为0,标准差为1的分布中

mean表示数据的均值,S表示标准差
代码实现
import numpy as np
x = np.random.randint(0, 10, 10)
print(x)
x2 = (x - np.mean(x)) / np.std(x)
print(x2)
print(np.mean(x2))
print(np.std(x2))
输出结果为
[4 1 9 3 7 3 0 1 2 0]
[ 0.35355339 -0.70710678 2.12132034 0. 1.41421356 0.
-1.06066017 -0.70710678 -0.35355339 -1.06066017]
0.0
0.9999999999999999
均值为0,标准差为1
sklearn中的数据归一化
sklearn是机器学习常用的第三方模块,封装了常用的机器学习算法。
import numpy as np
from sklearn.preprocessing import StandardScaler
x = np.random.randint(0, 10, 10)
x = np.array(x, dtype=float).reshape(2, 5)
print(x)
scaler = StandardScaler()
scaler.fit(x)
x = scaler.transform(x)
print(np.mean(x))
print(np.std(x))
StandardScaler就是sklearn提供的进行数据归一化的工具,内部也是使用0均值归一化的方法。