前提:
在spark环境下,当我们传递一个操作(例如:map,reduce)的函数到远程多个节点上进行运行时,各个节点都需要使用到该函数中的变量。如果变量比较大,如何下发这些变量呢?如果我们使用下面的方式,进行数据下发:

即将变量从Driver下发到每一个执行的task中。 例如:50个executor,1000个task。传递数据map类型,大小10M。网络传输中,需要传递1000个副本,则在集群中总共耗费10M*1000=10G的网络资源。如何减少这些资源,进行调优,则可以使用广播变量。
一:广播变量的原理
(一)广播变量使用原理图
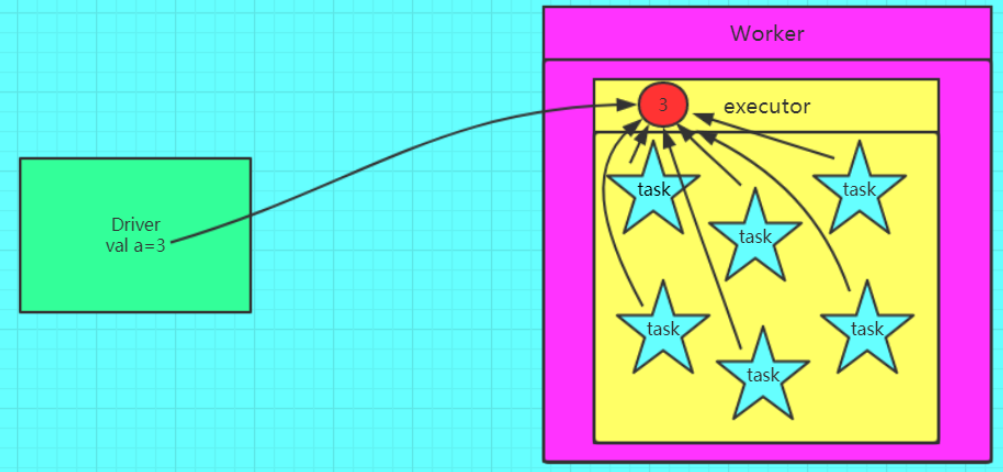
(二)广播变量原理
广播变量,初始的时候,就在Drvier上有一份副本。
task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中,尝试获取变量副本;如果本地没有,那么就从Driver远程拉取变量副本,并保存在本地的BlockManager中;此后这个executor上的task,都会直接使用本地的BlockManager中的副本。
executor的BlockManager除了从driver上拉取,也可能从其他节点的BlockManager上拉取变量副本。
(三)BlockManager
负责管理某个Executor对应的内存和磁盘上的数据。
二:广播变量的使用案例
同前提中所用案例:50个executor,1000个task。传递数据map类型,大小10M。使用广播变量,在集群网络传输中,最多只需要50个副本(因为不一定都是从Driver中获取数据,更可能的是从最近的节点的executor的blockmanager中拉取变量副本),网络传输速度极大增加。甚至小于500M的传输消耗。效率提高了20以上。可以使进行了很好的调优。
(一)调优的重要性
没有经过任何调优手段的spark作业,16个小时;三板斧下来,就可以到5个小时;然后非常重要的一个调优,影响特别大,shuffle调优,2~3个小时;应用了10个以上的性能调优的技术点,JVM+广播,30分钟。16小时与30分钟的差别。
三:广播变量的使用
(一)定义一个广播变量
val a = 3 val bc = sc.broadcast(a) //sc是SparkContext
(二)使用一个广播变量
使用广播变量的时候,直接调用广播变量(Broadcast类型)的value() / getValue() 可以获取到之前封装的广播变量。
val c = bc.value