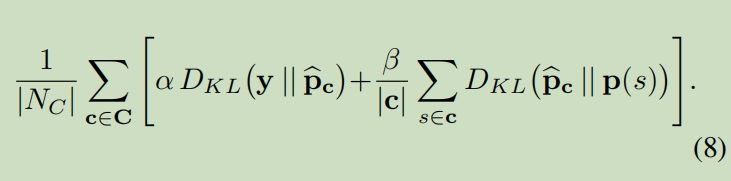motivation
以前的人脸分割方法都旨在产生复杂的框架,或者复杂的人脸增强器来同化模糊,或者用对抗训练。我们采用了一种可选择的路径来进行强壮的人脸分割和解析
contribution
(1)通过3维投影使用强先验计算得到完整的人脸形状,与事先存在的人脸分割网络之间的差异来进行分解遮挡
(2)利用前面分解的对象的连接组件,将他们作为约束来构造一个新的损失函数,该函数仍然执行一个密集的分类,但通过共识学习在网络中加强结构
(3)最后展示我们的方法对于人脸解析问题是一个通用的工具


f是全脸轮廓的掩膜,fooc是人脸分割的掩膜。p是残差。p最后是由先腐蚀操作再膨胀操作的开运算(其作用是:分离物体,消除小区域。本文中则把红色部分的blob给消除掉了)得到的。

(2)式课看做分段函数,C(s)相当于y上的自变量。当C(s)取值不同时,y(s)代表的含义不同
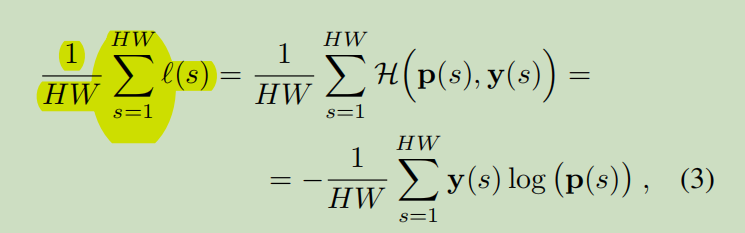
s=1表示face上的像素的位置,p(s)表示face上的softmax概率,y(s)表示face上的真实值。H为交叉熵。则(3)式是指交叉熵损失函数即:所有像素的图像的预期损失

(a)符号说明
(b)常规训练以像素为方向,独立进行,并密集地强制每个像素适合标签(没有对象平滑度的概念)
(c)这导致了在测试时对看不见的物体的稀疏预测
(d)图像的像素级标签
(e)我们在一个blob E[p]中强制对标签进行预期预测,但保证每个像素与平均值没有偏差;
(f)该网络是更好的正则化分割与较少的稀疏预测
We defifine the expected prob-ability E[p] on a blob c as:
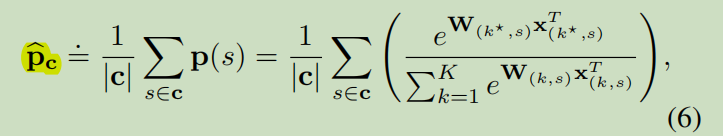
p^c表示在斑点c处所有像素的平均条件概率
p(s)表示整个图像上所有像素的预测概率
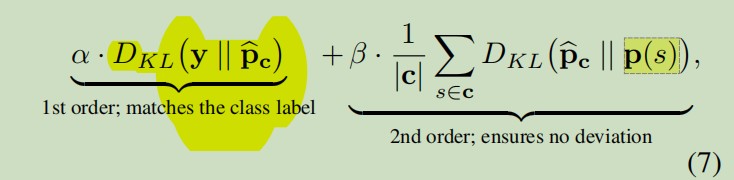
DKL表示相对熵(KL散度):
如果对于同一个随机变量X有两个单独的概率分布P(x)和Q(x),则我们可以使用KL散度来衡量这两个概率分布之间的差异。
where α, β are two constant parameters controlling the trade-off between matching the labels and ensuring consensus and DKL denotes the Kullback-Leibler divergence.
Following the notation of Section 3.1, and putting this all together, indicating all the the blobs (background B, face F, occlusions O) as C, our method fifinally optimizes: