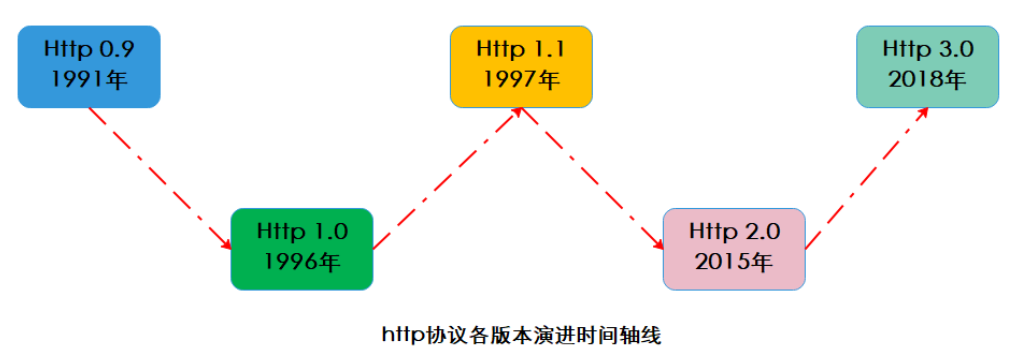
我们通常熟悉的 http 版本是 1.0 和 2.0,但是都很少知道它的演变过程,下面就带领大家粗略的认识一下
演变时间时间图
http/0.9
初代版本,只有一个get方法,纯文本,html格式,是典型的无状态连接。(无状态是指协议会与事务处理没有记忆功能,对同一个请求没有上下文关系,每次请求都是独立的,服务器没有保存客户端的状态)
http/1.0
新增post、head方法;规定客户端和服务器只保持短暂连接(短连接),客户端每次请求都需要建立一次TCP连接,服务器完成请求后就断开TCP连接,服务器也不跟踪每个客户也不记录过去的操作。(支持通过声明keep-alive建立长连接,但默认短连接)
http/1.1
新增put、patch、options、delete方法;
引入长连接,默认TCP连接不关闭,可以被多个请求复用,不用声明keep-alive,服务端发现对方长时间没有活动就会关闭连接;
对同一个域名允许同时建立6个长连接;
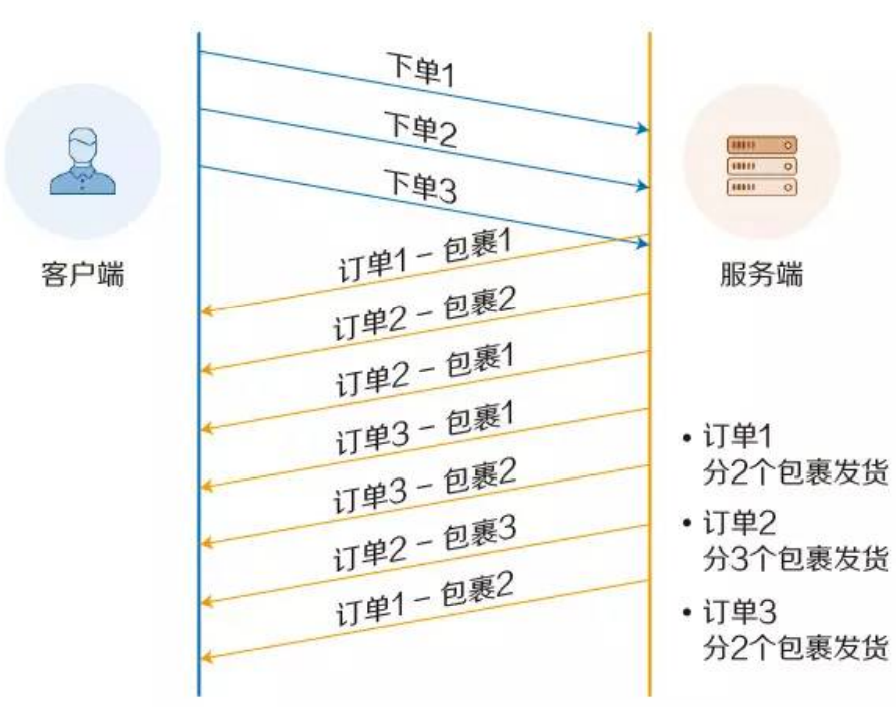
引入了管道网络传输机制,即可在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。

管道网络传输的情况下,服务端是按照顺序处理请求的,如果前面的请求需要长时间处理,后面的只能干等,这叫队头堵塞。
缓解队头堵塞的方法:并发连接(就是同时对一个域名发起多个长连接,用数量来解决质量的问题。但这种方式也存在缺陷。如果每个客户端都想自己快,建立很多个连接,用户数×并发数就会是个天文数字。服务器的资源根本就扛不住,或者被服务器认为是恶意攻击,反而会造成“拒绝服务”。所以,HTTP 协议建议客户端使用并发,但不能“滥用”并发。RFC2616 里明确限制每个客户端最多并发 2 个连接)和域名分片(HTTP 协议和浏览器不是限制并发连接数量吗?好,那我就多开几个域名,比如 file.dada.com、img.dada.com,而这些域名都指向同一台服务器 www.dada.com)。
http/1.1没有解决的问题:
- 请求/响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩 Body 的部分;
- 发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应。
http/2.0
- 头部压缩:如果同时发出多个请求,头部是一样的或者相似的,协议会帮忙消除重复的部分,这就是HPACK算法,在客户端和服务器同时维护一张头部信息表,所有字段会存入这张表,生成一个索引号,这样就不用发送相同字段,发索引就好,提高速度。
- 二进制格式:HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧:头信息帧和数据帧。这样虽然对人不友好,但是对计算机非常友好,因为计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
- 数据流:HTTP/2 的数据包不是按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。每个请求或回应的所有数据包,称为一个数据流(Stream)。每个数据流都标记着一个独一无二的编号,其中规定客户端发出的数据流编号为奇数, 服务器发出的数据流编号为偶数。客户端还可以指定数据流的优先级。优先级高的请求,服务器就先响应该请求。
- 并发处理请求:可以在一个连接中并发多个请求或回应,而不用按照顺序一一对应。移除了 HTTP/1.1 中的串行请求,不需要排队等待,也就不会再出现「队头阻塞」问题,降低了延迟,大幅度提高了连接的利用率。举例来说,在一个 TCP 连接里,服务器收到了客户端 A 和 B 的两个请求,如果发现 A 处理过程非常耗时,于是就先回应 A 请求已经处理好的部分,接着回应 B 请求,完成后,再回应 A 请求剩下的部分。
- 服务器推送:服务器不是被动响应,可以主动向客户端发消息,举例来说,在浏览器刚请求 HTML 的时候,就提前把可能会用到的 JS、CSS文件等静态资源主动发给客户端,减少延时的等待。