从《数据挖掘概念与技术》到《Web数据挖掘》
认真读过《数据挖掘概念与技术》的第一章后,对数据挖掘有了更加深刻的了解。数据挖掘是知识发展过程的一个步骤。知识发展的过程可以分为:数据清洗(去噪和去除不一致数据)、数据集成(多个数据源组合在一起)、数据选择(从数据库中提取和分析与任务相关的数据)、数据变换(汇总、聚集,变成统一形式)、数据挖掘(智能方法提取数据模式)、模式评估(根据兴趣度度量、识别代表知识的真正有趣的模式)、知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。数据的基本组成形式包括:数据库数据、数据仓库数据(异构数据源在单个站点以统一的模式组织的存储)、事物数据、其他数据(时间数据挖掘、计算机网络数据、空间数据、文本数据、多媒体数据和Web数据)。数据的可挖掘的模式包括:类/概念描述:特征化与区别、挖掘频繁模式、关联和相关性(频繁模式包括频繁项集、频繁子序列和频繁子结构)、用于预测分析的分类和回归(导出的模型可以用各种形式表示,如分类规则、决策树、数学公式、神经网络)、聚类分析、离群点分析;数据挖掘作为一个交叉学科,设计统计学、机器学习、模式识别、数据库系统与数据仓库、信息检索、算法等;数据挖掘的主要问题包括:挖掘方法、用户交互、有效性与可伸缩性、数据类型的多样性、数据挖掘与社会。
通过对引言部分的总结,发现Web数据可以作为数据挖掘领域的有趣分支进行深入钻研,所以今后的方向打算对《Web数据挖掘》进行深入探讨。
Web数据挖掘的目标是从Web的超链接结构、网页内容和使用日志中探寻有用的信息。Web挖掘的任务可以换分为三种:Web结构挖掘(从表征Web结构的超链接中寻找有用的知识,例如找寻重要的网页)、Web内容挖掘(从网页内容中抽取有用的信息和知识,自动进行聚类和分类,例如商品描述、论坛回帖等)、Web使用挖掘(从记录每位用户点击情况的使用日志中挖掘用户的访问模式,例如点击流数据的预处理)。Web挖掘过程中,数据收集是一项艰巨的任务,需要爬取大量的网页。之后就是进行数据预处理、Web数据挖掘和数据后续处理。
算法预备:关联规则
关联规则在网页和纯文本文件中,来找群单词见并发关系和Web的使用模式。
关联规则挖掘是指"给定一个事物集合T,找出T中多有满足支持度和置信度分别高于一个用户指定的最小支持度(T中包含X并Y的事物的百分比)和最小置信度(条件概率函数)"。在大量的关联规则挖掘算法中,尽管效率各不相同(是否对效率进行研究),但是在同样的关联规则定义下,他们的输出结果应该一样。
Apriori算法
Apriori算法分为两步进行;(1)生成所有频繁项目集(一个频繁项目集是一个支持度高于最小支持度的项集)(2)从频繁项目集中生成所有可信关联规则(一个可信关联规则是置信度大于最小置信度的规则)
频繁项集中的难点和重点是合并和剪枝,合并:将两个(k-1)-频繁项目集合并产生一个可能的k-候选项集c。两个频繁项目集f1和f2的前k-2个项目都是相同,只有最后一个项目是不同的。随后c被加入到候选项集集合Ck中。剪枝:从合并步中得到的候选项集集合并不是最终的Ck。需要判断c的所有(k-1)-子集是否都在Fk-1中。如果其中任何一个子集不在Fk-1中,则根据向下封闭原理,c必然不可能是频繁项目集,将c从候选集Ck中剔除。
关联规则生成算法中,需要记住一点,如果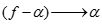 是一条关联规则,那么所有
是一条关联规则,那么所有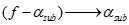 也必然是关联规则。
也必然是关联规则。
关联规则的挖掘可以应用在关系数据表上进行,只需要先把表数据转换成事物数据。