背景
在生产环境中使用springcloud框架,由于服务更新过程中,容器服务会被直接停止,部分请求仍被分发到终止的容器,导致服务出现500错误,这部分错误请求数据占用比较少,因为Pod滚动更新都是一对一。因为部分用户会产生服务器错误的情况,考虑使用优雅的终止方式,将错误请求降到最低,直至滚动更新不影响用户。这里结合nacos使用来分析。
nacos心跳检测时间
Nacos 目前支持临时实例使用心跳上报方式维持活性,发送心跳的周期默认是 5 秒,Nacos 服务端会在 15 秒没收到心跳后将实例设置为不健康,在 30 秒没收到心跳时将这个临时实例摘除。这里要注意30秒这个时间。
正常更新流程
当更新某一个应用时,先给nacos发送这个模块下线通知,等待30s中后再更新这个应用。
应用启动时会自动注册到nacos中。
引出问题
现在把该应用部署到k8s中,需要实现上面说的正常更新流程。这里就牵涉到使用k8s中的容器生命周期钩子PreStop。
Kubernetes钩子函数
PostStart: 这个钩子在容器创建后立即执行。但是,并不能保证钩子将在容器ENTRYPOINT之前运行,因为没有参数传递给处理程序。 主要用于资源部署、环境准备等。不过需要注意的是如果钩子花费时间过长以及于不能运行或者挂起,容器将不能达到Running状态。
PreStop: 钩子在容器终止前立即被调用。它是阻塞的,意味着它是同步的,所以它必须在删除容器的调用出发之前完成。主要用于优雅关闭应用程序、通知其他系统等。如果钩子在执行期间挂起,Pod阶段将停留在Running状态并且不会达到failed状态
简单说一下Pod终止的过程:
- 用户发送命令删除Pod,Pod进入Terminating状态
- service摘除Pod节点
- 当kubelet看到Pod已被标记终止,开始执行preStop钩子,假如preStop hook的运行时间超过了grace period,kubelet会发送SIGTERM并等2秒
k8s Pod Hook回顾
Pod Hook是由kubelet发起的,当容器中的进程启动前或者容器中的进程终止之前运行,这是包含在容器的生命周期之中。我们可以同时为Pod中的所有容器都配置hook。
在k8s中,理想的状态是pod优雅释放,并产生新的Pod。但是并不是每一个Pod都会这么顺利
- Pod卡死,处理不了优雅退出的命令或者操作
- 优雅退出的逻辑有BUG,陷入死循环
- 代码问题,导致执行的命令没有效果
对于以上问题,k8s的Pod终止流程中还有一个"最多可以容忍的时间",即grace period (在pod的.spec.terminationGracePeriodSeconds字段定义),这个值默认是30秒,当我们执行kubectl delete的时候也可以通过--grace-period参数显示指定一个优雅退出时间来覆盖Pod中的配置,如果我们配置的grace period超过时间之后,k8s就只能选择强制kill Pod。
Kubernetes等待指定的时间称为优雅终止宽限期。默认情况下,这是30秒。值得注意的是,这与preStop Hook和SIGTERM信号并行发生。Kubernetes不会等待preStop Hook完成。如果你的应用程序完成关闭并在terminationGracePeriod完成之前退出,Kubernetes会立即进入下一步。
如果您的Pod通常需要超过30秒才能关闭,请确保增加优雅终止宽限期(通过terminationGracePeriodSeconds来实现)
简单的说Kubernetes终止生命周期的每一步
- Pod 设置为Terminating状态,并从所有服务的Endpoints列表中删除
- 此时,Pod停止停止,但是Pod中运行的容器不受影响
- PreStop Hook被执行
- preStop Hook发送容器特殊命令或者Http请求到Pod中,Pod应用程序在接收到SIGTERM(该SIGTERM信号是用于导致程序终止的通用信号。不同于SIGKILL,该信号可以被阻止,处理和忽略。这是礼貌地要求程序终止的正常方法),如果使用第三方代码或者管理系统无法控制,则preStop Hook是在不修改应用程序的情况下触发
- SIGTERM信号发送给Pod
- 此时,Kubernetes将向Pod中的容器发送SIGTERM信号,这个信号即通知容器他们很快将进行关闭。
- Kubernetes等待优雅的终止
- 此时,Kubernetes等待指定的时间称为优雅终止宽限期。默认情况下,这是30秒(可以修改),值得注意的是,PreStop Hook和SIGTREM信息是属于并行执行,Kubernetes不会等待PreStop Hook完成。
如果Pod在terminationGracePeriod完成之前推出,Kubernetes将进如释放阶段,如果容器在优雅终止宽限期(terminationGracePeriod限定时间),则会发送SIGKILL信号并强制删除。与此同时,所有的Kubernetes对象也会被清除
问题分析
通过以上回顾,可以知道pod退出有个优雅终止宽限期(terminationGracePeriod限定时间),假如preStop hook的运行时间超过了grace period,kubelet会发送SIGTERM并等2秒,Kubernetes不会等待preStop Hook完成。
这里主要涉及到的就是preStop hook的运行时间和优雅终止宽限期(terminationGracePeriod限定时间)。
nacos下线应用地址举例:
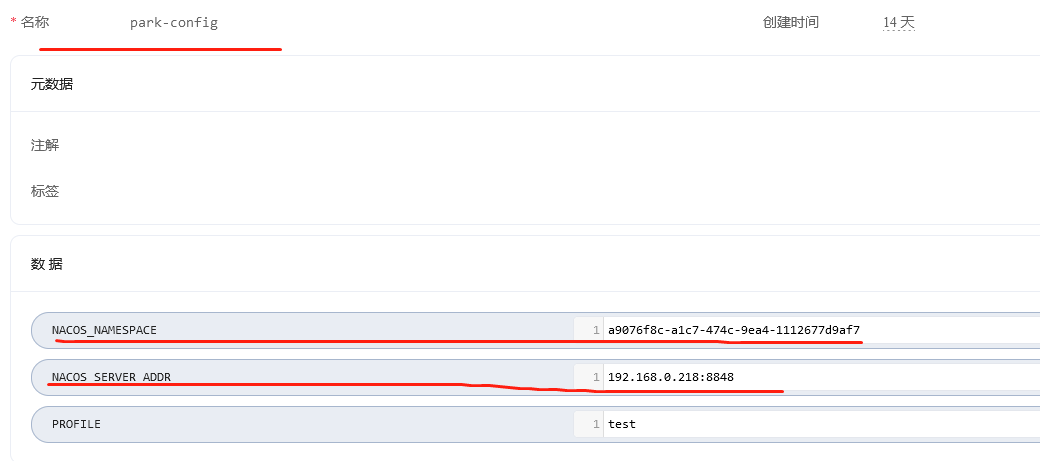
http://192.168.0.218:8848/nacos/v1/ns/instance?serviceName=jdd-parking-cloud-admin&clusterName=DEFAULT&groupName=DEFAULT_GROUP&ip=172.16.246.32&port=8093&ephemeral=true&weight=1&enabled=false&namespaceId=a9076f8c-a1c7-474c-9ea4-1112677d9af7
说明:
- 192.168.0.218:8848 nacos注册地址
- jdd-parking-cloud-admin 注册的应用名称
- 172.16.246.32 注册的应用名称所在主机地址
- 8093 注册的应用名称使用的端口号
- enabled=false 下线,enabled=true 上线
- namespaceId 命令空间,默认使用public命名空间则不写这个
通过分析nacos下线应用地址,需要如下参数:nacos注册地址,应用名称,应用所在主机ip,应用端口号,命令空间(public不需要)
考虑到应用所在主机ip是pod ip,这个需要从pod容器中获取,因此,不能在PreStop中使用命令行的形式,也就是如下的形式
curl -x PUT http://192.168.0.218:8848/nacos/v1/ns/instance?serviceName=jdd-parking-cloud-admin&clusterName=DEFAULT&groupName=DEFAULT_GROUP&ip=172.16.246.32&port=8093&ephemeral=true&weight=1&enabled=false&namespaceId=a9076f8c-a1c7-474c-9ea4-1112677d9af7

原因:nacos地址可以写死,应用名称可以写死,应用端口号可以写死,但是应用所在主机ip也就是pod ip没法获取。
1.PreStop是配置在Daeployment中的,pod的数量和ip都是不固定的。
2.就算把pod ip设置成环境变量的形式,也只能是在pod容器中使用,在PreStop中还是获取不到pod ip

综合以上分析,这里采取的办法是在构造镜像的时候入手,新增一个preStop.sh脚本,内容写上nacos下线的那个命令, 然后载PreStop命令行中执行这个脚本文件。
在这个过程中,若是有些参数值无法从环境变量中获取,则需要增加这些参数的环境变量。
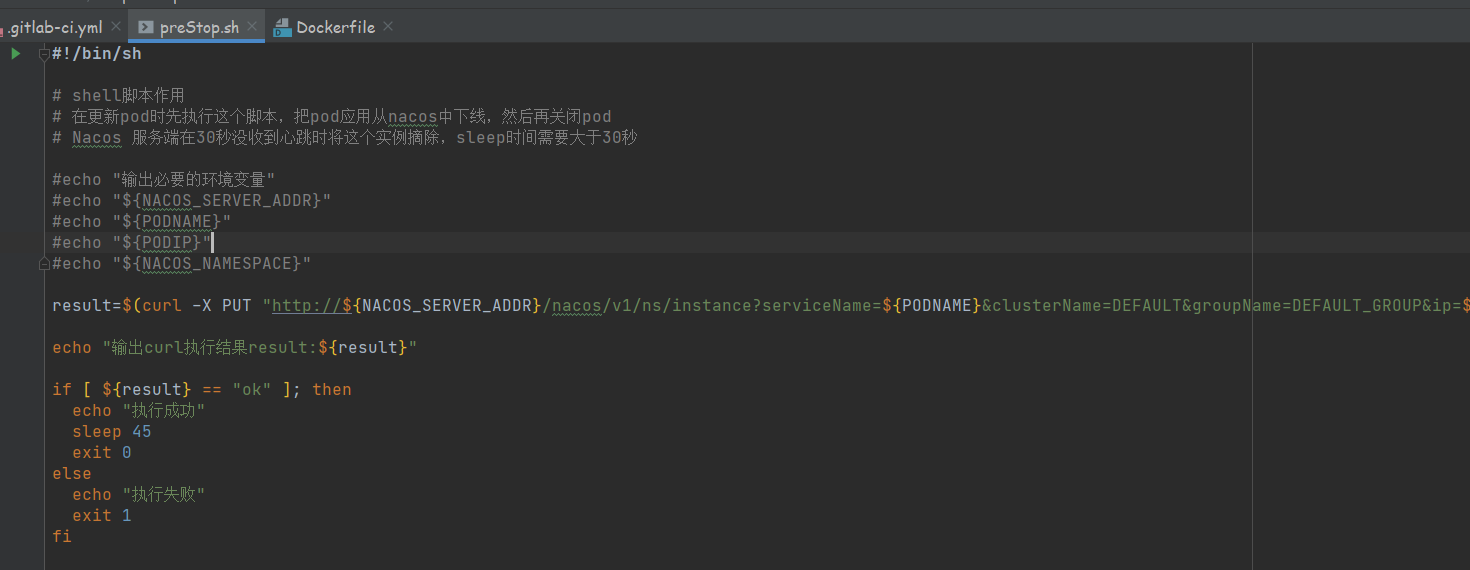
preStop脚本内容
注意脚本中的sleep 45命令,这个是确保应用从nacos中下线使用的,默认是30秒,具体看开头nacos心跳检测时间,sleep设置时间大于30秒就可以,这里设置45秒
preStop.sh脚本中使用的变量有些是默认提供的,有些是需要提前设置环境变量的,取值是容器中的值
#!/bin/sh
# shell脚本作用
# 在更新pod时先执行这个脚本,把pod应用从nacos中下线,然后再关闭pod
#echo "输出必要的环境变量"
#echo "${NACOS_SERVER_ADDR}"
#echo "${PODNAME}"
#echo "${PODIP}"
#echo "${NACOS_NAMESPACE}"
result=$(curl -X PUT "http://${NACOS_SERVER_ADDR}/nacos/v1/ns/instance?serviceName=${PODNAME}&clusterName=DEFAULT&groupName=DEFAULT_GROUP&ip=${PODIP}&port=8093&enabled=false&namespaceId=${NACOS_NAMESPACE}")
echo "输出curl执行结果result:${result}"
if [ ${result} == "ok" ]; then
echo "执行成功"
sleep 45
exit 0
else
echo "执行失败"
exit 1
fi
如上脚本中,
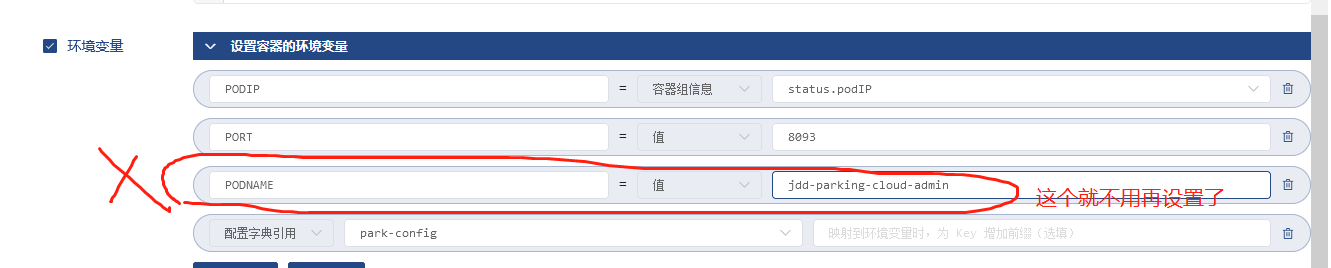
NACOS_SERVER_ADDR和NACOS_NAMESPACE从ConfigMap中设置中获取,
PODIP和PODNAME是在环境变量中手动设置的
然后修改Dockerfile文件,增加这个preStop脚本,设置可执行权限,注意脚本放置的路径,后面会用到
ADD preStop.sh /tmp/preStop.sh
RUN chmod 777 /tmp/preStop.sh
经过以上操作,项目中新增一个preStop脚本文件,把这个文件给添加到Dockerfile文件中,并放置到指定路径下,然后提交到gitlab,自动构建docker镜像,记住镜像标签。
然后在k8s中设置PreStop内容如下:
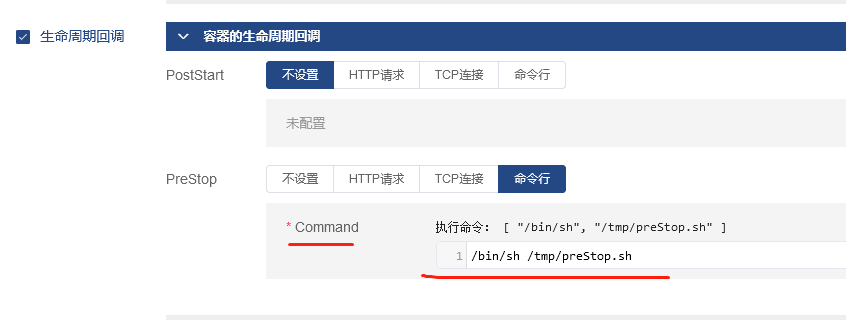
然后调整应用的deployment的yaml文件,把优雅终止宽限期(terminationGracePeriod限定时间)由默认的30秒调整为60秒,确保这个时间大于sleep 45的时间。

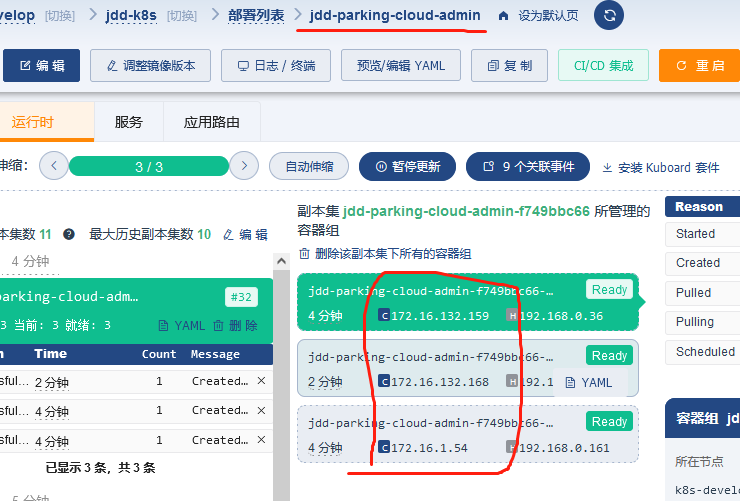
同时更新应用使用的docker镜像,待镜像启动后,增加副本数,由1增加到3,同时观察nacos中注册的应用数,确认显示有3个。
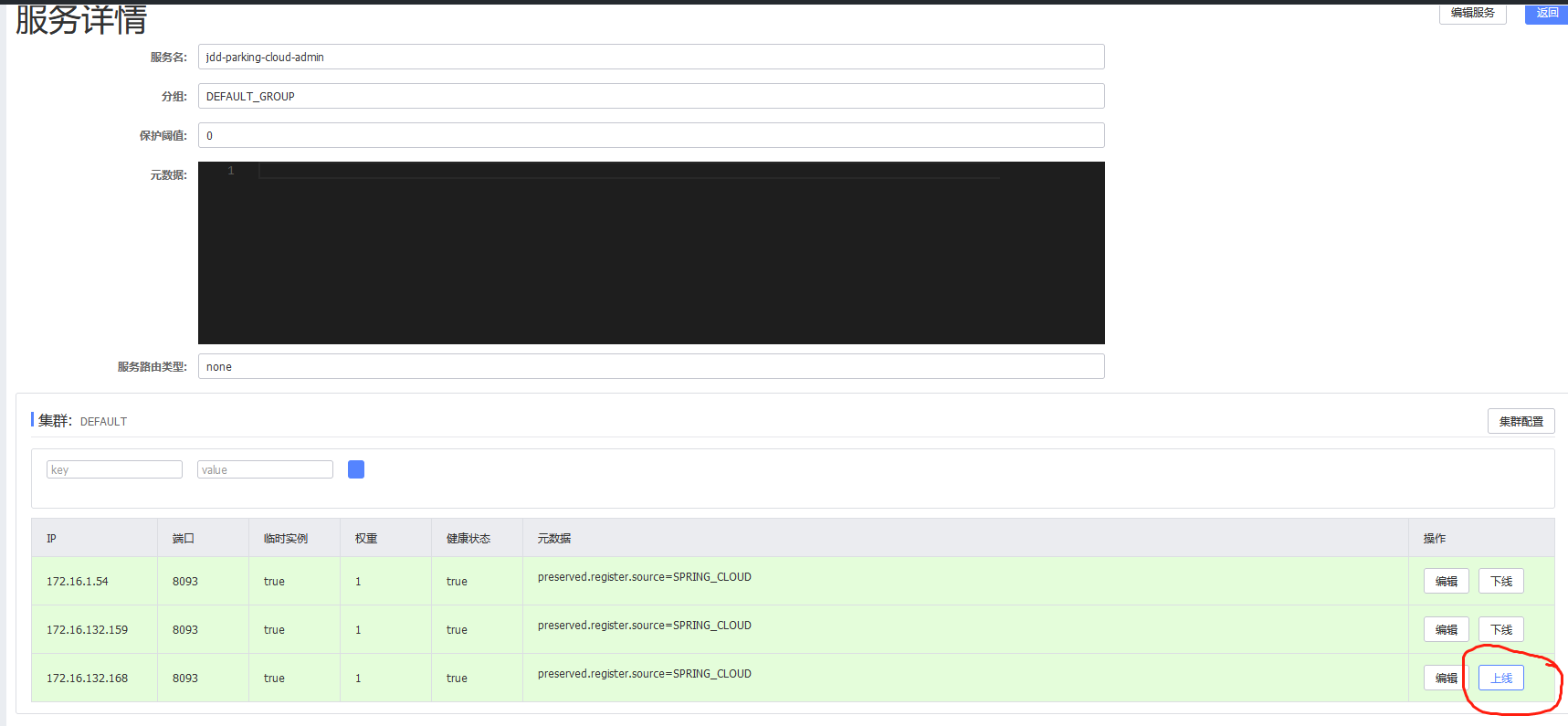
然后缩减一个副本数,副本数由3变成2,注意观察nacos中的应用是否有一个ip状态的变成"上线"(显示这个表示应用是下线状态),等待30秒后就看不到这个ip应用了。
然后观察k8s中pod的消失,等了60秒后才开始取消一个pod,最后查看事件events,发现并没有FailedPreStopHook,这是正常的,因为只有报错的情况下才会出现FailedPreStopHook,正常情况下不会出现这个。
Hook调用的日志没有暴露给Pod的Event,所以只能到通过describe命令来获取,如果是正常的操作是不会有event,如果有错误可以看到FailedPostStartHook和FailedPreStopHook这种event。并且如果Hook调用出现错误,则Pod状态不会是Running
总结
1.pod灭亡有个优雅终止宽限期(terminationGracePeriod限定时间),默认是30秒,nacos中应用超过30秒则摘除,主要围绕这俩时间来进行处理
2.项目中新增一个preStop.sh脚本,并添加到Dockerfile文件中,确保构造的镜像中有这个sh文件
脚本内容是应用从nacos下面的命令,以及sleep时间,这个时间需要超过nacos默认的30秒 (pod镜像中确保有curl命令)
3.k8s中增加sh脚本中使用到的环境变量,以便pod中sh脚本可以从pod环境中获取这些变量的值
4.k8s中设置设置PreStop,使用命令行的方式执行如上的sh脚本
5.nacos中验证,事件events中验证










进一步升级考虑
1.每个应用使用的端口号不一样,sh脚本内容在不同的项目中还得手动修改端口号,比较麻烦,可以把这个端口号也给做成变量的形式来使用,k8s中给这个端口设置一个环境变量


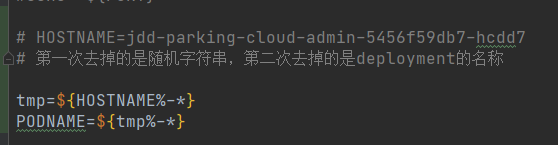
2.k8s中设置的环境变量中有个应用名称,pod本身的环境变量中有个metadata.name,是pod的名称,跟应用名称本身相比后面多了一些随机字符串,另外pod本身存在的环境变量HOSTNAME的值跟metadata.name的值一样,可以在sh脚本中获取HOSTNAME的值,然后截取前面的字符串从而获得应用名称,这样就不用在k8s中给应用名称设置一个新的环境变量了。


# HOSTNAME=jdd-parking-cloud-admin-5456f59db7-hcdd7
# 第一次去掉的是随机字符串,第二次去掉的是deployment的名称
tmp=${HOSTNAME%-*}
PODNAME=${tmp%-*}