一、离线 vs 实时流框架
用spark数据清洗的过程见:日志分析 https://www.cnblogs.com/sabertobih/p/14070357.html
实时流和离线的区别在于数据处理之间的时间差,而不取决于工具。所以kafka,sparkstreaming亦可用于离线批处理。
离线训练模型:多久根据需求决定,每一次模型都从头建立
离线预测模型:spark.sql用hive建dm_final表 -> spark ml
实时预测模型:kafka中建立dm_final表 -> spark ml
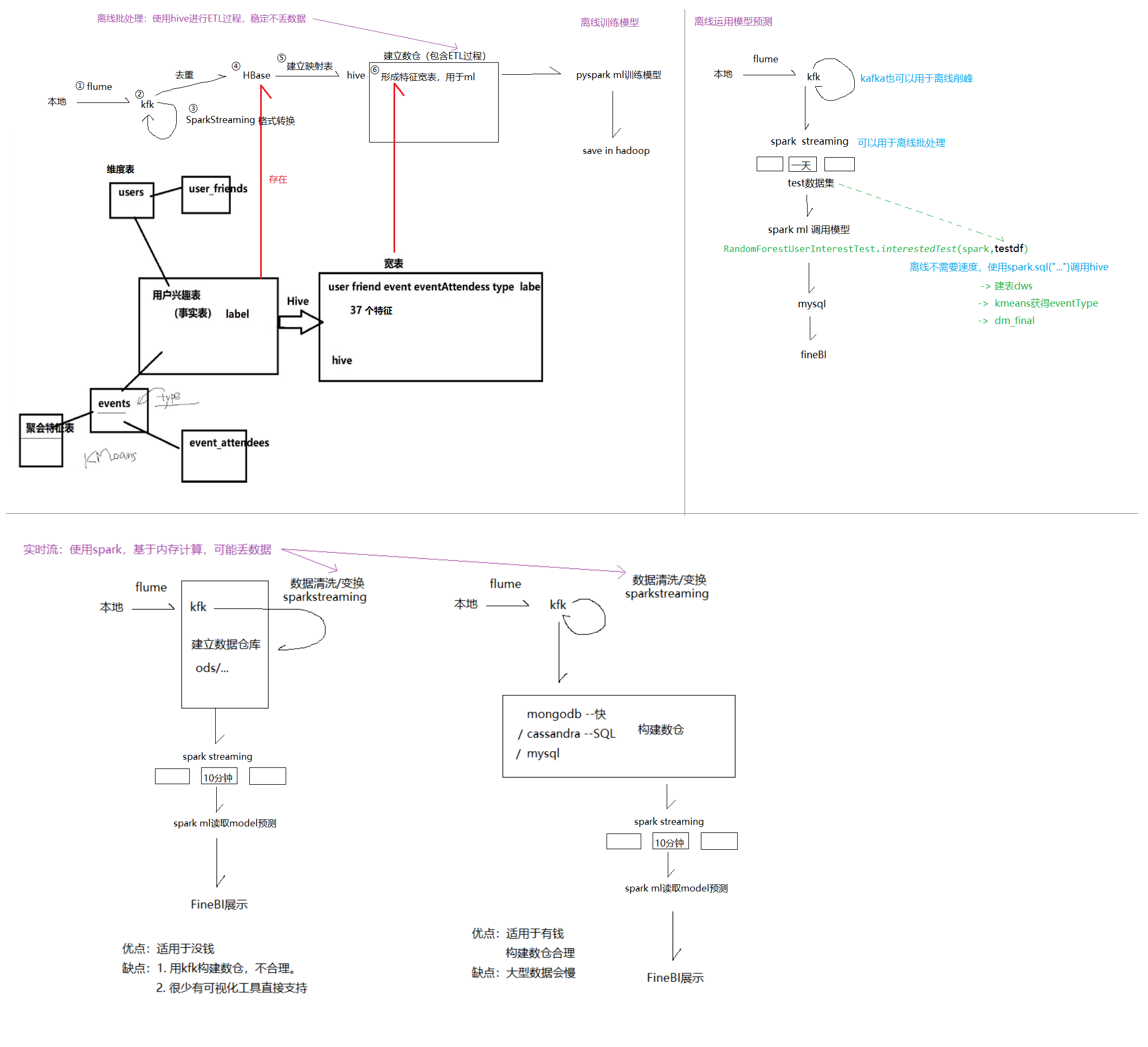
二、离线(本项目)处理思路
(一)构建ML模型

① flume
数据采集,实时监控新增数据,传输到kfk (见:https://www.cnblogs.com/sabertobih/p/14115501.html)
② kafka
削峰,实时数据监控命令:https://www.cnblogs.com/sabertobih/p/14024011.html
③ kafka-> sparkstreaming -> kafka
格式转换,见第五条:https://www.cnblogs.com/sabertobih/p/14136154.html
④ kafka-> HBase
由于Rowkey唯一,重复的Rowkey自动覆盖,可以完成去重
见第六条:https://www.cnblogs.com/sabertobih/p/14136154.html
⑤ HBase-> hive
建立外部映射表(数据存放在hdfs上,hive用于大批数据的复杂查询,hbase用于数据的有序映射)
create database if not exists events_db SET hivevar:db=events_db use ${db}; create external table ${db}.users( userid string, birthday string, gender string, locale string, location string, timezone string, joinedAt string ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,profile:birthday,profile:gender,region:locale,region:location,region:timezone,registration:joinedAt') tblproperties('hbase.table.name'='event_db:users') ---userfriends create external table event_db.userfriends( ukey string, userid string, friendid string ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,uf:userid,uf:friendid') tblproperties('hbase.table.name'='event_db:user_friends') ---events_db create external table event_db.events( eventid string, startTime string, city string, dstate string, zip string, country string, lat string, lng string, userId string, features string ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,schedule:startTime,location:city,location:state,location:zip,location:country,location:lat,location:lng,creator:userId,remark:features') tblproperties('hbase.table.name'='event_db:events') ---eventAttendees create external table event_db.eventAttendees( ekey string, eventId string, userId string, status string ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,euat:eventId,euat:userId,euat:status') tblproperties('hbase.table.name'='event_db:event_attendees') ---train create external table event_db.train( tkey string, userId string, eventId string, invited string, etimestamp string, interested string, notinterested string ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,eu:userId,eu:eventId,eu:invitedId,eu:timestamp,eu:interested,eu:notinterested') tblproperties('hbase.table.name'='event_db:train') ---test create external table event_db.test( tkey string, tuser string, event string, invited string, ttimestamp string ) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties('hbase.columns.mapping'=':key,eu:user,eu:event,eu:invited,eu:timestamp') tblproperties('hbase.table.name'='event_db:test')
⑥ hive中构建数仓
(6-1) ods层:数据存在hdfs中的内部表
1. 以ORC格式,查询速度快(详见:https://www.jianshu.com/p/91f793a1bdb3)
2. 顺带清洗工作
create table ${db}.users stored as ORC AS SELECT * from ${db}.hb_users drop database if exists ods_events cascade; create database ods_events; use ods_events; create table ods_events.ods_users stored as ORC as select * from event_db.users; create table ods_events.ods_eventsTable stored as ORC as select * from event_db.events; create table ods_events.ods_eventAttendees stored as ORC as select * from event_db.eventAttendees; create table ods_events.ods_userfriends stored as ORC as select * from event_db.userfriends; create table ods_events.ods_train stored as ORC as select * from event_db.train; create table ods_events.ods_test stored as ORC as select * from event_db.test; create table ods_events.ods_locale( localeid string, locale string ) row format delimited fields terminated by ' ' location 'hdfs://192.168.56.111:9000/party/data1/locale';
(6-2) dwd层:数据归一化
比如统一 “男” 和 “女” 为数字,把null值替换成平均值等数据预处理工作
//数据归一化 drop database if exists dwd_events; create database dwd_events; use dwd_events; //birthyear空赋值 create table dwd_users as select userid,locale,location, case when cast(birthday as int) is null then avg_year else birthday end as birthyear, case gender when 'male' then -1 when 'female' then 1 else 0 end as gender, case when cast(timezone as int) is null then avg_timezone else timezone end as timezone, case when trim(joinedat)='' or lower(joinedat)='none' then avg_member else unix_timestamp(translate(joinedat,'TZ',' ')) end as members from (select * from ods_events.ods_users cross join ( select floor(avg(cast(birthday as int))) avg_year, floor(avg(cast(timezone as int))) avg_timezone, floor(avg(unix_timestamp(translate(joinedat,'TZ',' ')))) avg_member from ods_events.ods_users )tmp )a; create table dwd_events.dwd_events as select eventid,unix_timestamp(translate(starttime,'TZ',' '))starttime, city,country,dstate as province, case when cast(lat as float) is null then avg_lat else lat end lat, case when cast(lng as float) is null then avg_lng else lng end lng, userid,features from ods_events.ods_eventsTable cross join (select round(avg(cast(lat as float)),3)avg_lat, round(avg(cast(lng as float)),3)avg_lng from ods_events.ods_eventsTable )tmp; create table dwd_events.dwd_eventAttendees as select * from ods_events.ods_eventattendees; create table dwd_events.dwd_usersFriends as select * from ods_events.ods_userfriends; create table dwd_events.dwd_train as select tkey trid,userid,eventid,invited,etimestamp ttime,interested label from ods_events.ods_train; create table dwd_events.dwd_locale as select * from ods_events.ods_locale;
(6-3)dws层:轻聚合维度表
聚合思路:
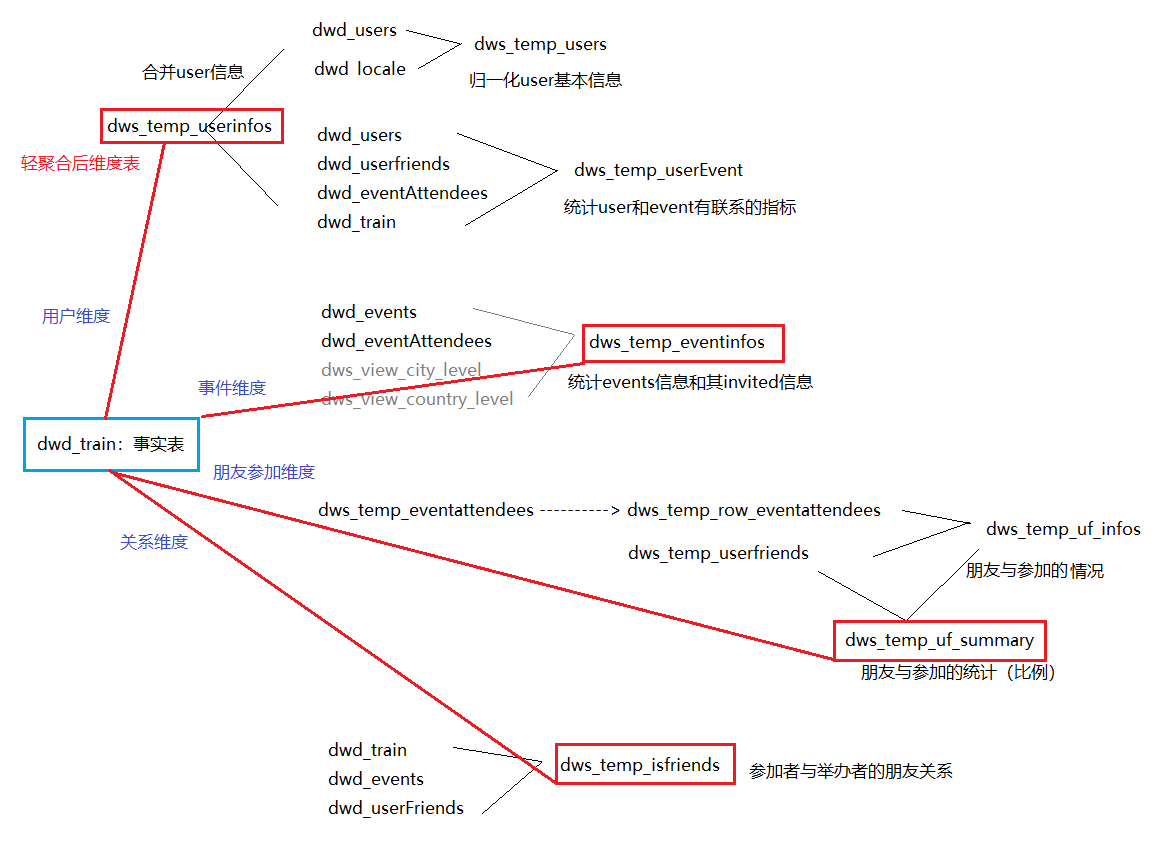
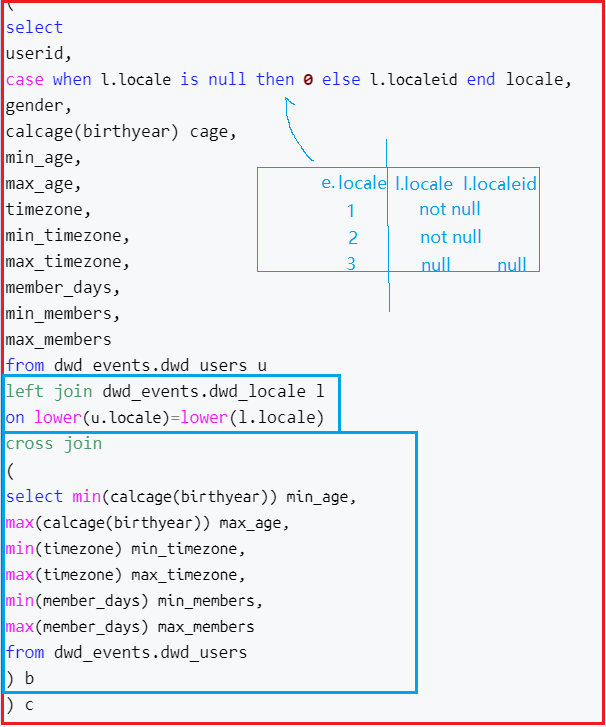
drop database if exists dws_events; create database dws_events; use dws_events; create temporary macro maxandmin(cdata int ,maxdata int,mindata int) (cdata-mindata)/(maxdata-mindata); create temporary macro calcage(y int) year(current_date())-y; -- ===================dws_temp_users================ create table dws_events.dws_temp_users as select userid, locale, gender,
location, maxandmin(cage,max_age,min_age) age, maxandmin(timezone,max_timezone,min_timezone) timezone, maxandmin(members,max_members,min_members) members from ( select userid, case when l.locale is null then 0 else l.localeid end locale, gender,location calcage(birthyear) cage, min_age, max_age, timezone, min_timezone, max_timezone, members, min_members, max_members from dwd_events.dwd_users u left join dwd_events.dwd_locale l on lower(u.locale)=lower(l.locale) cross join ( select min(calcage(birthyear)) min_age, max(calcage(birthyear)) max_age, min(timezone) min_timezone, max(timezone) max_timezone, min(members) min_members, max(members) max_members from dwd_events.dwd_users ) b ) c -- ===================dws_temp_userEvent================ create table dws_events.dws_temp_userEvent as select u.userid, case when uf.friendnum is null then 0 else uf.friendnum end friendnum, case when invite_event_count is null then 0 else invite_event_count end invite_event_count, case when attended_count is null then 0 else attended_count end attended_count, case when not_attended_count is null then 0 else not_attended_count end not_attended_count, case when maybe_attended_count is null then 0 else maybe_attended_count end maybe_attended_count, case when joinnum is null then 0 else joinnum end event_count from dwd_events.dwd_users u left join (select userid,count(friendid) friendnum from dwd_events.dwd_usersFriends group by userid) uf on u.userid=uf.userid left join (select userid, sum(case when status='invited' then 1 else 0 end) as invite_event_count, sum(case when status='yes' then 1 else 0 end) as attended_count, sum(case when status='no' then 1 else 0 end) as not_attended_count, sum(case when status='maybe' then 1 else 0 end) as maybe_attended_count from dwd_events.dwd_eventAttendees group by userid ) ea on u.userid=ea.userid left join (select userid, count(eventid) joinnum from dwd_events.dwd_train group by userid) dt on u.userid=dt.userid;
为什么使用left join?
—— 因为dws层需要以user总表中的userid为主表,其他表为辅表 => 聚合维度表
最后dm层还是以事实表中的id为准,使用inner join
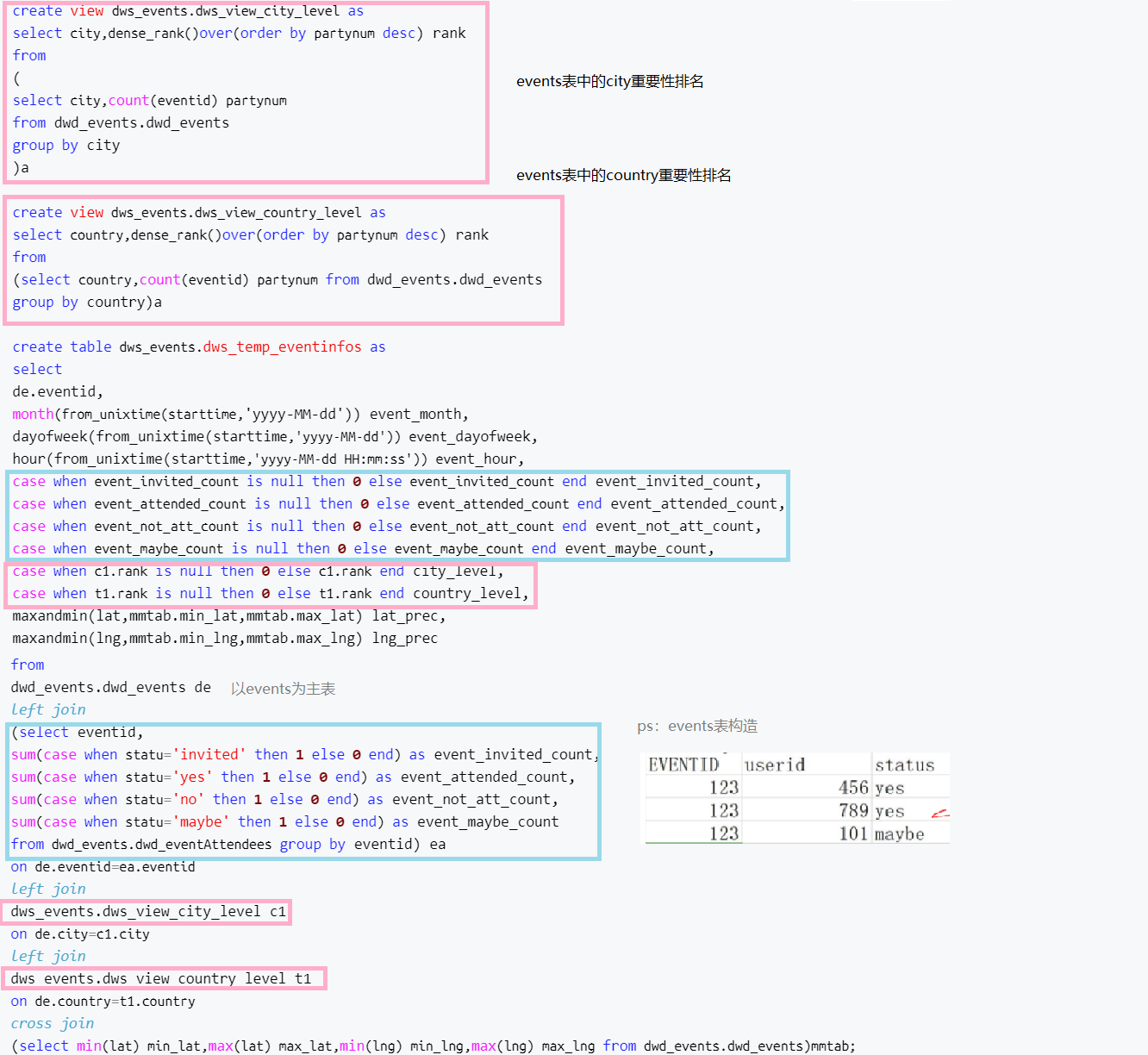
-- ===================合并dws_temp_userinfos================ create table dws_events.dws_temp_userinfos as select du.userid,du.locale,du.gender,du.age,du.timezone,du.members,ue.friendnum, ue.invite_event_count,ue.attended_count,ue.not_attended_count,ue.maybe_attended_count,ue.event_count from dws_events.dws_temp_users du inner join dws_events.dws_temp_userEvent ue on du.userid=ue.userid; -- ===================视图dws_view_city_level================ create view dws_events.dws_view_city_level as select city,dense_rank()over(order by partynum desc) rank from ( select city,count(eventid) partynum from dwd_events.dwd_events group by city )a -- ===================视图dws_view_country_level================ create view dws_events.dws_view_country_level as select country,dense_rank()over(order by partynum desc) rank from (select country,count(eventid) partynum from dwd_events.dwd_events group by country)a -- ===================dws_temp_eventinfos================ create table dws_events.dws_temp_eventinfos as select de.eventid, de.userid as creator, de.starttime, de.city, de.province, de.country, month(from_unixtime(starttime,'yyyy-MM-dd')) event_month, dayofweek(from_unixtime(starttime,'yyyy-MM-dd')) event_dayofweek, hour(from_unixtime(starttime,'yyyy-MM-dd HH:mm:ss')) event_hour, case when event_invited_count is null then 0 else event_invited_count end event_invited_count, case when event_attended_count is null then 0 else event_attended_count end event_attended_count, case when event_not_att_count is null then 0 else event_not_att_count end event_not_att_count, case when event_maybe_count is null then 0 else event_maybe_count end event_maybe_count, case when c1.rank is null then 0 else c1.rank end city_level, case when t1.rank is null then 0 else t1.rank end country_level, maxandmin(lat,mmtab.min_lat,mmtab.max_lat) lat_prec, maxandmin(lng,mmtab.min_lng,mmtab.max_lng) lng_prec, features from dwd_events.dwd_events de left join (select eventid, sum(case when status='invited' then 1 else 0 end) as event_invited_count, sum(case when status='yes' then 1 else 0 end) as event_attended_count, sum(case when status='no' then 1 else 0 end) as event_not_att_count, sum(case when status='maybe' then 1 else 0 end) as event_maybe_count from dwd_events.dwd_eventAttendees group by eventid) ea on de.eventid=ea.eventid left join dws_events.dws_view_city_level c1 on de.city=c1.city left join dws_events.dws_view_country_level t1 on de.country=t1.country cross join (select min(lat) min_lat,max(lat) max_lat,min(lng) min_lng,max(lng) max_lng from dwd_events.dwd_events)mmtab;
-- ===================dws_temp_train================ create table dws_events.dws_temp_train as select * from dwd_events.dwd_train; -- ===================dws_temp_userfriends================ create table dws_events.dws_temp_userfriends as select * from dwd_events.dwd_usersFriends; -- ===================dws_temp_eventattendees================ create table dws_events.dws_temp_eventattendees as select * from dwd_events.dwd_eventattendees; -- 某个用户对某次会议是否收到邀请以及回复 -- ===================dws_temp_row_eventattendees================ create table dws_events.dws_temp_row_eventattendees as select userid, eventid, max(case when status='invited' then 1 else 0 end) invited, max(case when status='yes' then 1 else 0 end) yes, max(case when status='maybe' then 1 else 0 end) maybe, max(case when status='no' then 1 else 0 end) no from dws_events.dws_temp_eventattendees group by userid,eventid -- 某人的某个朋友参加某次会议是否获得邀请以及这个朋友的回复 -- ===================dws_temp_uf_infos================ create table dws_events.dws_temp_uf_infos as select uf.userid, uf.friendid, case when ea.eventid is null then 0 else ea.eventid end eventid, case when ea.invited is null then 0 else ea.invited end invited, case when ea.yes is null then 0 else ea.yes end yes, case when ea.maybe is null then 0 else ea.maybe end maybe, case when ea.no is null then 0 else ea.no end no from dws_events.dws_temp_userfriends uf left join dws_events.dws_temp_row_eventattendees ea on uf.friendid=ea.userid
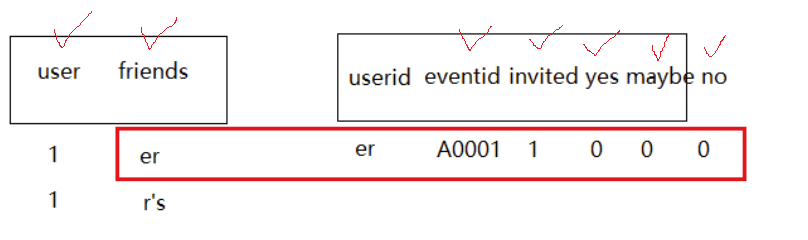
-- ===================dws_temp_uf_summary================ create table dws_events.dws_temp_uf_summary as select a.*, uf_invited_count/b.friendnum as uf_invited_prec, uf_attended_count/b.friendnum as uf_attended_prec, uf_not_attended_count/b.friendnum as uf_not_attended_prec, uf_maybe_count/b.friendnum as uf_maybe_prec from (select ufi.userid, ufi.eventid, sum(ufi.invited) as uf_invited_count, sum(ufi.yes) as uf_attended_count, sum(ufi.no) as uf_not_attended_count, sum(ufi.maybe) as uf_maybe_count from dws_events.dws_temp_uf_infos ufi group by ufi.userid,ufi.eventid ) a inner join (select userid, count(friendid) friendnum from dws_events.dws_temp_userfriends uf group by userid ) b on a.userid=b.userid
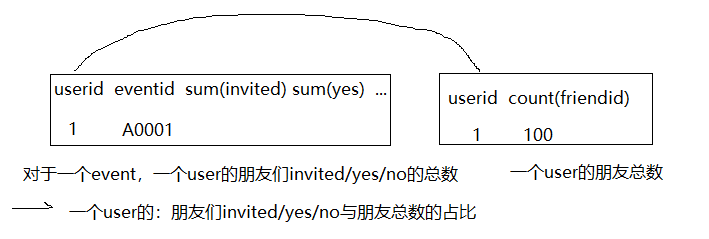
-- 训练集中的某人参加的某个会议是否是这个会议主持人的朋友
-- ==============dws_temp_isfriends==========
create table dws_events.dws_temp_isfriends stored as orc as with t1 as(select tr.userid,es.eventid,es.userid as creator from dwd_events.dwd_train tr inner join dwd_events.dwd_events es on tr.eventid=es.eventid), t2 as(select t.userid,t.eventid, case when uf.friendid is null then 0 else 1 end isfriend from t1 t left join dwd_events.dwd_usersFriends uf on t.userid=uf.userid and t.creator=uf.friendid), t3 as (select t.userid,t.eventid, case when uf.friendid is null then 0 else 1 end isfriend from t1 t left join dwd_events.dwd_usersFriends uf on t.userid=uf.friendid and t.creator=uf.userid) select t2.userid,t2.eventid, case when t2.isfriend=1 or t3.isfriend=1 then 1 else 0 end isfriend from t2 inner join t3 on t2.userid=t3.userid and t2.eventid=t3.eventid

(6-4)dm层:宽表
- dm指标:
user_interested ----label user_id ----no event_id ----no locale -----1~x gender -----1,0,1 age -----0~1 timezone -----0~x member_days -----0~1 friend_count -----0~1 invite_days -----0~1 event_count -----0~1 invited_event_count(被邀请) -----0~1 attended_count(答应参加) -----0~1 not_attended_count(拒绝参加) -----0~1 maybe_attended_count(可能参加) -----0~1 user_invited(本次会议是否被邀请) -----0,1 uf_invited_count(多少朋友被邀请) -----0~1 uf_attended_count(答应去的朋友数) -----0~1 uf_notattended_count(不去的) -----0~1 uf_maybe_count(可能) -----0~1 uf_invited_prec(朋友被邀请的%) -----0~1 uf_attended_prec(朋友答应%) -----0~1 uf_not_attended_prec(不答应%) -----0~1 uf_maybe_prec(可能%) -----0~1 ahead_days(活动和邀请时间差) -----0~1 event_month(活动月份) -----0~12 event_dayofweek(活动星期) -----0~52 event_hour(活动时间) -----0~24 event_invited_count(活动邀请人数) -----0~1 event_attended_count(答应人数) -----0~1 event_not_att_count(不答应人数) -----0~1 event_maybe_count(活动答应可能) -----0~1 city_level(城市等级) -----0~x country(国家等级) -----0~x lat_prec(经度%) -----0~1 lng_prec(纬度%) -----0~1 creator_is_friend -----0,1 location——similar(人和会议是否同城) -----0,1 event_type(活动分类) -----0~x
drop database if exists dm_events; create database dm_events; use dm_events;
-- ==================locationSimilar是否同城================= create temporary macro locationSimilar(location String,city String,province String,country String) case when instr(lower(location),lower(city))>0 or instr(lower(location),lower(province))>0 or instr(lower(location),lower(country))>0 then 1 else 0 end -- ===================dm_usereventfinal================ drop table if exists dm_events.dm_usereventfinal; create table dm_events.dm_usereventfinal as select tr.label, tr.userid, tr.eventid, us.locale, us.gender, us.age, us.timezone, us.members as member_days, floor((ei.starttime-unix_timestamp(ttime))/3600/24) invite_days, us.friendnum as friend_count, us.invite_event_count, us.attended_count, us.not_attended_count, us.maybe_attended_count, us.event_count, tr.invited, ufe.uf_invited_count, ufe.uf_attended_count, ufe.uf_not_attended_count, ufe.uf_maybe_count, ufe.uf_invited_prec, ufe.uf_attended_prec, ufe.uf_not_attended_prec, ufe.uf_maybe_prec, ei.event_month, ei.event_dayofweek, ei.event_hour, ei.event_invited_count, ei.event_attended_count, ei.event_not_att_count, ei.event_maybe_count, ei.city_level, ei.country_level, ei.lat_prec, ei.lng_prec, ifr.isfriend as creator_is_friend, locationSimilar(us.locale,ei.city,ei.province,ei.country) as location_similar, ei.features from dws_events.dws_temp_train tr inner join dws_events.dws_temp_userinfos us on tr.userid=us.userid inner join dws_events.dws_temp_eventinfos ei on tr.eventid=ei.eventid inner join dws_events.dws_temp_uf_summary ufe on tr.userid=ufe.userid and tr.eventid=ufe.eventid inner join dws_events.dws_temp_isfriends ifr on tr.userid=ifr.userid and tr.eventid=ifr.eventid;
⑦ 训练kmeans模型
使用dm_usereventfinal中的features(来源于event数据)训练kmeans模型(给events分类),输出新表dm_eventtype
链接:https://www.cnblogs.com/sabertobih/p/14183984.html
连接dm_usereventfinal和dm_eventtype生成新表dm_final
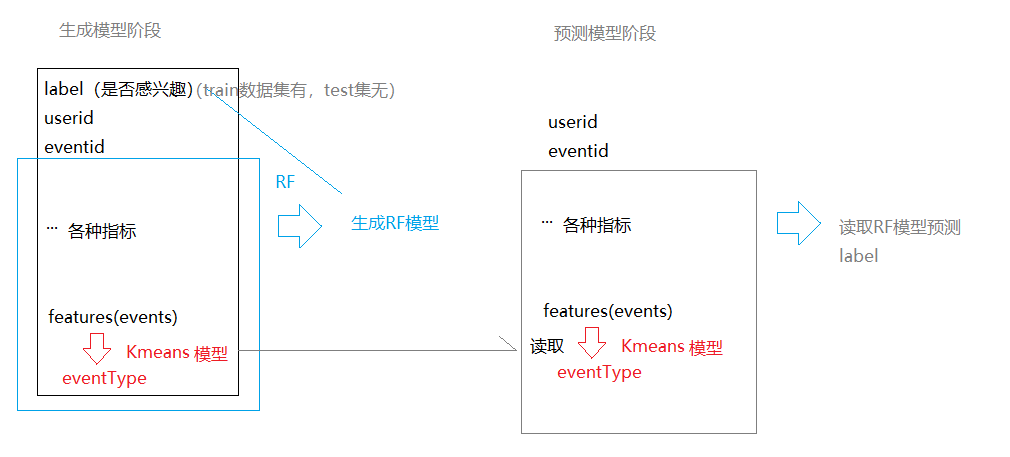
create table dm_final as select a.label,a.userid,a.eventid,a.locale,a.gender,a.age,a.timezone,a.member_days,a.invite_days,a.friend_count,a.invite_event_count,a.attended_count,a.not_attended_count, a.maybe_attended_count,a.event_count,a.invited,a.uf_invited_count,a.uf_attended_count,a.uf_not_attended_count, a.uf_maybe_count,a.uf_invited_prec,a.uf_attended_prec, a.uf_not_attended_prec,a.uf_maybe_prec,a.event_month,a.event_dayofweek, a.event_hour,a.event_invited_count,a.event_attended_count, a.event_not_att_count,a.event_maybe_count, a.city_level,a.country_level,a.lat_prec,a.lng_prec,a.creator_is_friend ,a.location_similar,
b.prediction as eventtype from dm_events.dm_usereventfinal a inner join dm_events.dm_eventtype b on a.eventid = b.eventid;
⑧ 使用 dm_final训练构建RF模型,预测分类
链接:https://www.cnblogs.com/sabertobih/p/14183984.html
(二)使用模型预测test数据集

① [scala] 使用spark.sql操作hive,指标保持和训练用的一致
首先保证连的上去,见:https://www.cnblogs.com/sabertobih/p/13772985.html
相同的分层数据处理,最终都要获得相同的计算指标表
/** * 判断用户和会议是否距离比较近 */ val locationSimilar=udf( (location:String,city:String,province:String,country:String)=> { if (city.toLowerCase().indexOf(location.toLowerCase()) > -1 || province.toLowerCase().indexOf(location.toLowerCase()) > -1 || country.toLowerCase().indexOf(location.toLowerCase()) > -1) { 1 } else { 0 } } ) /** * 最大最小值 归一化方法
* // 为什么是Double? 因为ml之前需要数据预处理,早晚都要变成DoubleType */ val maxandmin = udf{ (cdata:Double,maxdata:Double,mindata:Double)=>{ (cdata-mindata)/(maxdata-mindata) } } /** * 计算用户年龄 */ val calcage = udf{ (y:Double) =>{ Calendar.getInstance().get(Calendar.YEAR)-y } } /** * 读取所有的dwd层的数据 * @param spark * @param tableName * @return */ def readHiveTable(spark:SparkSession,tableName:String) ={ spark.sql(s"select * from $tableName") } /** * 读取测试集文件 * @param spark * @param path * @return */ // 用来干嘛?变成testdf供使用 def readTestData(spark:SparkSession,path:String)={ spark.read.format("csv").option("header","true").load(path) .withColumnRenamed("user","userid") .withColumnRenamed("event","eventid") .withColumnRenamed("timestamp","ttime") } /** * 获取用户基本信息 * @param spark * @return */ // 对应dws_temp_users def getUserbaseinfo(spark:SparkSession)={ val sql = s"""select |userid,locale,gender, |location, |maxandmin(cage,max_age,min_age) age, |maxandmin(timezone,max_timezone,min_timezone) timezone, |maxandmin(members,max_members,min_members) members |from |(select userid, |case when l.locale is null then 0 else l.localeid end locale, |gender,location, |calcage(birthyear) cage,min_age,max_age, |timezone,min_timezone,max_timezone, |members,min_members,max_members |from dwd_events.dwd_users u |left join dwd_events.dwd_locale l |on lower(u.locale)=lower(l.locale) |cross join (select min(calcage(birthyear)) min_age |,max(calcage(birthyear)) max_age,min(timezone) min_timezone, |max(timezone) max_timezone, min(members) min_members,max(members) max_members |from dwd_events.dwd_users) b ) c""".stripMargin spark.sql(sql) } /** * 获取用户反馈信息及统计 * @param spark * @param test * @return */ // dws_temp_userEvent def getUserCall(spark:SparkSession,test:DataFrame)= { test.createOrReplaceTempView("view_testdata") val sql="""select |u.userid, |case when uf.friendnum is null then 0 else uf.friendnum end friendnum, |case when invited_event_count is null then 0 else invited_event_count end invited_event_count, |case when attended_count is null then 0 else attended_count end attended_count, |case when not_attended_count is null then 0 else not_attended_count end not_attended_count, |case when maybe_attended_count is null then 0 else maybe_attended_count end maybe_attended_count, |case when joinnum is null then 0 else joinnum end event_count |from |dwd_events.dwd_users u |left join |(select userid,count(friendid) friendnum from dwd_events.dwd_userFriends group by userid) uf |on u.userid=uf.userid |left join (select userid, |sum(case when statu='invited' then 1 else 0 end) as invited_event_count, |sum(case when statu='yes' then 1 else 0 end) as attended_count, |sum(case when statu='no' then 1 else 0 end) as not_attended_count, |sum(case when statu='maybe' then 1 else 0 end) as maybe_attended_count |from dwd_events.dwd_eventAttendees group by userid ) ea on u.userid=ea.userid |left join |(select userid, count(eventid) joinnum |from view_testdata group by userid) dt |on u.userid=dt.userid""".stripMargin spark.sql(sql) } /** * 获取完整的用户信息数据集 * @param spark * @param tdata */ // 合并dws_temp_userinfos def getUserinfos(spark: SparkSession,tdata:DataFrame)={ //获取用户的基本信息 val bdf = getUserbaseinfo(spark) //获取用户的反馈信息 val cdf = getUserCall(spark,tdata) //将用户基本信息和用户反馈信息合并 bdf.join(cdf,Seq("userid"),"inner") } /** * 获取城市等级 * @param spark * @return */ def getCityLevel(spark:SparkSession)={ val sql=""" |select |city,dense_rank() over(order by partynum desc) rank |from |(select city,count(eventid) partynum |from dwd_events.dwd_events |group by city ) a""".stripMargin spark.sql(sql) } /** * 获取国家等级 * @param spark * @return */ def getCountryLevel(spark:SparkSession)={ val sql="""select country,dense_rank() over(order by partynum desc) rank from |(select country,count(eventid) partynum from dwd_events.dwd_events group by country ) a""".stripMargin spark.sql(sql) } def getEventinfo(spark: SparkSession,cityLevel:DataFrame,countryLevel:DataFrame)={ cityLevel.createOrReplaceTempView("city_level") countryLevel.createOrReplaceTempView("country_level") val sql=s"""select |de.eventid, |de.userid as creator, |de.starttime,de.city,de.province,de.country, |month(from_unixtime(starttime,'yyyy-MM-dd')) event_month, |dayofweek(from_unixtime(starttime,'yyyy-MM-dd')) event_dayofweek, |hour(from_unixtime(starttime,'yyyy-MM-dd HH:mm:ss')) event_hour, |case when event_invited_count is null then 0 else event_invited_count end event_invited_count, |case when event_attended_count is null then 0 else event_attended_count end event_attended_count, |case when event_not_att_count is null then 0 else event_not_att_count end event_not_att_count, |case when event_maybe_count is null then 0 else event_maybe_count end event_maybe_count, |case when cl.rank is null then 0 else cl.rank end city_level, |case when tl.rank is null then 0 else tl.rank end country_level, |maxandmin(lat,mmtab.max_lat,mmtab.min_lat) lat_prec, |maxandmin(lng,mmtab.max_lng,mmtab.min_lng) lng_prec, |de.features |from |dwd_events.dwd_events de left join |(select eventid, |sum(case when statu='invited' then 1 else 0 end) as event_invited_count, |sum(case when statu='yes' then 1 else 0 end) as event_attended_count, |sum(case when statu='no' then 1 else 0 end) as event_not_att_count, |sum(case when statu='maybe' then 1 else 0 end) as event_maybe_count |from dwd_events.dwd_eventAttendees group by eventid) ea |on de.eventid=ea.eventid left join |city_level cl on de.city = cl.city left join |country_level tl on de.country = tl.country cross join |(select min(lat) min_lat,max(lat) max_lat,min(lng) min_lng,max(lng) max_lng from dwd_events.dwd_events) mmtab""".stripMargin spark.sql(sql) } /** * 某个用户对某次会议的是否受到邀请以及回复 * @param spark * @return */ // dws_temp_row_eventattendees def getUserEventAttendees(spark:SparkSession)={ val sql="""select |userid,eventid, |max(case when statu='invited' then 1 else 0 end) invited, |max(case when statu='yes' then 1 else 0 end) yes, |max(case when statu='maybe' then 1 else 0 end) maybe, |max(case when statu='no' then 1 else 0 end) no |from |dwd_events.dwd_eventAttendees group by userid,eventid""".stripMargin spark.sql(sql) } /** * 某人的某个朋友参加某次会议是否获得邀请以及这个朋友的回复 * @param spark */ def getUserFriendEventAttendees(spark:SparkSession,uea:DataFrame)={ uea.createOrReplaceTempView("view_row_ea") val sql="""select |uf.userid, |uf.friendid, |case when ea.eventid is null then 0 else ea.eventid end eventid, |case when ea.invited is null then 0 else ea.invited end invited, |case when ea.yes is null then 0 else ea.yes end yes, |case when ea.maybe is null then 0 else ea.maybe end maybe, |case when ea.no is null then 0 else ea.no end no |from |dwd_events.dwd_userFriends uf left join view_row_ea ea on |uf.friendid = ea.userid""".stripMargin spark.sql(sql) } /** * 统计某人在某次会议上的朋友各种情况 * @param spark * @return */ // 所有传进来的都是dws层的 def getUserFriendinfoSummary(spark:SparkSession,ufcall:DataFrame)={ ufcall.createOrReplaceTempView("view_ufcall") val sql="""select a.*, |uf_invited_count/b.friendnum as uf_invited_prec, |uf_attended_count/b.friendnum as uf_attended_prec, |uf_not_attended_count/b.friendnum as uf_not_attended_prec, |uf_maybe_count/b.friendnum as uf_maybe_prec |from ( |select |ufi.userid,ufi.eventid, |sum(ufi.invited) as uf_invited_count, |sum(ufi.yes) as uf_attended_count, |sum(ufi.no) as uf_not_attended_count, |sum(ufi.maybe) as uf_maybe_count |from |view_ufcall ufi group by ufi.userid,ufi.eventid) a |inner join ( |select userid,count(friendid) friendnum |from dwd_events.dwd_userFriends |group by userid |) b on a.userid=b.userid""".stripMargin spark.sql(sql) } def getCreatorIsFriend(spark:SparkSession,testdata:DataFrame) ={ testdata.createOrReplaceTempView("view_testdata") val sql="""with |t1 as (select tr.userid,es.eventid,es.userid as creator |from view_testdata tr |inner join dwd_events.dwd_events es on tr.eventid=es.eventid ), |t2 as (select t.userid,t.eventid, |case when uf.friendid is null then 0 else 1 end isfriend |from t1 t left join dwd_events.dwd_userFriends uf on t.userid=uf.userid and t.creator=uf.friendid ), |t3 as (select t.userid,t.eventid, |case when uf.friendid is null then 0 else 1 end isfriend |from t1 t left join dwd_events.dwd_userFriends uf on t.userid=uf.friendid and t.creator=uf.userid) |select t2.userid,t2.eventid, |case when t2.isfriend=1 or t3.isfriend=1 then 1 else 0 end isfriend |from t2 inner join t3 on t2.userid=t3.userid and t2.eventid=t3.eventid""".stripMargin spark.sql(sql) } def getDmUserEventData(spark: SparkSession,path:String)={ println("获取test数据集........") //获取test数据集 val testdf = readTestData(spark,path).cache() println("获取用户信息.........") //获取用户信息 val userdf = getUserinfos(spark,testdf) println("获得城市等级.........") //获得城市等级 val city_level = getCityLevel(spark).cache() println("获得国家等级.........") //获得国家等级 val country_level = getCountryLevel(spark).cache() println("获取会议信息.........") //获取会议信息 val eventdf= getEventinfo(spark,city_level,country_level) println("某个用户对某次会议的是否受到邀请以及回复..........") //某个用户对某次会议的是否受到邀请以及回复 val uea = getUserEventAttendees(spark).cache() println("获取某用户朋友的回复信息..........") //获取某用户朋友的回复信息 val ufea = getUserFriendEventAttendees(spark,uea).cache() println("获取用户朋友统计信息............") //获取用户朋友统计信息 val ufsummarydf = getUserFriendinfoSummary(spark,ufea) println("获取用户是否是主持人的朋友信息..........") //获取用户是否是主持人的朋友信息 val isFriend = getCreatorIsFriend(spark,testdf).cache() println("将数据构建成测试数据集合..............") //将数据构建成测试数据集合 import spark.implicits._ testdf .join(userdf,Seq("userid"),"inner") .join(eventdf,Seq("eventid"),"inner") .join(ufsummarydf,Seq("userid","eventid"),"inner") .join(isFriend,Seq("userid","eventid"),"inner") .withColumnRenamed("members","member_days") .withColumn("invite_days" ,floor(($"starttime"-unix_timestamp($"ttime"))/3600/24)) .withColumnRenamed("isfriend","creator_is_friend") .withColumn("location_similar" ,locationSimilar($"location",$"city",$"province",$"country")) .drop("ttime", "location","creator", "starttime","city", "province","country") }
给test数据集的events分类(使用训练好的kmeans model)=> 获得dm_final
val spark = SparkSession.builder().master("local[*]").appName("test")
.config("hive.metastore.uris","thrift://192.168.16.150:9083")
.enableHiveSupport().getOrCreate()
//注册udf函数
spark.udf.register("locationSimilar",locationSimilar)
spark.udf.register("maxandmin",maxandmin)
spark.udf.register("calcage",calcage)
// //执行获得test指标数据集合,test来源是每一段sparkstreaming的RDD
val res = getDmUserEventData(spark,"e:/test.csv")
// //进行kmeans event分类
val eventType = KMeansEventTypeHandler.calcEventType(spark, res)
.withColumnRenamed("eventid","etid")
// //把event分类集合与test指标数据集合join
val finalRes = res.join(eventType, res("eventid")===eventType("etid"))
.drop("features","etid") // 如果不改名,就会把两个eventid都删掉
.withColumnRenamed("prediction", "eventType")
.distinct()
KmeansEventTypeHandler:
def calcEventType(spark:SparkSession,et:DataFrame)= { var tmp = et; if (et == null) { tmp = spark.sql("select * from dm_events.dm_usereventfinal") .select("eventid","features") }else{ tmp =tmp.select("eventid","features") } //将features列拆成c_* val fts = split(tmp("features"), ",") //准备一个c_0~c_100的数组 val cols = ArrayBuffer[String]() for(cl <- 0 to 100){ tmp = tmp.withColumn("c_"+cl,fts.getItem(cl).cast(DoubleType)) cols.append("c_"+cl) } tmp.drop("features") //将传入的数据集合进行整合为feature val assembler = new VectorAssembler().setInputCols(cols.toArray).setOutputCol("feature") val df = assembler.transform(tmp) //加载kmeans模型 val model = KMeansModel.load("d:/kmmodel2") //数据进行分类 model.transform(df).select("eventid","prediction") }
② 使用RF model => 预测label(if interested?)
val prediction = RandomForestUserInterestTest.interestedTest(spark,null) // 真实情况下应该传入原始test数据集的df
RandomForestUserInterestTest:
def interestedTest(spark:SparkSession,finalRes:DataFrame)={ var tmp = finalRes if(tmp == null){ tmp = spark.sql("select * from dm_events.dm_testdata").cache() } val column: Array[String] = tmp.columns val cls = column.map(f=>col(f).cast(DoubleType)) val tab = tmp.select(cls:_*) //去除userid和eventid val cs = column.filter(str=>if(str=="userid"||str=="eventid"){false}else{true}) val ass = new VectorAssembler().setInputCols(cs).setOutputCol("features") val cpres = ass.transform(tab) val model = RandomForestClassificationModel.load("d:/rfc") model.transform(cpres).select("userid","eventid","prediction") }
③ 预测结果放入mysql,与预测相关的维度表也入mysql(为了下一步的数据可视化)
//将数据预测存放到mysql数据库 MySqlWriter.writeData(prediction,"userinterested") //将于预测数据相关的维度信息也存放到mysql数据库 var users = spark.sql("select * from dwd_events.dwd_users") MySqlWriter.writeData(users,"users") var events = spark.sql("select * from dwd_events.dwd_events") MySqlWriter.writeData(events,"events") spark.stop()
Mysqlwriter:DataFrame写入mysql
object MySqlWriter { def writeData(df:DataFrame,tableName:String)={ val prop = new Properties() prop.put("driver","com.mysql.jdbc.Driver") prop.put("user","root") prop.put("password","ok") df.write.mode("overwrite") .jdbc("jdbc:mysql://192.168.16.150:3306/prediction",tableName,prop) } }