mpvue开发博客园小程序
Table of Contents
看到小程序这么火,我也忍不住要来尝试下小程序开发,毕竟这个和开发网站其实差别不大, 网站经验也攒了一些了,小程序应该不会太费劲。小程序比较依赖现代javascript技术, 我也正好学习下这样的开发流程。
在看了微信小程序开发资源汇总之后,确定用mpvue来打底,因为看到过别的网站用vue用的很爽, 所以这次放一起学了。
那么看看现在都需要些什么准备工作吧
- 微信小程序开发者帐号
- 小程序开发集成环境
- 随手查看小程序开发文档以及vue文档
- 安装node.js,npm
- git版本控制
现在看下当前电脑环境,linux,node.js 8.11.2,npm 6.1.0,开发者工具用的Linux微信web开发者工具, 编辑器是emacs+spacemacs,mpvue我用的是mpvue quickstart with mpvue-entry。
接下来就是正式开发的内容了
1 第一天
照例先做简单的需求分析
- 可以查看最新的博客列表
- 可以通过点击列表中的条目进入详情页
- 可以通过下拉刷新列表
- 可以在拉到底部后刷出新的条目
那么暂时就两个页面,一个显示列表,一个显示详情,列表中的数据从博客园的api里可以获得
1.1 博客园api
1.1.2 请求示例
1、博客文章最新10条: http://wcf.open.cnblogs.com/blog/sitehome/recent/10 (不使用)
首页文章分页接口:http://wcf.open.cnblogs.com/blog/sitehome/paged/2/10 (第2页, 每页10条)
2、博客文章内容:http://wcf.open.cnblogs.com/blog/post/body/2251556
博客评论内容: http://wcf.open.cnblogs.com/blog/post/2291554/comments/1/10
3、新闻最新10条:http://wcf.open.cnblogs.com/news/recent/10
新闻分页接口:http://wcf.open.cnblogs.com/news/recent/paged/1/10
4、新闻内容:http://wcf.open.cnblogs.com/news/item/121853 (实现方法: http://www.cnblogs.com/dudu/archive/2011/10/27/wcf_web_api.html)
5、新闻评论:http://wcf.open.cnblogs.com/news/item/123343/comments/1/10
6、个人博客:http://wcf.open.cnblogs.com/blog/u/dudu/posts/1/10
7、搜索博主:http://wcf.open.cnblogs.com/blog/bloggers/search?t=
1、推荐博客排名: http://wcf.open.cnblogs.com/blog/bloggers/recommend/1/10
2、48小时阅读排行: http://wcf.open.cnblogs.com/blog/48HoursTopViewPosts/20
3、10天内推荐排行: http://wcf.open.cnblogs.com/blog/TenDaysTopDiggPosts/20
4、推荐新闻:http://wcf.open.cnblogs.com/news/recommend/paged/1/10
1.1.3 返回格式
返回格式都为xml,只要能解析xml即可
1.2 列表页面
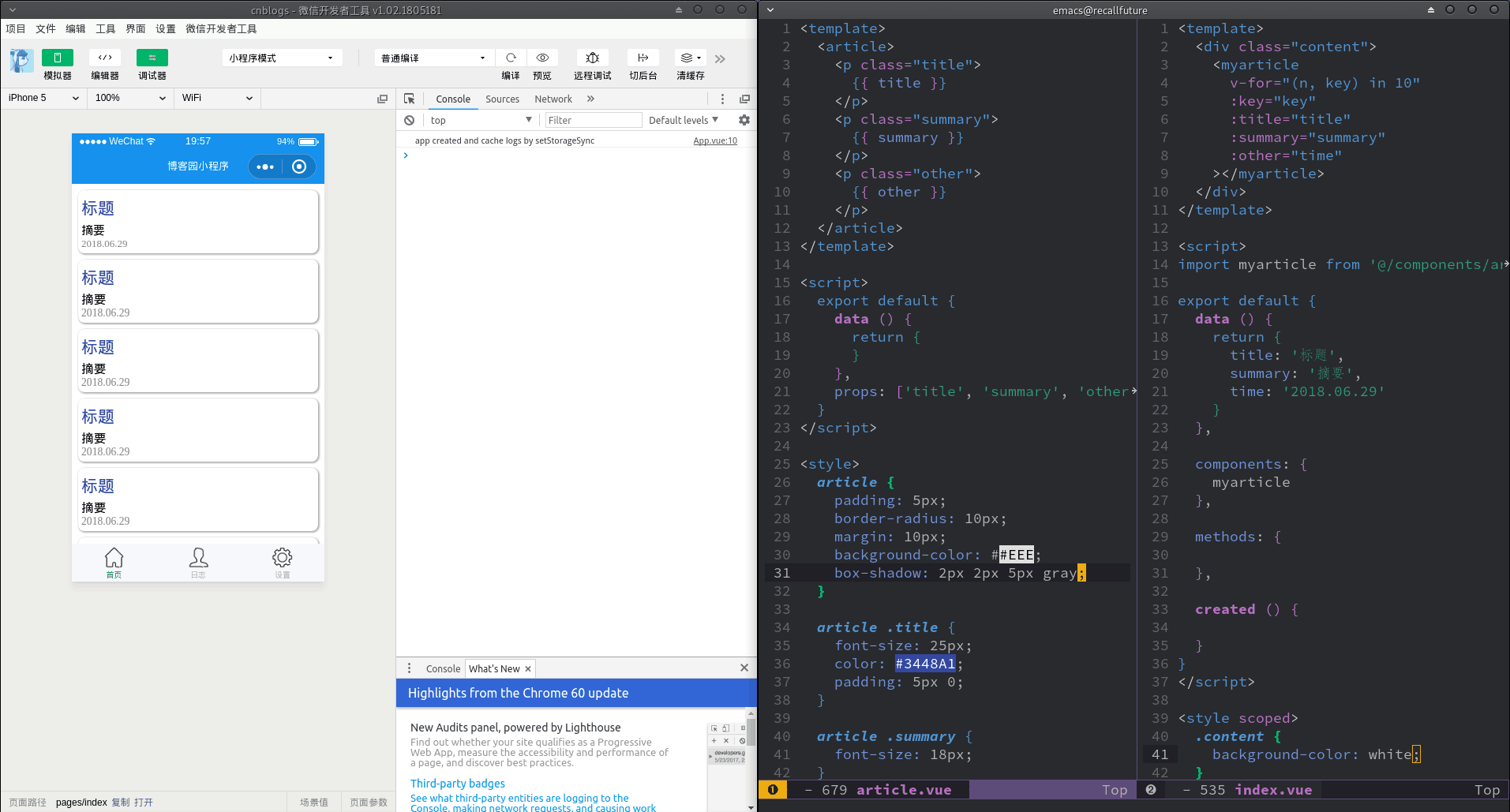
列表页面主要需要一个个的条目,我将这个做成了一个组件,方便主页面调用。
主页面将获取到的数据做成数组,数组中的每一个都是一个组件需要的内容, 用v-for循环创建组件即可。
1.3 xml数据解析
那么重头戏就是这里了,如何从xml中提取到需要的信息。这里用到了xmldom, js解析xml的库。
说实话,这个用着很蛋疼,但看好多人都在推荐这个,我也就信了
信了他的邪,,
实际证明,必须要好好看文档和实例,然后console.log出数据整体结构之后才算能用, 比如说假如现在获取到的xml是这样的(为了美观我给他格式化了,原本都在一行里)
<?xml version="1.0" encoding="utf-8"?> <feed xmlns="http://www.w3.org/2005/Atom"> <title type="text">博客园</title> <id>uuid:93cb2bb2-d28c-43d3-80dc-033331d5c529;id=132187</id> <updated>2018-06-29T16:36:42Z</updated> <link href="http://www.cnblogs.com/"/> <entry> <id>9241216</id> <title type="text">.NET Core微服务之基于Ocelot+Butterfly实现分布式追踪</title> <summary type="text">本篇首先介绍了一下追踪()的背景以及基本概念,然后介绍了一下一个开源的分布式追踪组件y,由于已经集成了y,所以我们可以很方便地在中使用y进行追踪。最后,通过一个具体的小实例,介绍了如何在微服</summary> <published>2018-06-30T00:25:00+08:00</published> <updated>2018-06-29T16:36:42Z</updated> <author> <name>Edison Chou</name> <uri>http://www.cnblogs.com/edisonchou/</uri> <avatar>http://pic.cnblogs.com/face/381412/20161204141727.png</avatar> </author> <link rel="alternate" href="http://www.cnblogs.com/edisonchou/p/ocelot_and_butterfly_tracing_foundation.html"/> <blogapp>edisonchou</blogapp> <diggs>0</diggs> <views>10</views> <comments>0</comments> </entry> </feed>
我需要获取的信息有:
- title
- summary
- published
- name
- link的href
调试许久后,代码是这样的
var doc = new DOMParser().parseFromString(res.data, 'text/xml') var entry = doc.getElementsByTagName('entry') var title = entry[0].getElementsByTagName('title')[0]['firstChild']['data'] var summary = entry[0].getElementsByTagName('summary')[0]['firstChild']['data'] var author = entry[0].getElementsByTagName('author')[0].getElementsByTagName('name')[0]['firstChild']['data'] var published = entry[0].getElementsByTagName('published')[0]['firstChild']['data'] var link = entry[0].getElementsByTagName('link')[0].getAttribute('href')
我是崩溃的
不过总算是获取到了需要的信息,接下来需要将这些动态的存入数组里, 由于上面的代码我是写到了mothods中的一个方法里,而数组是在data里存放的, 于是我就直接用this.items.push(…),然而失败了
this是空的,查找解决方法许久,无解,于是用了笨办法,把数组传参进去, 用这个参数来修改数组的内容。
到现在,列表正常的显示我获取到的信息了,满满的心酸
2 第二天
2.1 寻找更好的xml解析方案
在经历了昨天xml的折磨后,今天的首要目标就是找到更好用的xml解析库, 所以我对这个xml的格式进行了分析,发现这其实是rss订阅的xml格式。
知道这个那就好办了,在github搜索了一会,找到了个看起来不错的库, rss-parser,将xml字符串扔进去,出来的就是我需要的数据。
起码看上去是这么美好。
随后就是用npm安装这个,在页面里按照示例调用,顺便console.log一下那个 返回给我的数据结构,然而编译过后,小程序那边又出问题了,这次是无法调用到 那个对象里面的数据,从控制台看到的数据结构是这样的:
{xxxxx}: object {…}
[[xxxxType]]: object {…}
[[xxxxValue]]: object {//这里是我想要的数据}
然而无论我用什么办法,都没法调用到这里的带中括号的对象名,,虽然数据的确就在里面了, 我却无能为力,最后只能放弃,可能这个不适合在小程序上面用吧。
折腾这么多,想回到之前的样子也很麻烦了,不过幸好昨晚用git存了档,git reset回到上一个git存档处, 一切又回到了昨晚的模样。
2.2 下拉刷新和上拉加载
接下来做了点力所能及的事,完成下拉刷新和上拉加载,这里需要用到小程序的api。
首先,需要在app.json中的window里添加:
"enablePullDownRefresh": true
然后,需要在页面中加入两个回调函数:
onPullDownRefresh () { //下拉时候调用的函数 } onReachBottom () { //向上拉到底部时候调用的函数 }
加载时候的菊花动画需要用到下面的两个函数:
// 显示加载图标 wx.showLoading({ title: '玩命加载中', }) // 隐藏加载框 wx.hideLoading();
下拉刷新的逻辑是:每次下拉,获取最新的10条数据,然后逐个对比id,id不相同的话,将这个插入到列表里, 相同的话,就停止加载。
上拉加载的逻辑是:不停获取下一页的数据,并依次放到列表末尾,每一次加载完,页数加一。
3 第三天
因事其他事暂时搁置此任务,(其实是因为搞不起域名备案),总之等以后再说吧。
先在这里写一下计划
- 由列表页面跳转到详情页,步骤是先下载网页,然后在详情页显示,插件用适用于 Mpvue 的微信小程序富文本解析自定义组件。
- 加入新页面——根据关键词搜索文章