一.爬取目标
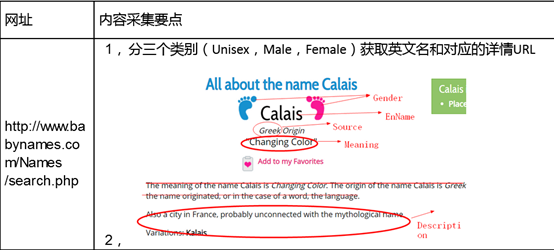
网址:http://www.babynames.com/Names/search.php
任务:分三个类别(Unisex,Male,Female)获取英文名的详情信息(Gender,EnName,Souce,Meaning,Description及详情URL)
二.爬取思路
1.首先在主页获取A-Z的html并保存到本地
2.然后创建三个文件夹,把Unisex,Male,Female的婴儿名区分开
3.再获取每个英文名的详情url
4.获取信息详情
5.根据性别不同存到不同的文件里
三. 运用的技术:
1:requests 模块请求,加headers
2:re 正则模块 基本只是用了简单的 .*?
3:bs4 中的BeautifulSoup 运用了其中的类选择器
4:lxml 中的 etree方法
5:os 模块中的 判断文件是否存在方法
6:csv 模块的存入和读取
四.代码 略
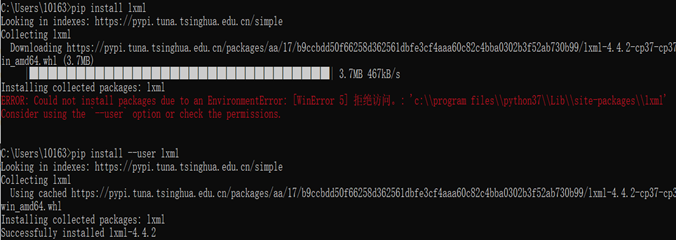
(1)No module named 'lxml',用pip install lxml无法下载
解决方案: 换成pip install --user lxml
(2)爬取个人信息性别的时候一直提示错误
原因:每个个人信息性别的属性是不一样的


所以这个时候需要一个判断语句来获取性别
Gender = soup.find_all("a", class_="logopink") #此处匹配分三种情况 因为分为男女 还有中性的 if Gender : pattern = re.compile('<a class="logopink" href=".*?">(.*?)</a>') Gender = pattern.findall(str(Gender[0]))[0] elif soup.find_all("a", class_="logoblue"): Gender = soup.find_all("a", class_="logoblue") pattern = re.compile('<a class="logoblue" href=".*?">(.*?)</a>') Gender = pattern.findall(str(Gender[0]))[0] else: Gender = soup.find_all("a", class_="logogreen") pattern = re.compile('<a class="logogreen" href=".*?">(.*?)</a>') Gender = pattern.findall(str(Gender[0]))[0]
六.运行结果及csv文件