【GiantPandaCV导语】混合精度是一个非常简单并且实用的技术,由百度和谷歌联合发表于ICLR2018,可以让模型以半精度的方式训练模型,既能够降低显存占用,又可以保持精度。这篇文章不是最先提出使用更低精度来进行训练,但是其影响力比较深远,很多现在的方案都是基于这篇文章设计的。
1. 摘要
提高网络模型的大小可以有效提升准确了,但是也增加了内存的压力和计算力的需求。本论文引入了半精度来训练深度神经网络,在不损失精度、不需要更改超参数的情况下,几乎可以减半内存占用。
权重、激活、梯度都是以IEEE半精度的方式存储的,由于半精度的表示范围要比单精度要小,本文提出了三种方法来防止关键信息的丢失。
- 推荐维护一个单精度版本的权重weights,用于累积梯度。
- 提出使用Loss scale来保证小的梯度值不会下溢出。
- 在加载到内存之前,就将模型转化到半精度来进行加速。
2. 介绍
大的模型往往需要更多的计算量、更多的内存资源来训练,如果想要降低使用的资源,可以通过降低精度的方法。通常情况下,一个程序运行速度的快慢主要取决于三个因素:
- 算法带宽
- 内存带宽
- 时延
使用半精度减少了一半bit,可以影响算法带宽和内存带宽,好处有:
- 由于是用更少的bit代替,占用空间会减小差不多一半
- 对于处理器来说也是一个好消息,使用半精度可以提高处理器吞吐量;在当时的GPU上,半精度的吞吐量可以达到单精度的2-8倍。
现在大部分深度学习训练系统使用单精度FP32的格式进行存储和训练。本文采用了IEEE的半精度格式(FP16)。但是由于FP16可以表示的范围要比FP32更为狭窄,所以引入了一些技术来规避模型的精度损失。
- 保留一份FP32的主备份。
- 使用loss scale来避免梯度过小。
- FP16计算但是用FP32进行累加。
3. 实现

下面详细讲解第二节提到的三种技术。
3.1 FP32的主备份

在混合精度训练中,权重、激活、梯度都采用的是半精度存储的。为了匹配单精度网络的精度,在优化的整个过程中,需要拷贝一份单精度模型FP32作为主备份,而训练过程中使用的是FP16进行计算。
这样做的原因有两个:
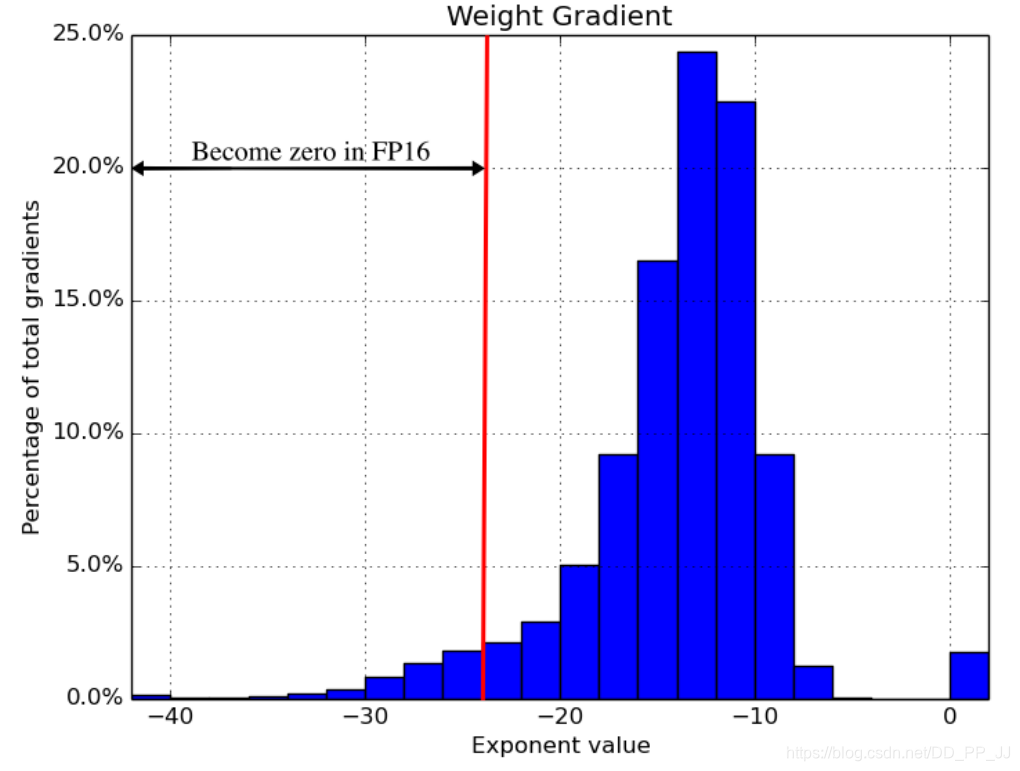
第一:溢出错误:更新的时候是学习率乘以梯度,这个值可能非常小,超过半精度最小范围((2^{-24})),就会导致下溢出。如下图展示了梯度和FP16的表示范围,大约有5%的梯度已经下溢出,如果直接对半精度表示的模型更新,这样模型的精度肯定有所损失;而对单精度的模型进行更新,就就可以规避下溢出的问题。
- 第二:舍入误差:指的是当梯度过小,小于当前区间内的最小间隔,那么梯度更新可能会失败。想要详细了解可以自行查看wiki上的详解。同样的,使用FP32单精度可以尽可能减少舍入误差的影响。

3.2 Loss Scale
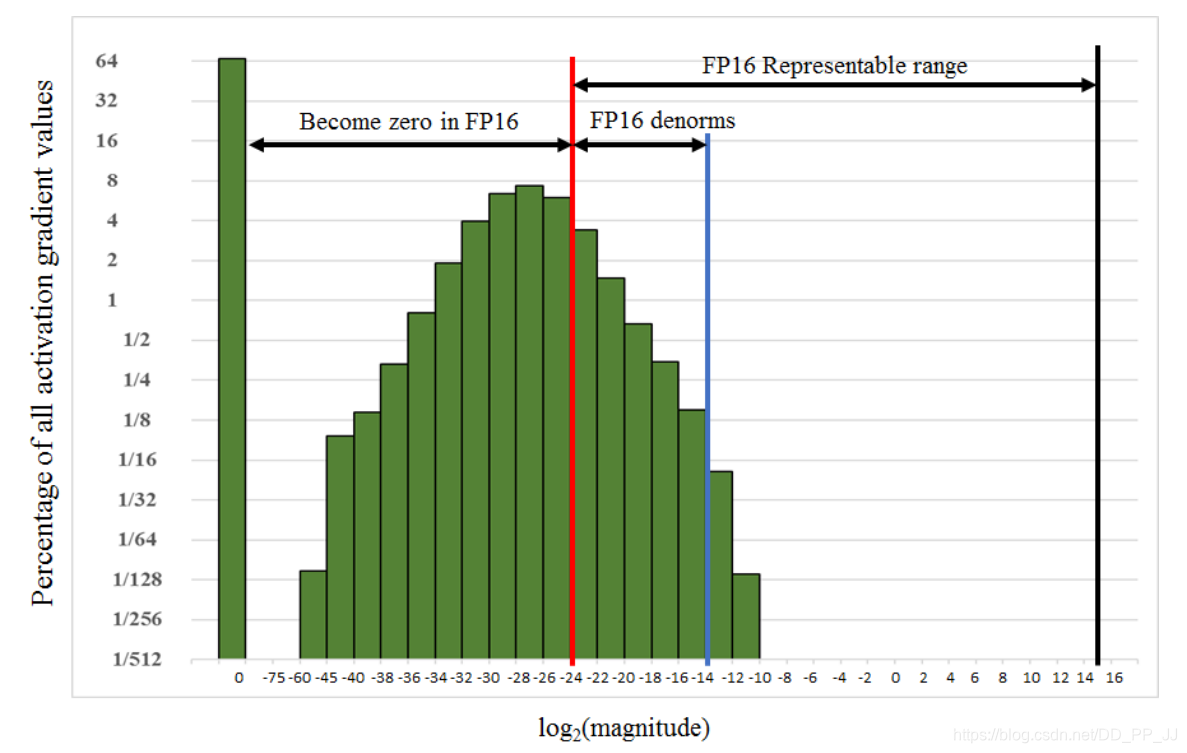
下图展示的是激活值的范围和FP16表示范围之间的差异,50%以上的值都集中在不可表示的范围中,而右侧FP16可表示范围却空荡荡的,那么一个简单的想法就是向右平移,将激活平移到FP16可表示范围内。比如说可以将激活乘以8,这样可以平移3位,这样表示最低范围就从(2^{-24})到了(2^{-27}), 因为激活值低于(2^{-27})的部分对模型训练来说不重要,所以这样操作就可以达到FP32的精度。
那实际上是如何实现平移呢?很简单,就是在loss基础上乘以一个很大的系数loss scale, 那么由于链式法则,可以确保梯度更新的时候也采用相同的尺度进行缩放,最后在更新梯度之前再除以loss scale, 对FP32的单精度备份进行更新,就完成了。
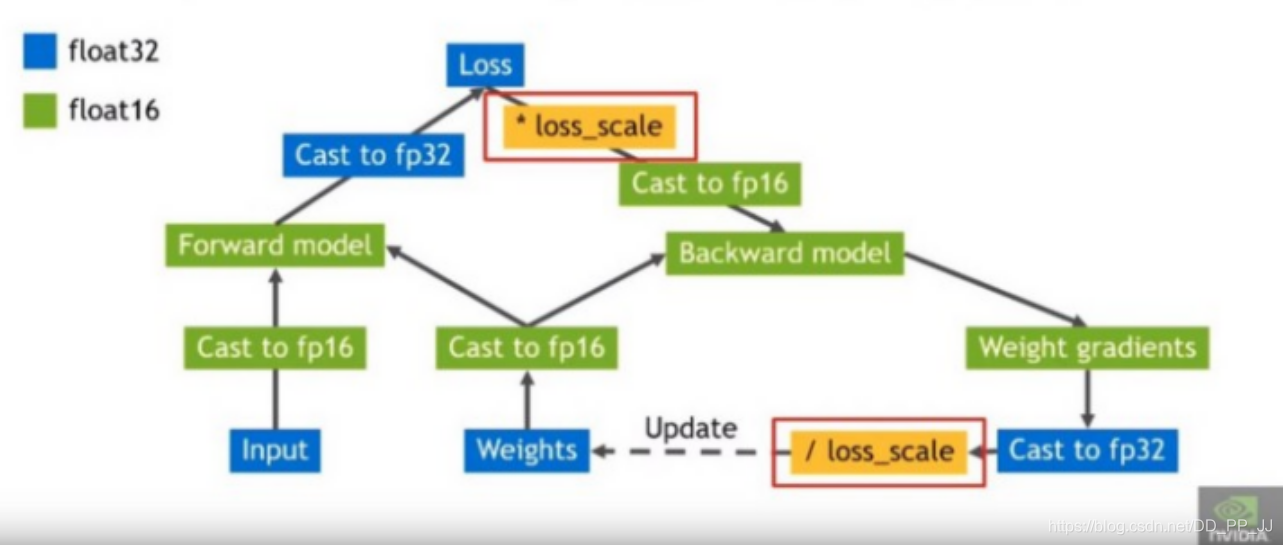
还有一个问题,就是loss scale值的选取,最简单的方法就是选择一个固定值作为loss scale,可以训练一系列网络缩放因子的设置可以从8到32k。固定的放缩因子选取是需要一定经验的,如果梯度的数据可以获取,那就选取一个值可以让其梯度的值小于65504(FP16可以表示的最大值)。如果选取loss scale值过大,可能会上溢出,这种情况可以通过检查梯度来判断,如果发生溢出,跳过权重更新,进行下一次迭代。
3.3 运算精度
在神经网络中的运算可以划分为三类:向量点乘(dot-products)、reduction和逐点操作。这三种操作在遇到半精度的时候,会有不同的处理方法。
为了保持模型精度,需要将向量点乘的部分乘积累加为FP32,然后再转换为FP16。如果直接用FP16会导致精度损失,不能达到和原来一样的精度。现在很多支持Tensor Cores的GPU中已经实现了这样的操作。
Reduction操作(比如求很多向量元素的和)需要先转为FP32, 这样的操作大部分出现在batch norm或者softmax层中。这两个层都是从内存中读写FP16的向量,执行运算的时候要使用FP32格式。
逐点操作,如非线性和元素间矩阵乘法,内存占用有限,运算精度不影响这些操作的速度。
4. 结果
在分类任务(ILSVRC/ImageNet)、检测任务(VOC2007)、语音识别(English-Mandarin)、机器翻译(English-Frech)、语言模型(1 billion word)、DCGAN这几个任务进行了实验,这篇解读仅展示分类任务和检测任务的结果。
实验的时候每个任务都会设置一个两个对比试验
- Baseline (FP32): 单精度的激活、权重、梯度得到的模型,运算使用的也是FP32。
- Mixed Precision(MP): FP16用来存储和数值运算;权重、激活、梯度都是用的是FP16,其中主备份权重是FP32的。在一些任务中使用了Loss-scaling的技术。运算过程中使用Tensor Cores将累加过程(卷积层、全连接层、矩阵相乘)转为FP32来计算。
4.1 分类
分类任务上选择了AlexNet、Vgg-D、GoogLeNet、Inceptionv2、Inceptionv3 和 预激活ResNet50几个模型进行测试,主要满足以下条件:
- 使用相同的超参数比较top-1 准确率。
- 训练方法采用的是开源库中默认的方法。
- 数据增强方法使用的是最简单的,并没有采用开源库中复杂的方法。主要包括:
- 随机水平翻转
- 随机剪裁crop
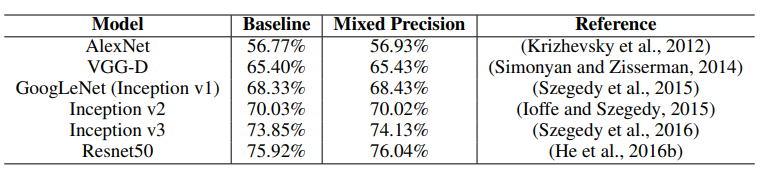
可以看到Mixed Precision方法能够和Baseline方法差不多准确率,有时候甚至会略高于Baseline。
在训练以上网络的时候,不需要使用Loss Scale方法,因为这些方法前向传播和反向传播的值都在FP16范围内。
4.2 检测
这里选择了Faster RCNN和Multibox-SSD两种方法在VOC2007数据集上进行训练,两个方法都是用来VGG-16作为骨干网络。模型和训练脚本都来自于开源库。

可以看到,如果使用Mixed Precision方法,在训练Multibox SSD的时候可能会由于下溢出导致模型不收敛,但是当使用了Loss Scale技术以后,就可以正常收敛,达到与Baseline相同的结果。
5. 总结
Mixed Precision混合精度是处于一个非常简单的想法,使用低精度的表示可以节约显存、内存同时增加处理器的吞吐量。虽然有以上的种种好处,直接使用半精度会出现一定的问题,比如:下溢出、精度损失等。所以这篇论文核心就是解决使用半精度过程中出现的问题,提出了三个方法达到了非常理想的效果。如果你使用的是有Tensor Core的GPU,那就非常推荐使用混合精度来训练,只需要安装NVIDIA提供的Apex库,然后在你的PyTorch or TensorFlow代码中加几行代码就可以实现。
6. 参考
https://arxiv.org/pdf/1710.03740v3