Spark sql 对SQL语句的处理,先将SQL语句进行解析(parse)形成一个tree,然后使用Rule对Tree进行绑定,优化等处理过程,通过模式匹配对不同类型的节点采用不同操作。查询优化器是Catalyst,它负责处理查询语句的解析,绑定,优化和生成物理计划等过程,Catalyst是Spark SQL最核心的部分,其性能优劣将决定整体的性能。
spark SQL由Core,Catalyst,hive和hive-thriftserver 4个部分组成:
core 负责数据的输入输出,从不同数据源获得数据(rdd,parquet,json等),然后将查询结果输出成dataframe
catalyst 负责处理查询语句的整体处理过程,包括解析,绑定,优化(Optimize),物理计划等
hive 负责对hive数据处理
hive-thriftserver 提供CLI和jdbc/odbc接口
Tree是Catalyst执行计划表示的数据结构。LogicalPlans,Expressions和Pysical Operators都可以使用Tree来表示。Tree具备一些Scala Collection的操作能力和树遍历能力。
Tree提供三种特质(trait):
- UnaryNode:一元节点,即只有一个子节点
- BinaryNode:二元节点,即有左右子节点的二叉节点
- LeafNode:叶子节点,没有子节点的节点
Tree有两个子类继承体系,即QueryPlan和Expression
QueryPlan下面的两个子类分别是LogicalPlan(逻辑执行计划)和SparkPlan(物理执行计划)。
Expression是表达式体系,是指不需要执行引擎计算,而可以直接计算或处理的节点,包括Cast操作、Porjection操作、四则运算和逻辑操作符运算等等。
Rule[TreeType <: TreeNode[_]]是一个抽象类,子类需要复写apply(plan: TreeType)方法来指定处理逻辑。对于Rule的具体实现是通过RuleExecutor完成的,凡是需要处理执行计划树进行实施规则匹配和节点处理的,都需要继承RuleExecutor[TreeType]抽象类。
spark sql 运行架构图
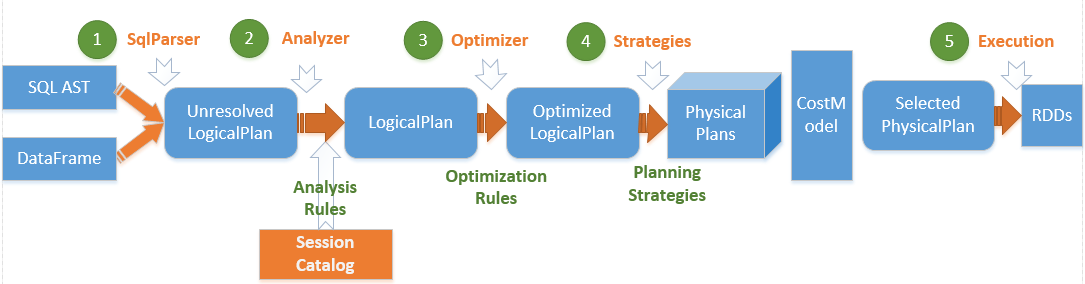
(1)、将SQL语句通过词法和语法解析生成未绑定的逻辑计划(包含Unresolved Relation、Unresolved Function和Unresolved Attribute),然后在后续步骤中使用不同的Rule应用到该逻辑计划上。
(2)、Analyzer使用Analysis Rules,配合数据元数据(如SessionCatalog或Hive Metastore),完善未绑定的逻辑计划的属性而转换成已绑定的逻辑计划。
具体的流程是:先实例化一个Simple Analyzer,然后遍历预先定义好的Batch,通过父类的Rule Exector的执行方法运行Batch里面的Rules,每个Rule会对未绑定的逻辑计划进行处理,有些可以通过一次解析处理,有些需要多次迭代,迭代至FixedPoint次数迭代或达到前后两次的树结构没有变化时停止。
(3)、Optimizer使用Optimization Rules,将绑定的逻辑计划进行合并、列裁剪、过滤器下推等优化工作后生成优化的逻辑计划。
(4)、Planner使用Planning Strategies,对优化的逻辑计划进行转换(Transform)生成可以执行的逻辑计划。根据过去的性能统计数据,选择最佳的物理执行计划CostModel,最后可以执行的物理计划树,即得到SparkPlan。
(5)、在最终真正执行物理执行计划前,还要进行preparations规则处理,最后调用SparkPlan的execute执行计算RDD。
在解析SQL语句之前需要初始化SQLContext,它定义了Spark SQL执行的上下文,并把元数据保存在SessionCatalog中,这些元数据包括表名称、表字段名称和字段类型等。